 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJRadiEvo: A Japanese Radiology Report Generation Model Enhanced by Evolutionary Optimization of Model Merging
Nov 15, 2024With the rapid advancement of large language models (LLMs), foundational models (FMs) have seen significant advancements. Healthcare is one of the most crucial application areas for these FMs, given the significant time and effort required for physicians to analyze large volumes of patient data. Recent efforts have focused on adapting multimodal FMs to the medical domain through techniques like instruction-tuning, leading to the development of medical foundation models (MFMs). However, these approaches typically require large amounts of training data to effectively adapt models to the medical field. Moreover, most existing models are trained on English datasets, limiting their practicality in non-English-speaking regions where healthcare professionals and patients are not always fluent in English. The need for translation introduces additional costs and inefficiencies. To address these challenges, we propose a \textbf{J}apanese \textbf{Radi}ology report generation model enhanced by \textbf{Evo}lutionary optimization of model merging (JRadiEvo). This is the first attempt to extend a non-medical vision-language foundation model to the medical domain through evolutionary optimization of model merging. We successfully created a model that generates accurate Japanese reports from X-ray images using only 50 translated samples from publicly available data. This model, developed with highly efficient use of limited data, outperformed leading models from recent research trained on much larger datasets. Additionally, with only 8 billion parameters, this relatively compact foundation model can be deployed locally within hospitals, making it a practical solution for environments where APIs and other external services cannot be used due to strict privacy and security requirements.
70B-parameter large language models in Japanese medical question-answering
Jun 21, 2024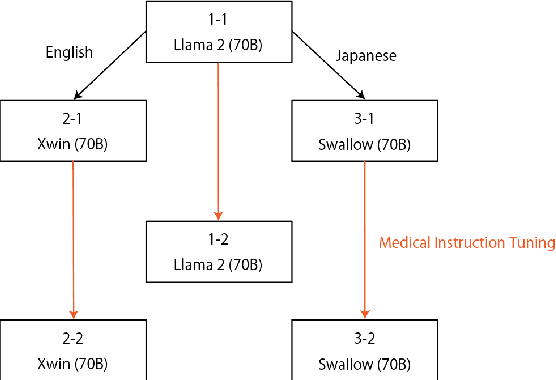
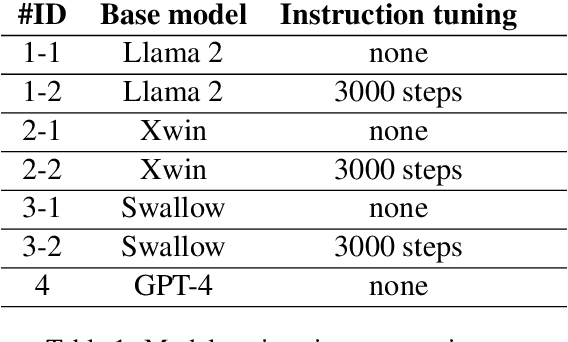
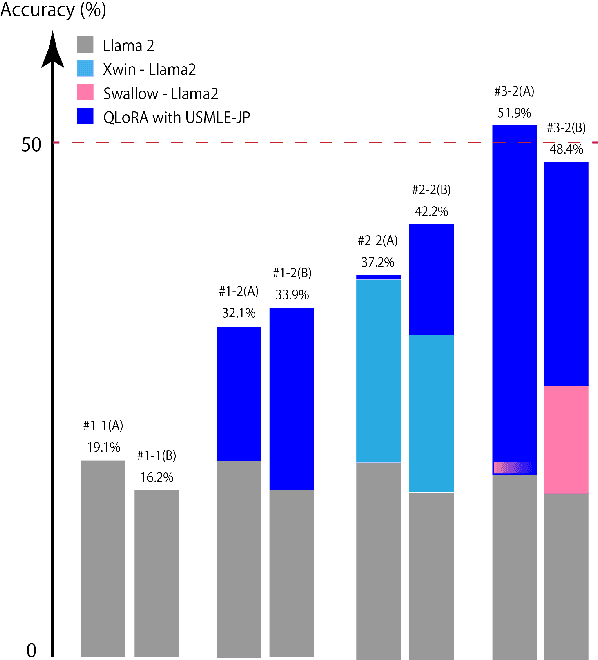
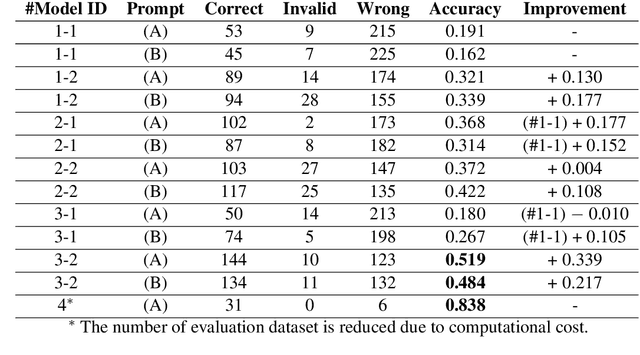
Since the rise of large language models (LLMs), the domain adaptation has been one of the hot topics in various domains. Many medical LLMs trained with English medical dataset have made public recently. However, Japanese LLMs in medical domain still lack its research. Here we utilize multiple 70B-parameter LLMs for the first time and show that instruction tuning using Japanese medical question-answering dataset significantly improves the ability of Japanese LLMs to solve Japanese medical license exams, surpassing 50\% in accuracy. In particular, the Japanese-centric models exhibit a more significant leap in improvement through instruction tuning compared to their English-centric counterparts. This underscores the importance of continual pretraining and the adjustment of the tokenizer in our local language. We also examine two slightly different prompt formats, resulting in non-negligible performance improvement.