 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent-Level Enhancement with Flow Matching for Robust Automatic Speech Recognition
Jan 08, 2026Noise-robust automatic speech recognition (ASR) has been commonly addressed by applying speech enhancement (SE) at the waveform level before recognition. However, speech-level enhancement does not always translate into consistent recognition improvements due to residual distortions and mismatches with the latent space of the ASR encoder. In this letter, we introduce a complementary strategy termed latent-level enhancement, where distorted representations are refined during ASR inference. Specifically, we propose a plug-and-play Flow Matching Refinement module (FM-Refiner) that operates on the output latents of a pretrained CTC-based ASR encoder. Trained to map imperfect latents-either directly from noisy inputs or from enhanced-but-imperfect speech-toward their clean counterparts, the FM-Refiner is applied only at inference, without fine-tuning ASR parameters. Experiments show that FM-Refiner consistently reduces word error rate, both when directly applied to noisy inputs and when combined with conventional SE front-ends. These results demonstrate that latent-level refinement via flow matching provides a lightweight and effective complement to existing SE approaches for robust ASR.
Improving Noise Robust Audio-Visual Speech Recognition via Router-Gated Cross-Modal Feature Fusion
Aug 26, 2025Robust audio-visual speech recognition (AVSR) in noisy environments remains challenging, as existing systems struggle to estimate audio reliability and dynamically adjust modality reliance. We propose router-gated cross-modal feature fusion, a novel AVSR framework that adaptively reweights audio and visual features based on token-level acoustic corruption scores. Using an audio-visual feature fusion-based router, our method down-weights unreliable audio tokens and reinforces visual cues through gated cross-attention in each decoder layer. This enables the model to pivot toward the visual modality when audio quality deteriorates. Experiments on LRS3 demonstrate that our approach achieves an 16.51-42.67% relative reduction in word error rate compared to AV-HuBERT. Ablation studies confirm that both the router and gating mechanism contribute to improved robustness under real-world acoustic noise.
FLOWER: Flow-Based Estimated Gaussian Guidance for General Speech Restoration
May 03, 2025



We introduce FLOWER, a novel conditioning method designed for speech restoration that integrates Gaussian guidance into generative frameworks. By transforming clean speech into a predefined prior distribution (e.g., Gaussian distribution) using a normalizing flow network, FLOWER extracts critical information to guide generative models. This guidance is incorporated into each block of the generative network, enabling precise restoration control. Experimental results demonstrate the effectiveness of FLOWER in improving performance across various general speech restoration tasks.
Trainable Adaptive Score Normalization for Automatic Speaker Verification
Apr 06, 2025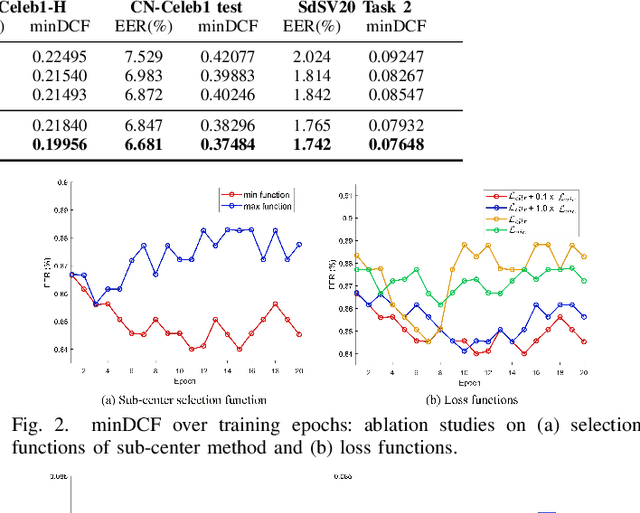
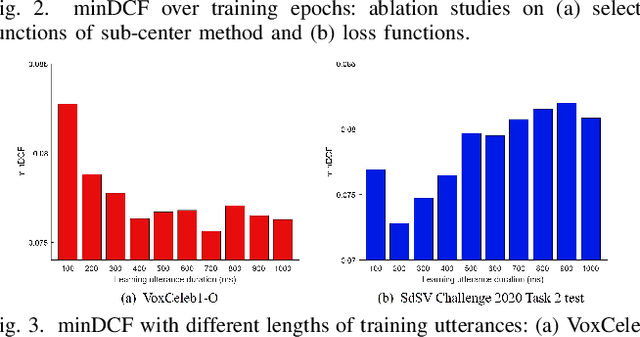
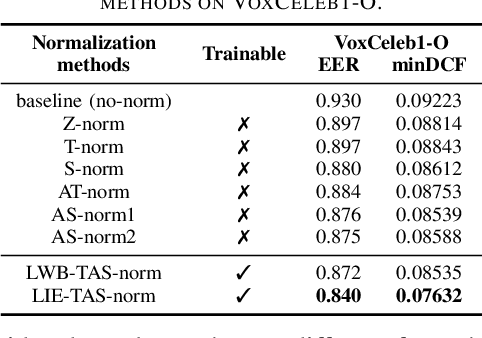
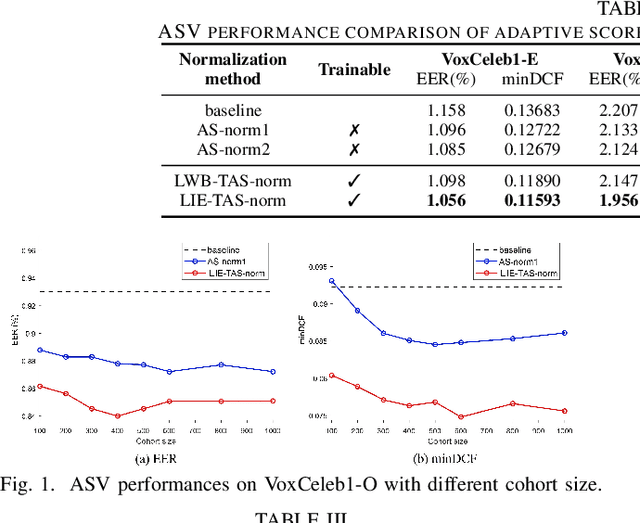
Adaptive S-norm (AS-norm) calibrates automatic speaker verification (ASV) scores by normalizing them utilize the scores of impostors which are similar to the input speaker. However, AS-norm does not involve any learning process, limiting its ability to provide appropriate regularization strength for various evaluation utterances. To address this limitation, we propose a trainable AS-norm (TAS-norm) that leverages learnable impostor embeddings (LIEs), which are used to compose the cohort. These LIEs are initialized to represent each speaker in a training dataset consisting of impostor speakers. Subsequently, LIEs are fine-tuned by simulating an ASV evaluation. We utilize a margin penalty during top-scoring IEs selection in fine-tuning to prevent non-impostor speakers from being selected. In our experiments with ECAPA-TDNN, the proposed TAS-norm observed 4.11% and 10.62% relative improvement in equal error rate and minimum detection cost function, respectively, on VoxCeleb1-O trial compared with standard AS-norm without using proposed LIEs. We further validated the effectiveness of the TAS-norm on additional ASV datasets comprising Persian and Chinese, demonstrating its robustness across different languages.
DM: Dual-path Magnitude Network for General Speech Restoration
Sep 13, 2024


In this paper, we introduce a novel general speech restoration model: the Dual-path Magnitude (DM) network, designed to address multiple distortions including noise, reverberation, and bandwidth degradation effectively. The DM network employs dual parallel magnitude decoders that share parameters: one uses a masking-based algorithm for distortion removal and the other employs a mapping-based approach for speech restoration. A novel aspect of the DM network is the integration of the magnitude spectrogram output from the masking decoder into the mapping decoder through a skip connection, enhancing the overall restoration capability. This integrated approach overcomes the inherent limitations observed in previous models, as detailed in a step-by-step analysis. The experimental results demonstrate that the DM network outperforms other baseline models in the comprehensive aspect of general speech restoration, achieving substantial restoration with fewer parameters.
Team HYU ASML ROBOVOX SP Cup 2024 System Description
Jul 16, 2024



This report describes the submission of HYU ASML team to the IEEE Signal Processing Cup 2024 (SP Cup 2024). This challenge, titled "ROBOVOX: Far-Field Speaker Recognition by a Mobile Robot," focuses on speaker recognition using a mobile robot in noisy and reverberant conditions. Our solution combines the result of deep residual neural networks and time-delay neural network-based speaker embedding models. These models were trained on a diverse dataset that includes French speech. To account for the challenging evaluation environment characterized by high noise, reverberation, and short speech conditions, we focused on data augmentation and training speech duration for the speaker embedding model. Our submission achieved second place on the SP Cup 2024 public leaderboard, with a detection cost function of 0.5245 and an equal error rate of 6.46%.
Improving Transformer-based End-to-End Speaker Diarization by Assigning Auxiliary Losses to Attention Heads
Mar 02, 2023Transformer-based end-to-end neural speaker diarization (EEND) models utilize the multi-head self-attention (SA) mechanism to enable accurate speaker label prediction in overlapped speech regions. In this study, to enhance the training effectiveness of SA-EEND models, we propose the use of auxiliary losses for the SA heads of the transformer layers. Specifically, we assume that the attention weight matrices of an SA layer are redundant if their patterns are similar to those of the identity matrix. We then explicitly constrain such matrices to exhibit specific speaker activity patterns relevant to voice activity detection or overlapped speech detection tasks. Consequently, we expect the proposed auxiliary losses to guide the transformer layers to exhibit more diverse patterns in the attention weights, thereby reducing the assumed redundancies in the SA heads. The effectiveness of the proposed method is demonstrated using the simulated and CALLHOME datasets for two-speaker diarization tasks, reducing the diarization error rate of the conventional SA-EEND model by 32.58% and 17.11%, respectively.
Instance-level loss based multiple-instance learning for acoustic scene classification
Mar 16, 2022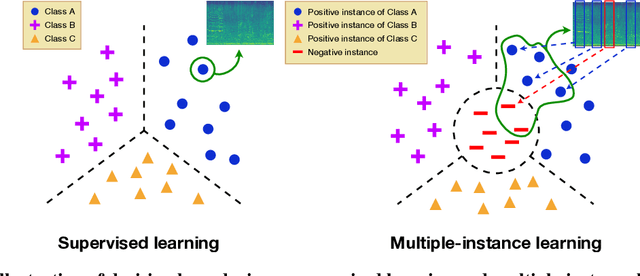

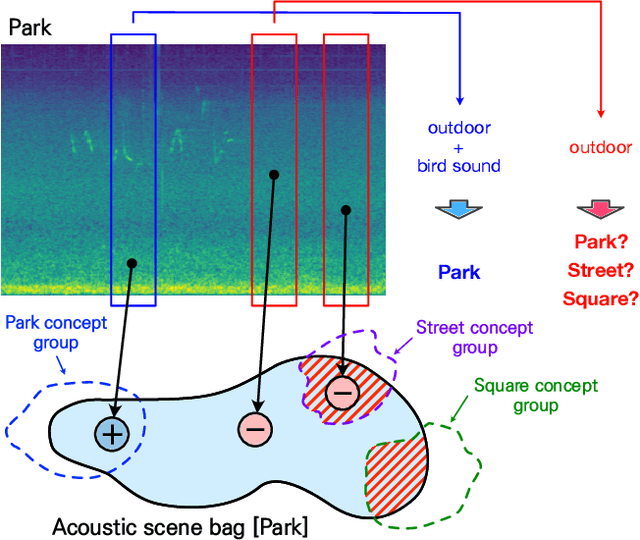
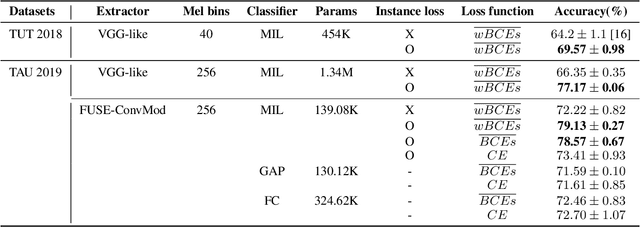
In acoustic scene classification (ASC) task, an acoustic scene consists of diverse attributes and is inferred by identifying combinations of some distinct attributes among them. This study aims to extract and cluster these attributes effectively using a multiple-instance learning (MIL) framework for ASC. MIL, known as one of the weakly supervised learning methods, is a way to extract instances from input data and infer a scene corresponding to the input data with those unlabeled instances. We develop the MIL framework more suitable for ASC systems, adopting instance-level labels and instance-level loss, which are effective in extracting and clustering instances. As a result, the witness rate increases significantly compared to the framework without instance-level loss and labels. Also in several MIL-based ASC systems, the classification accuracy improves by about 5 to 11% than without instance-level loss. In addition, we designed a fully separated convolutional module which is a low-complexity neural network consisting of pointwise, frequency-sided depthwise, and temporal-sided depthwise convolutional filters. Considering both complexity and performance, our proposed system is more practical compared to previous systems on the DCASE 2019 challenge task 1-A leader board. We surpassed the third-place model by achieving a performance of 82.3\% with only the model complexity of 417K, which is at least 40 times fewer than other systems.
Task-specific Optimization of Virtual Channel Linear Prediction-based Speech Dereverberation Front-End for Far-Field Speaker Verification
Dec 27, 2021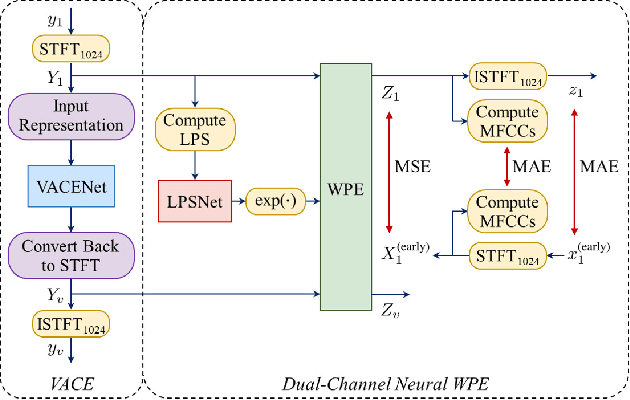
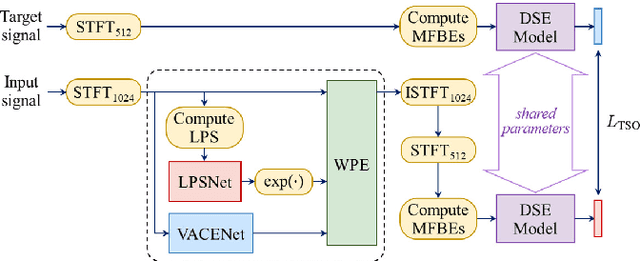
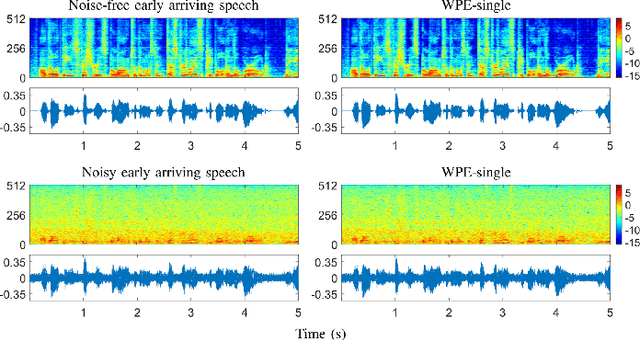
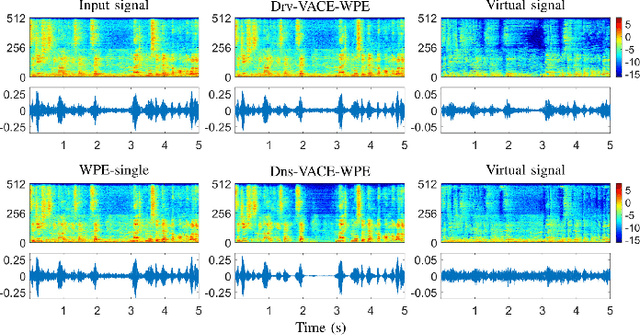
Developing a single-microphone speech denoising or dereverberation front-end for robust automatic speaker verification (ASV) in noisy far-field speaking scenarios is challenging. To address this problem, we present a novel front-end design that involves a recently proposed extension of the weighted prediction error (WPE) speech dereverberation algorithm, the virtual acoustic channel expansion (VACE)-WPE. It is demonstrated experimentally in this study that unlike the conventional WPE algorithm, the VACE-WPE can be explicitly trained to cancel out both late reverberation and background noise. To build the front-end, the VACE-WPE is first independently (pre)trained to produce "noisy" dereverberated signals. Subsequently, given a pretrained speaker embedding model, the VACE-WPE is additionally fine-tuned within a task-specific optimization (TSO) framework, causing the speaker embedding extracted from the processed signal to be similar to that extracted from the "noise-free" target signal. Moreover, to extend the application of the proposed front-end to more general, unconstrained "in-the-wild" ASV scenarios beyond controlled far-field conditions, we propose a distortion regularization method for the VACE-WPE within the TSO framework. The effectiveness of the proposed approach is verified on both far-field and in-the-wild ASV benchmarks, demonstrating its superiority over fully neural front-ends and other TSO methods in various cases.
Knowledge distillation from language model to acoustic model: a hierarchical multi-task learning approach
Oct 20, 2021



The remarkable performance of the pre-trained language model (LM) using self-supervised learning has led to a major paradigm shift in the study of natural language processing. In line with these changes, leveraging the performance of speech recognition systems with massive deep learning-based LMs is a major topic of speech recognition research. Among the various methods of applying LMs to speech recognition systems, in this paper, we focus on a cross-modal knowledge distillation method that transfers knowledge between two types of deep neural networks with different modalities. We propose an acoustic model structure with multiple auxiliary output layers for cross-modal distillation and demonstrate that the proposed method effectively compensates for the shortcomings of the existing label-interpolation-based distillation method. In addition, we extend the proposed method to a hierarchical distillation method using LMs trained in different units (senones, monophones, and subwords) and reveal the effectiveness of the hierarchical distillation method through an ablation study.