 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing RNN-Transducer to Out-Domain Audio via Sparse Self-Attention Layers
Aug 22, 2021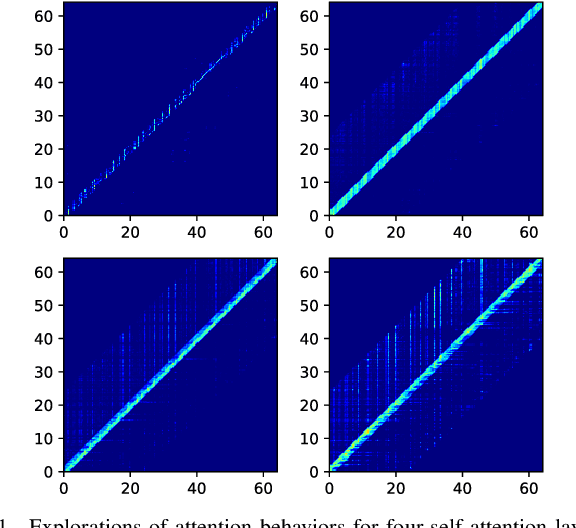
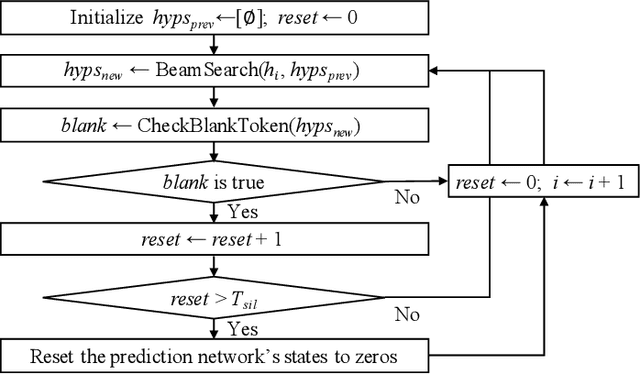
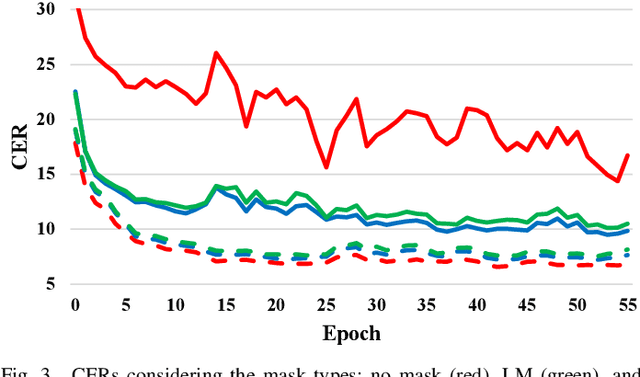

Recurrent neural network transducers (RNN-T) are a promising end-to-end speech recognition framework that transduces input acoustic frames into a character sequence. The state-of-the-art encoder network for RNN-T is the Conformer, which can effectively model the local-global context information via its convolution and self-attention layers. Although Conformer RNN-T has shown outstanding performance (measured by word error rate (WER) in general), most studies have been verified in the setting where the train and test data are drawn from the same domain. The domain mismatch problem for Conformer RNN-T has not been intensively investigated yet, which is an important issue for the product-level speech recognition system. In this study, we identified that fully connected self-attention layers in the Conformer caused high deletion errors, specifically in the long-form out-domain utterances. To address this problem, we introduce sparse self-attention layers for Conformer-based encoder networks, which can exploit local and generalized global information by pruning most of the in-domain fitted global connections. Further, we propose a state reset method for the generalization of the prediction network to cope with long-form utterances. Applying proposed methods to an out-domain test, we obtained 24.6\% and 6.5\% relative character error rate (CER) reduction compared to the fully connected and local self-attention layer-based Conformers, respectively.
Ensemble of Jointly Trained Deep Neural Network-Based Acoustic Models for Reverberant Speech Recognition
Aug 17, 2016

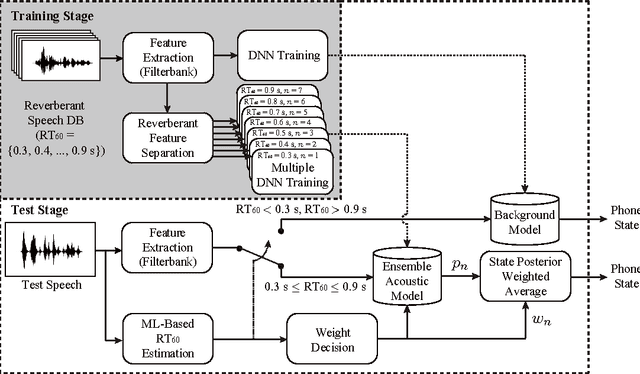
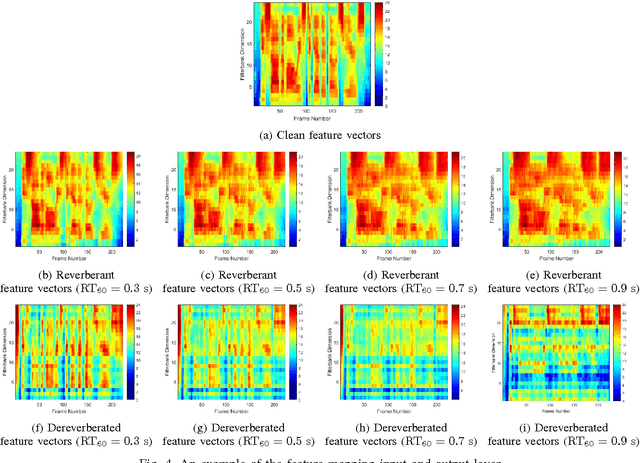
Distant speech recognition is a challenge, particularly due to the corruption of speech signals by reverberation caused by large distances between the speaker and microphone. In order to cope with a wide range of reverberations in real-world situations, we present novel approaches for acoustic modeling including an ensemble of deep neural networks (DNNs) and an ensemble of jointly trained DNNs. First, multiple DNNs are established, each of which corresponds to a different reverberation time 60 (RT60) in a setup step. Also, each model in the ensemble of DNN acoustic models is further jointly trained, including both feature mapping and acoustic modeling, where the feature mapping is designed for the dereverberation as a front-end. In a testing phase, the two most likely DNNs are chosen from the DNN ensemble using maximum a posteriori (MAP) probabilities, computed in an online fashion by using maximum likelihood (ML)-based blind RT60 estimation and then the posterior probability outputs from two DNNs are combined using the ML-based weights as a simple average. Extensive experiments demonstrate that the proposed approach leads to substantial improvements in speech recognition accuracy over the conventional DNN baseline systems under diverse reverberant conditions.