 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Augmentation for Self-supervised Text-guided Image Manipulation
Dec 17, 2024
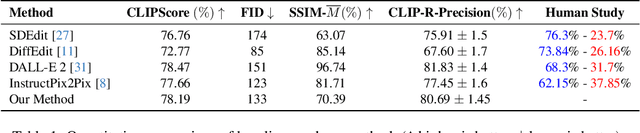
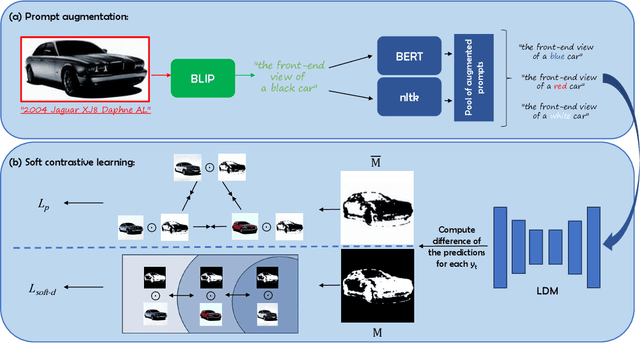
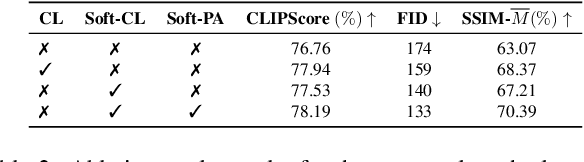
Text-guided image editing finds applications in various creative and practical fields. While recent studies in image generation have advanced the field, they often struggle with the dual challenges of coherent image transformation and context preservation. In response, our work introduces prompt augmentation, a method amplifying a single input prompt into several target prompts, strengthening textual context and enabling localised image editing. Specifically, we use the augmented prompts to delineate the intended manipulation area. We propose a Contrastive Loss tailored to driving effective image editing by displacing edited areas and drawing preserved regions closer. Acknowledging the continuous nature of image manipulations, we further refine our approach by incorporating the similarity concept, creating a Soft Contrastive Loss. The new losses are incorporated to the diffusion model, demonstrating improved or competitive image editing results on public datasets and generated images over state-of-the-art approaches.
iEdit: Localised Text-guided Image Editing with Weak Supervision
May 10, 2023Diffusion models (DMs) can generate realistic images with text guidance using large-scale datasets. However, they demonstrate limited controllability in the output space of the generated images. We propose a novel learning method for text-guided image editing, namely \texttt{iEdit}, that generates images conditioned on a source image and a textual edit prompt. As a fully-annotated dataset with target images does not exist, previous approaches perform subject-specific fine-tuning at test time or adopt contrastive learning without a target image, leading to issues on preserving the fidelity of the source image. We propose to automatically construct a dataset derived from LAION-5B, containing pseudo-target images with their descriptive edit prompts given input image-caption pairs. This dataset gives us the flexibility of introducing a weakly-supervised loss function to generate the pseudo-target image from the latent noise of the source image conditioned on the edit prompt. To encourage localised editing and preserve or modify spatial structures in the image, we propose a loss function that uses segmentation masks to guide the editing during training and optionally at inference. Our model is trained on the constructed dataset with 200K samples and constrained GPU resources. It shows favourable results against its counterparts in terms of image fidelity, CLIP alignment score and qualitatively for editing both generated and real images.
A Unified Architecture of Semantic Segmentation and Hierarchical Generative Adversarial Networks for Expression Manipulation
Dec 08, 2021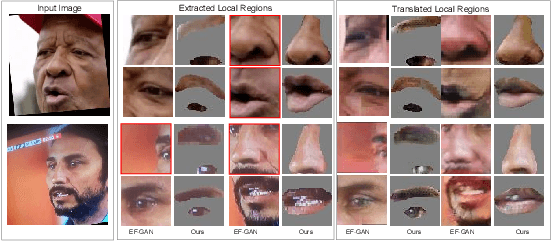
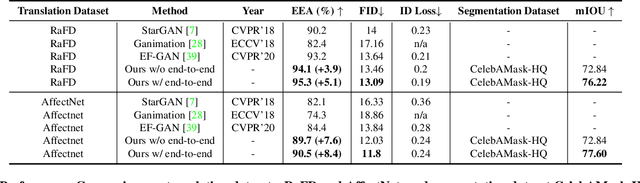
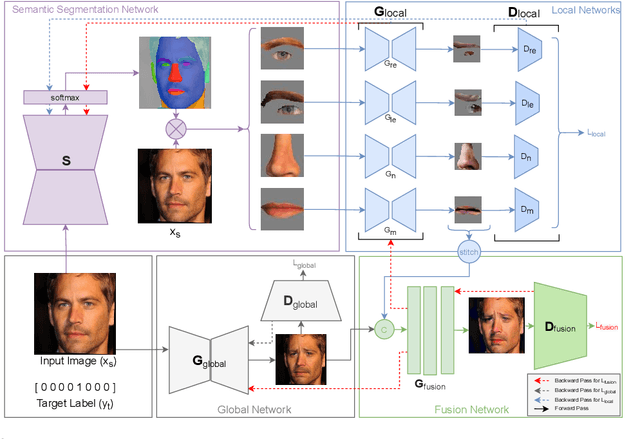
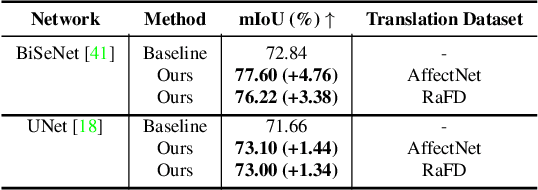
Editing facial expressions by only changing what we want is a long-standing research problem in Generative Adversarial Networks (GANs) for image manipulation. Most of the existing methods that rely only on a global generator usually suffer from changing unwanted attributes along with the target attributes. Recently, hierarchical networks that consist of both a global network dealing with the whole image and multiple local networks focusing on local parts are showing success. However, these methods extract local regions by bounding boxes centred around the sparse facial key points which are non-differentiable, inaccurate and unrealistic. Hence, the solution becomes sub-optimal, introduces unwanted artefacts degrading the overall quality of the synthetic images. Moreover, a recent study has shown strong correlation between facial attributes and local semantic regions. To exploit this relationship, we designed a unified architecture of semantic segmentation and hierarchical GANs. A unique advantage of our framework is that on forward pass the semantic segmentation network conditions the generative model, and on backward pass gradients from hierarchical GANs are propagated to the semantic segmentation network, which makes our framework an end-to-end differentiable architecture. This allows both architectures to benefit from each other. To demonstrate its advantages, we evaluate our method on two challenging facial expression translation benchmarks, AffectNet and RaFD, and a semantic segmentation benchmark, CelebAMask-HQ across two popular architectures, BiSeNet and UNet. Our extensive quantitative and qualitative evaluations on both face semantic segmentation and face expression manipulation tasks validate the effectiveness of our work over existing state-of-the-art methods.
3D Dense Geometry-Guided Facial Expression Synthesis by Adversarial Learning
Sep 30, 2020
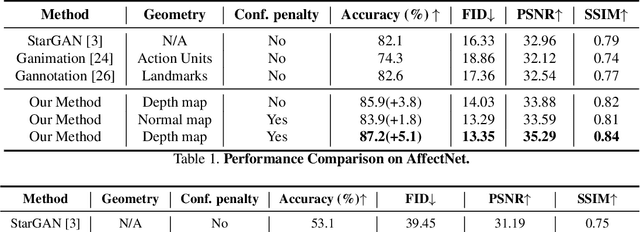
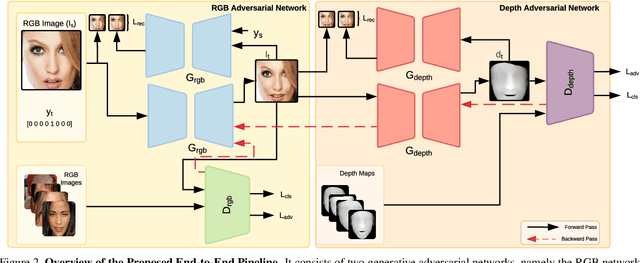

Manipulating facial expressions is a challenging task due to fine-grained shape changes produced by facial muscles and the lack of input-output pairs for supervised learning. Unlike previous methods using Generative Adversarial Networks (GAN), which rely on cycle-consistency loss or sparse geometry (landmarks) loss for expression synthesis, we propose a novel GAN framework to exploit 3D dense (depth and surface normals) information for expression manipulation. However, a large-scale dataset containing RGB images with expression annotations and their corresponding depth maps is not available. To this end, we propose to use an off-the-shelf state-of-the-art 3D reconstruction model to estimate the depth and create a large-scale RGB-Depth dataset after a manual data clean-up process. We utilise this dataset to minimise the novel depth consistency loss via adversarial learning (note we do not have ground truth depth maps for generated face images) and the depth categorical loss of synthetic data on the discriminator. In addition, to improve the generalisation and lower the bias of the depth parameters, we propose to use a novel confidence regulariser on the discriminator side of the framework. We extensively performed both quantitative and qualitative evaluations on two publicly available challenging facial expression benchmarks: AffectNet and RaFD. Our experiments demonstrate that the proposed method outperforms the competitive baseline and existing arts by a large margin.
Sampling Strategies for GAN Synthetic Data
Sep 10, 2019
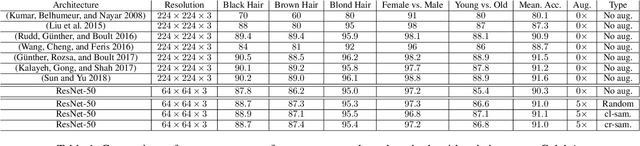
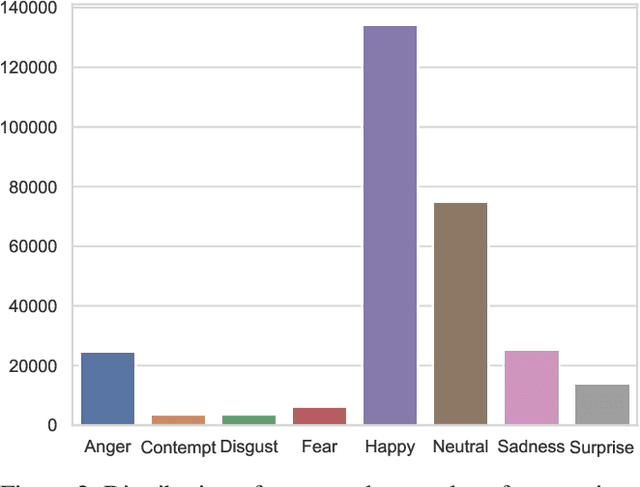
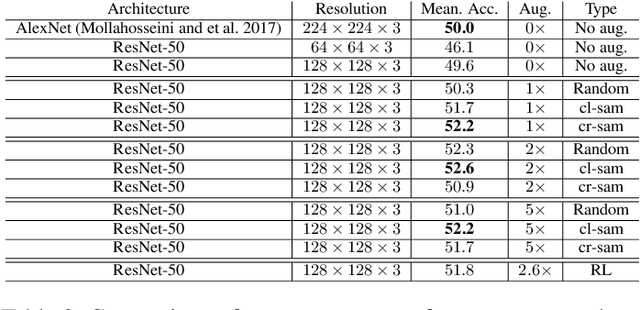
Generative Adversarial Networks (GANs) have been used widely to generate large volumes of synthetic data. This data is being utilized for augmenting with real examples in order to train deep Convolutional Neural Networks (CNNs). Studies have shown that the generated examples lack sufficient realism to train deep CNNs and are poor in diversity. Unlike previous studies of randomly augmenting the synthetic data with real data, we present our simple, effective and easy to implement synthetic data sampling methods to train deep CNNs more efficiently and accurately. To this end, we propose to maximally utilize the parameters learned during training of the GAN itself. These include discriminator's realism confidence score and the confidence on the target label of the synthetic data. In addition to this, we explore reinforcement learning (RL) to automatically search a subset of meaningful synthetic examples from a large pool of GAN synthetic data. We evaluate our method on two challenging face attribute classification data sets viz. AffectNet and CelebA. Our extensive experiments clearly demonstrate the need of sampling synthetic data before augmentation, which also improves the performance of one of the state-of-the-art deep CNNs in vitro.
AugLabel: Exploiting Word Representations to Augment Labels for Face Attribute Classification
Jul 15, 2019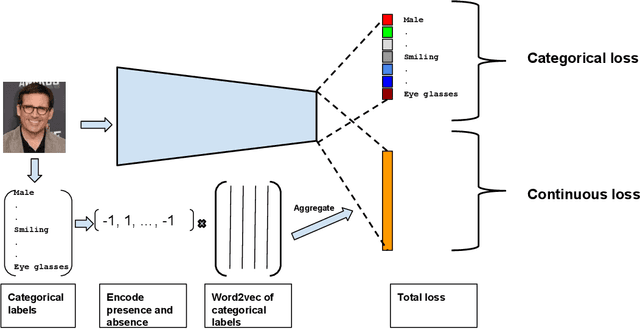
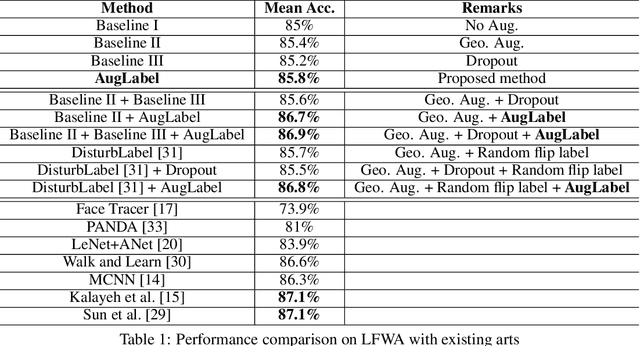
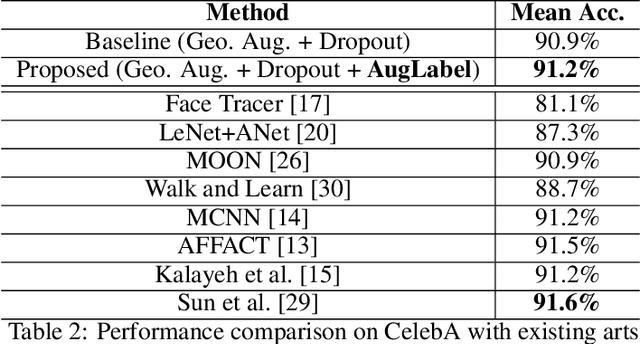
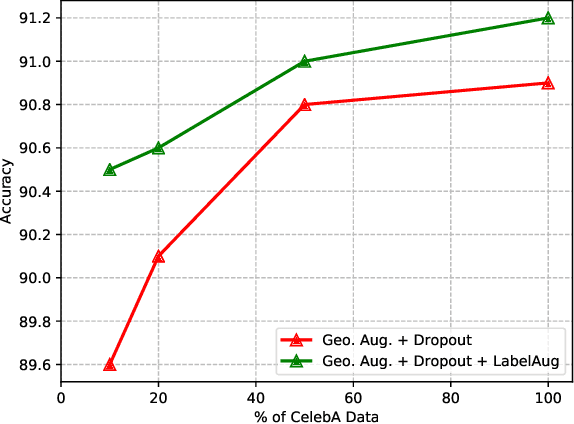
Augmenting data in image space (eg. flipping, cropping etc) and activation space (eg. dropout) are being widely used to regularise deep neural networks and have been successfully applied on several computer vision tasks. Unlike previous works, which are mostly focused on doing augmentation in the aforementioned domains, we propose to do augmentation in label space. In this paper, we present a novel method to generate fixed dimensional labels with continuous values for images by exploiting the word2vec representations of the existing categorical labels. We then append these representations with existing categorical labels and train the model. We validated our idea on two challenging face attribute classification data sets viz. CelebA and LFWA. Our extensive experiments show that the augmented labels improve the performance of the competitive deep learning baseline and reduce the need of annotated real data up to 50%, while attaining a performance similar to the state-of-the-art methods.