 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrainable Adaptive Score Normalization for Automatic Speaker Verification
Apr 06, 2025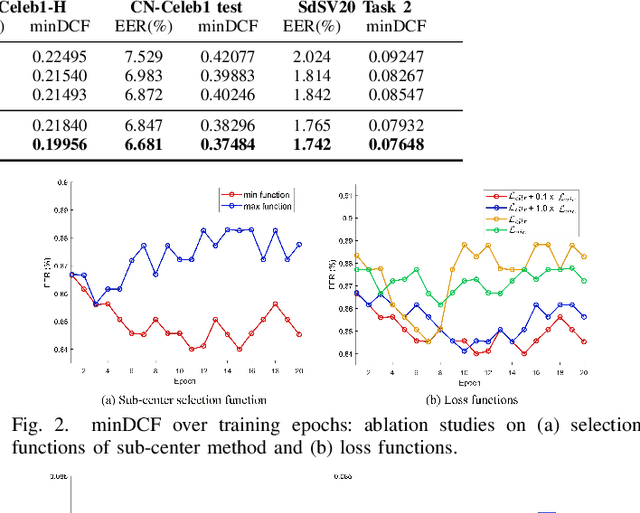
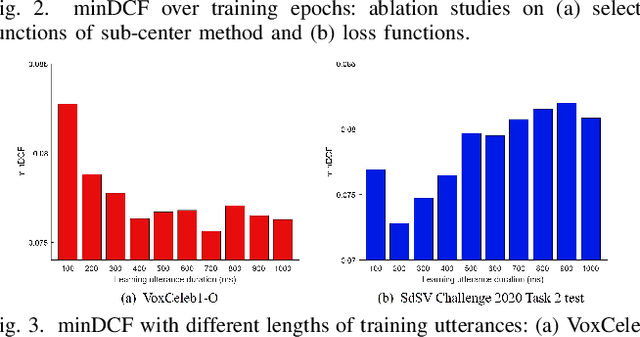
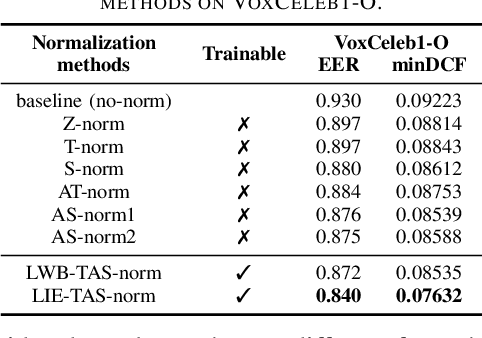
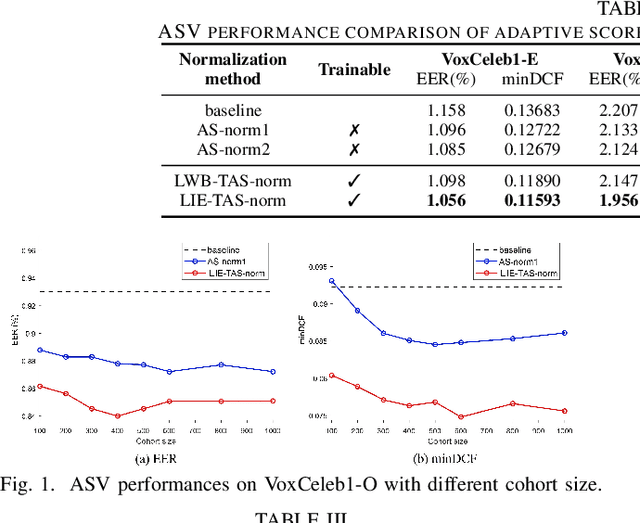
Adaptive S-norm (AS-norm) calibrates automatic speaker verification (ASV) scores by normalizing them utilize the scores of impostors which are similar to the input speaker. However, AS-norm does not involve any learning process, limiting its ability to provide appropriate regularization strength for various evaluation utterances. To address this limitation, we propose a trainable AS-norm (TAS-norm) that leverages learnable impostor embeddings (LIEs), which are used to compose the cohort. These LIEs are initialized to represent each speaker in a training dataset consisting of impostor speakers. Subsequently, LIEs are fine-tuned by simulating an ASV evaluation. We utilize a margin penalty during top-scoring IEs selection in fine-tuning to prevent non-impostor speakers from being selected. In our experiments with ECAPA-TDNN, the proposed TAS-norm observed 4.11% and 10.62% relative improvement in equal error rate and minimum detection cost function, respectively, on VoxCeleb1-O trial compared with standard AS-norm without using proposed LIEs. We further validated the effectiveness of the TAS-norm on additional ASV datasets comprising Persian and Chinese, demonstrating its robustness across different languages.
Team HYU ASML ROBOVOX SP Cup 2024 System Description
Jul 16, 2024



This report describes the submission of HYU ASML team to the IEEE Signal Processing Cup 2024 (SP Cup 2024). This challenge, titled "ROBOVOX: Far-Field Speaker Recognition by a Mobile Robot," focuses on speaker recognition using a mobile robot in noisy and reverberant conditions. Our solution combines the result of deep residual neural networks and time-delay neural network-based speaker embedding models. These models were trained on a diverse dataset that includes French speech. To account for the challenging evaluation environment characterized by high noise, reverberation, and short speech conditions, we focused on data augmentation and training speech duration for the speaker embedding model. Our submission achieved second place on the SP Cup 2024 public leaderboard, with a detection cost function of 0.5245 and an equal error rate of 6.46%.
Improving Transformer-based End-to-End Speaker Diarization by Assigning Auxiliary Losses to Attention Heads
Mar 02, 2023Transformer-based end-to-end neural speaker diarization (EEND) models utilize the multi-head self-attention (SA) mechanism to enable accurate speaker label prediction in overlapped speech regions. In this study, to enhance the training effectiveness of SA-EEND models, we propose the use of auxiliary losses for the SA heads of the transformer layers. Specifically, we assume that the attention weight matrices of an SA layer are redundant if their patterns are similar to those of the identity matrix. We then explicitly constrain such matrices to exhibit specific speaker activity patterns relevant to voice activity detection or overlapped speech detection tasks. Consequently, we expect the proposed auxiliary losses to guide the transformer layers to exhibit more diverse patterns in the attention weights, thereby reducing the assumed redundancies in the SA heads. The effectiveness of the proposed method is demonstrated using the simulated and CALLHOME datasets for two-speaker diarization tasks, reducing the diarization error rate of the conventional SA-EEND model by 32.58% and 17.11%, respectively.