 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranscoder-based Circuit Analysis for Interpretable Single-Cell Foundation Models
Sep 18, 2025Single-cell foundation models (scFMs) have demonstrated state-of-the-art performance on various tasks, such as cell-type annotation and perturbation response prediction, by learning gene regulatory networks from large-scale transcriptome data. However, a significant challenge remains: the decision-making processes of these models are less interpretable compared to traditional methods like differential gene expression analysis. Recently, transcoders have emerged as a promising approach for extracting interpretable decision circuits from large language models (LLMs). In this work, we train a transcoder on the cell2sentence (C2S) model, a state-of-the-art scFM. By leveraging the trained transcoder, we extract internal decision-making circuits from the C2S model. We demonstrate that the discovered circuits correspond to real-world biological mechanisms, confirming the potential of transcoders to uncover biologically plausible pathways within complex single-cell models.
CAG-VLM: Fine-Tuning of a Large-Scale Model to Recognize Angiographic Images for Next-Generation Diagnostic Systems
May 08, 2025Coronary angiography (CAG) is the gold-standard imaging modality for evaluating coronary artery disease, but its interpretation and subsequent treatment planning rely heavily on expert cardiologists. To enable AI-based decision support, we introduce a two-stage, physician-curated pipeline and a bilingual (Japanese/English) CAG image-report dataset. First, we sample 14,686 frames from 539 exams and annotate them for key-frame detection and left/right laterality; a ConvNeXt-Base CNN trained on this data achieves 0.96 F1 on laterality classification, even on low-contrast frames. Second, we apply the CNN to 243 independent exams, extract 1,114 key frames, and pair each with its pre-procedure report and expert-validated diagnostic and treatment summary, yielding a parallel corpus. We then fine-tune three open-source VLMs (PaliGemma2, Gemma3, and ConceptCLIP-enhanced Gemma3) via LoRA and evaluate them using VLScore and cardiologist review. Although PaliGemma2 w/LoRA attains the highest VLScore, Gemma3 w/LoRA achieves the top clinician rating (mean 7.20/10); we designate this best-performing model as CAG-VLM. These results demonstrate that specialized, fine-tuned VLMs can effectively assist cardiologists in generating clinical reports and treatment recommendations from CAG images.
Video CLIP Model for Multi-View Echocardiography Interpretation
Apr 26, 2025Echocardiography involves recording videos of the heart using ultrasound, enabling clinicians to evaluate its condition. Recent advances in large-scale vision-language models (VLMs) have garnered attention for automating the interpretation of echocardiographic videos. However, most existing VLMs proposed for medical interpretation thus far rely on single-frame (i.e., image) inputs. Consequently, these image-based models often exhibit lower diagnostic accuracy for conditions identifiable through cardiac motion. Moreover, echocardiographic videos are recorded from various views that depend on the direction of ultrasound emission, and certain views are more suitable than others for interpreting specific conditions. Incorporating multiple views could potentially yield further improvements in accuracy. In this study, we developed a video-language model that takes five different views and full video sequences as input, training it on pairs of echocardiographic videos and clinical reports from 60,747 cases. Our experiments demonstrate that this expanded approach achieves higher interpretation accuracy than models trained with only single-view videos or with still images.
Application of Contrastive Learning on ECG Data: Evaluating Performance in Japanese and Classification with Around 100 Labels
Apr 12, 2025The electrocardiogram (ECG) is a fundamental tool in cardiovascular diagnostics due to its powerful and non-invasive nature. One of the most critical usages is to determine whether more detailed examinations are necessary, with users ranging across various levels of expertise. Given this diversity in expertise, it is essential to assist users to avoid critical errors. Recent studies in machine learning have addressed this challenge by extracting valuable information from ECG data. Utilizing language models, these studies have implemented multimodal models aimed at classifying ECGs according to labeled terms. However, the number of classes was reduced, and it remains uncertain whether the technique is effective for languages other than English. To move towards practical application, we utilized ECG data from regular patients visiting hospitals in Japan, maintaining a large number of Japanese labels obtained from actual ECG readings. Using a contrastive learning framework, we found that even with 98 labels for classification, our Japanese-based language model achieves accuracy comparable to previous research. This study extends the applicability of multimodal machine learning frameworks to broader clinical studies and non-English languages.
JRadiEvo: A Japanese Radiology Report Generation Model Enhanced by Evolutionary Optimization of Model Merging
Nov 15, 2024With the rapid advancement of large language models (LLMs), foundational models (FMs) have seen significant advancements. Healthcare is one of the most crucial application areas for these FMs, given the significant time and effort required for physicians to analyze large volumes of patient data. Recent efforts have focused on adapting multimodal FMs to the medical domain through techniques like instruction-tuning, leading to the development of medical foundation models (MFMs). However, these approaches typically require large amounts of training data to effectively adapt models to the medical field. Moreover, most existing models are trained on English datasets, limiting their practicality in non-English-speaking regions where healthcare professionals and patients are not always fluent in English. The need for translation introduces additional costs and inefficiencies. To address these challenges, we propose a \textbf{J}apanese \textbf{Radi}ology report generation model enhanced by \textbf{Evo}lutionary optimization of model merging (JRadiEvo). This is the first attempt to extend a non-medical vision-language foundation model to the medical domain through evolutionary optimization of model merging. We successfully created a model that generates accurate Japanese reports from X-ray images using only 50 translated samples from publicly available data. This model, developed with highly efficient use of limited data, outperformed leading models from recent research trained on much larger datasets. Additionally, with only 8 billion parameters, this relatively compact foundation model can be deployed locally within hospitals, making it a practical solution for environments where APIs and other external services cannot be used due to strict privacy and security requirements.
70B-parameter large language models in Japanese medical question-answering
Jun 21, 2024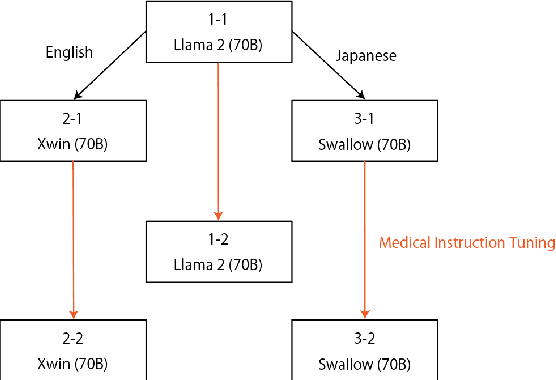
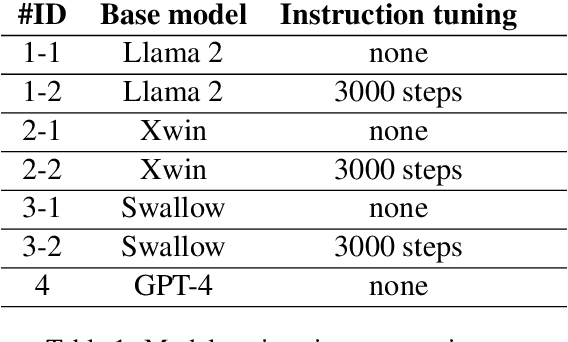
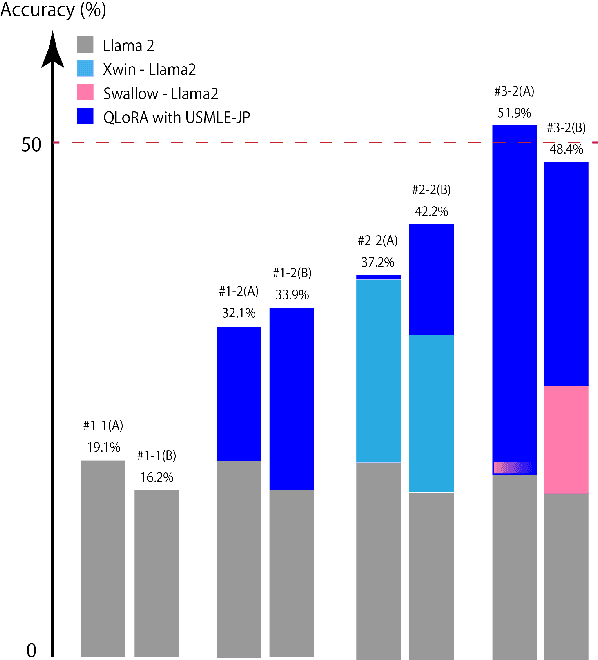
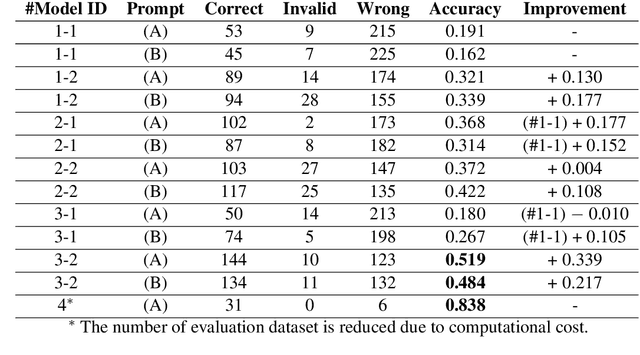
Since the rise of large language models (LLMs), the domain adaptation has been one of the hot topics in various domains. Many medical LLMs trained with English medical dataset have made public recently. However, Japanese LLMs in medical domain still lack its research. Here we utilize multiple 70B-parameter LLMs for the first time and show that instruction tuning using Japanese medical question-answering dataset significantly improves the ability of Japanese LLMs to solve Japanese medical license exams, surpassing 50\% in accuracy. In particular, the Japanese-centric models exhibit a more significant leap in improvement through instruction tuning compared to their English-centric counterparts. This underscores the importance of continual pretraining and the adjustment of the tokenizer in our local language. We also examine two slightly different prompt formats, resulting in non-negligible performance improvement.
JMedLoRA:Medical Domain Adaptation on Japanese Large Language Models using Instruction-tuning
Oct 16, 2023In the ongoing wave of impact driven by large language models (LLMs) like ChatGPT, the adaptation of LLMs to medical domain has emerged as a crucial research frontier. Since mainstream LLMs tend to be designed for general-purpose applications, constructing a medical LLM through domain adaptation is a huge challenge. While instruction-tuning is used to fine-tune some LLMs, its precise roles in domain adaptation remain unknown. Here we show the contribution of LoRA-based instruction-tuning to performance in Japanese medical question-answering tasks. In doing so, we employ a multifaceted evaluation for multiple-choice questions, including scoring based on "Exact match" and "Gestalt distance" in addition to the conventional accuracy. Our findings suggest that LoRA-based instruction-tuning can partially incorporate domain-specific knowledge into LLMs, with larger models demonstrating more pronounced effects. Furthermore, our results underscore the potential of adapting English-centric models for Japanese applications in domain adaptation, while also highlighting the persisting limitations of Japanese-centric models. This initiative represents a pioneering effort in enabling medical institutions to fine-tune and operate models without relying on external services.