 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Attentive Multi-Layer Aggregation with Feature Recalibration and Normalization for End-to-End Speaker Verification System
Paper and Code
Jul 28, 2020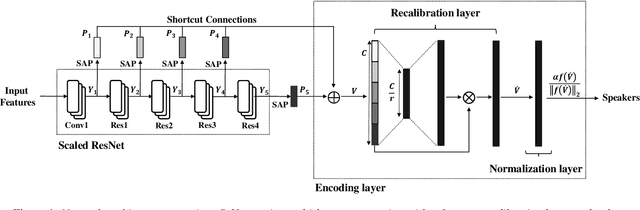
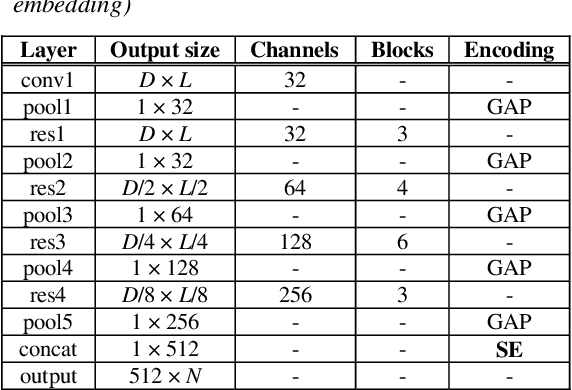
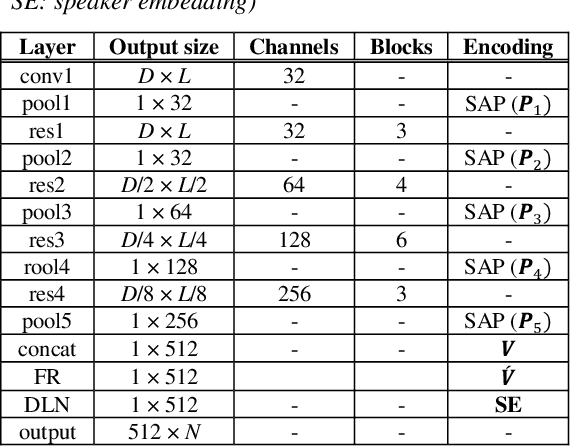

One of the most important parts of an end-to-end speaker verification system is the speaker embedding generation. In our previous paper, we reported that shortcut connections-based multi-layer aggregation improves the representational power of the speaker embedding. However, the number of model parameters is relatively large and the unspecified variations increase in the multi-layer aggregation. Therefore, we propose a self-attentive multi-layer aggregation with feature recalibration and normalization for end-to-end speaker verification system. To reduce the number of model parameters, the ResNet, which scaled channel width and layer depth, is used as a baseline. To control the variability in the training, a self-attention mechanism is applied to perform the multi-layer aggregation with dropout regularizations and batch normalizations. Then, a feature recalibration layer is applied to the aggregated feature using fully-connected layers and nonlinear activation functions. Deep length normalization is also used on a recalibrated feature in the end-to-end training process. Experimental results using the VoxCeleb1 evaluation dataset showed that the performance of the proposed methods was comparable to that of state-of-the-art models (equal error rate of 4.95% and 2.86%, using the VoxCeleb1 and VoxCeleb2 training datasets, respectively).