 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegration of TensorFlow based Acoustic Model with Kaldi WFST Decoder
Paper and Code



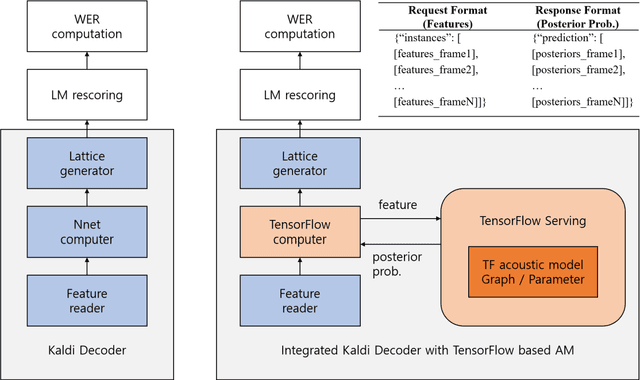
While the Kaldi framework provides state-of-the-art components for speech recognition like feature extraction, deep neural network (DNN)-based acoustic models, and a weighted finite state transducer (WFST)-based decoder, it is difficult to implement a new flexible DNN model. By contrast, a general-purpose deep learning framework, such as TensorFlow, can easily build various types of neural network architectures using a tensor-based computation method, but it is difficult to apply them to WFST-based speech recognition. In this study, a TensorFlow-based acoustic model is integrated with a WFST-based Kaldi decoder to combine the two frameworks. The features and alignments used in Kaldi are converted so they can be trained by the TensorFlow model, and the DNN-based acoustic model is then trained. In the integrated Kaldi decoder, the posterior probabilities are calculated by querying the trained TensorFlow model, and a beam search is performed to generate the lattice. The advantages of the proposed one-pass decoder include the application of various types of neural networks to WFST-based speech recognition and WFST-based online decoding using a TensorFlow-based acoustic model. The TensorFlow based acoustic models trained using the RM, WSJ, and LibriSpeech datasets show the same level of performance as the model trained using the Kaldi framework.