 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-specific Optimization of Virtual Channel Linear Prediction-based Speech Dereverberation Front-End for Far-Field Speaker Verification
Paper and Code
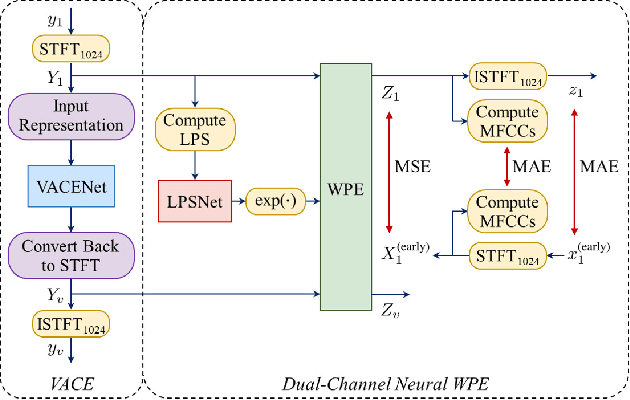
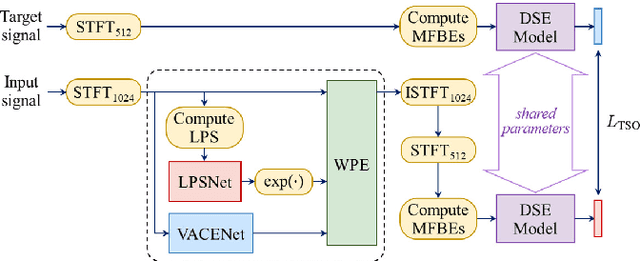
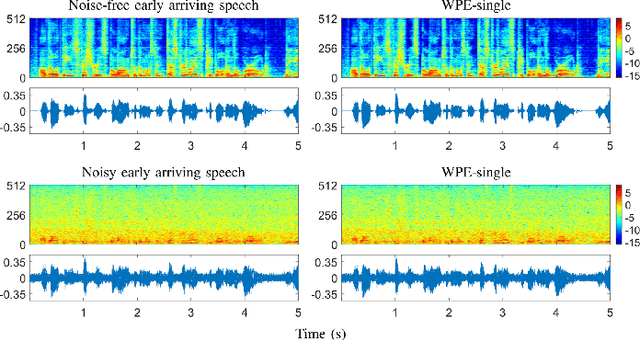
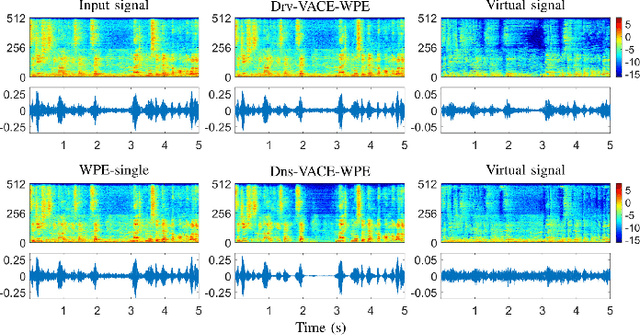
Developing a single-microphone speech denoising or dereverberation front-end for robust automatic speaker verification (ASV) in noisy far-field speaking scenarios is challenging. To address this problem, we present a novel front-end design that involves a recently proposed extension of the weighted prediction error (WPE) speech dereverberation algorithm, the virtual acoustic channel expansion (VACE)-WPE. It is demonstrated experimentally in this study that unlike the conventional WPE algorithm, the VACE-WPE can be explicitly trained to cancel out both late reverberation and background noise. To build the front-end, the VACE-WPE is first independently (pre)trained to produce "noisy" dereverberated signals. Subsequently, given a pretrained speaker embedding model, the VACE-WPE is additionally fine-tuned within a task-specific optimization (TSO) framework, causing the speaker embedding extracted from the processed signal to be similar to that extracted from the "noise-free" target signal. Moreover, to extend the application of the proposed front-end to more general, unconstrained "in-the-wild" ASV scenarios beyond controlled far-field conditions, we propose a distortion regularization method for the VACE-WPE within the TSO framework. The effectiveness of the proposed approach is verified on both far-field and in-the-wild ASV benchmarks, demonstrating its superiority over fully neural front-ends and other TSO methods in various cases.