 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompression Scaling Laws:Unifying Sparsity and Quantization
Paper and Code
Feb 23, 2025
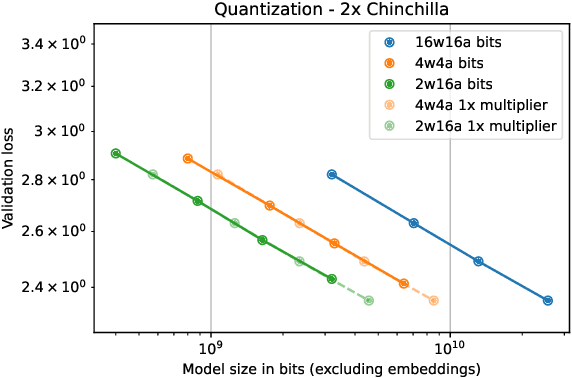
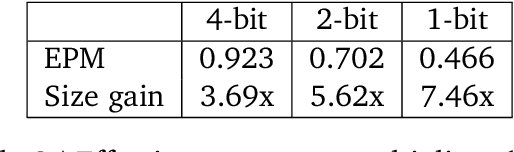
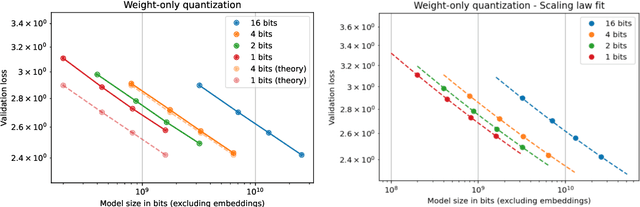
We investigate how different compression techniques -- such as weight and activation quantization, and weight sparsity -- affect the scaling behavior of large language models (LLMs) during pretraining. Building on previous work showing that weight sparsity acts as a constant multiplier on model size in scaling laws, we demonstrate that this "effective parameter" scaling pattern extends to quantization as well. Specifically, we establish that weight-only quantization achieves strong parameter efficiency multipliers, while full quantization of both weights and activations shows diminishing returns at lower bitwidths. Our results suggest that different compression techniques can be unified under a common scaling law framework, enabling principled comparison and combination of these methods.