 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiEdit: Localised Text-guided Image Editing with Weak Supervision
May 10, 2023Diffusion models (DMs) can generate realistic images with text guidance using large-scale datasets. However, they demonstrate limited controllability in the output space of the generated images. We propose a novel learning method for text-guided image editing, namely \texttt{iEdit}, that generates images conditioned on a source image and a textual edit prompt. As a fully-annotated dataset with target images does not exist, previous approaches perform subject-specific fine-tuning at test time or adopt contrastive learning without a target image, leading to issues on preserving the fidelity of the source image. We propose to automatically construct a dataset derived from LAION-5B, containing pseudo-target images with their descriptive edit prompts given input image-caption pairs. This dataset gives us the flexibility of introducing a weakly-supervised loss function to generate the pseudo-target image from the latent noise of the source image conditioned on the edit prompt. To encourage localised editing and preserve or modify spatial structures in the image, we propose a loss function that uses segmentation masks to guide the editing during training and optionally at inference. Our model is trained on the constructed dataset with 200K samples and constrained GPU resources. It shows favourable results against its counterparts in terms of image fidelity, CLIP alignment score and qualitatively for editing both generated and real images.
Contrastive Language-Action Pre-training for Temporal Localization
Apr 26, 2022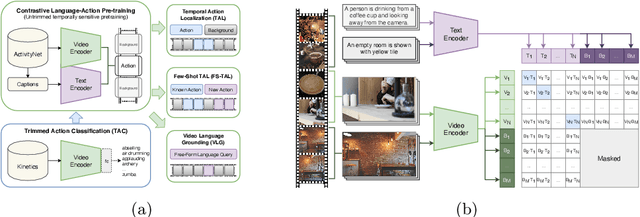
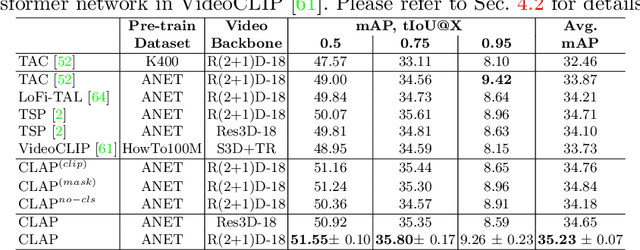
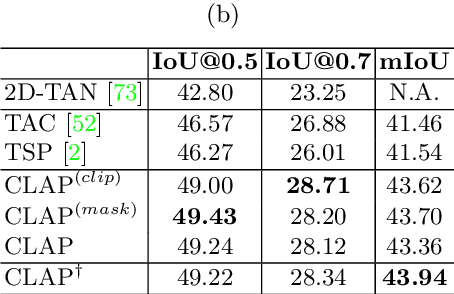
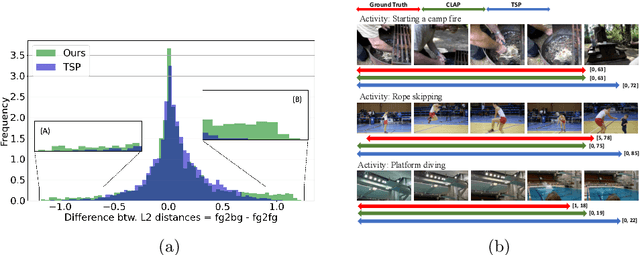
Long-form video understanding requires designing approaches that are able to temporally localize activities or language. End-to-end training for such tasks is limited by the compute device memory constraints and lack of temporal annotations at large-scale. These limitations can be addressed by pre-training on large datasets of temporally trimmed videos supervised by class annotations. Once the video encoder is pre-trained, it is common practice to freeze it during fine-tuning. Therefore, the video encoder does not learn temporal boundaries and unseen classes, causing a domain gap with respect to the downstream tasks. Moreover, using temporally trimmed videos prevents to capture the relations between different action categories and the background context in a video clip which results in limited generalization capacity. To address these limitations, we propose a novel post-pre-training approach without freezing the video encoder which leverages language. We introduce a masked contrastive learning loss to capture visio-linguistic relations between activities, background video clips and language in the form of captions. Our experiments show that the proposed approach improves the state-of-the-art on temporal action localization, few-shot temporal action localization, and video language grounding tasks.
Revamping Cross-Modal Recipe Retrieval with Hierarchical Transformers and Self-supervised Learning
Mar 24, 2021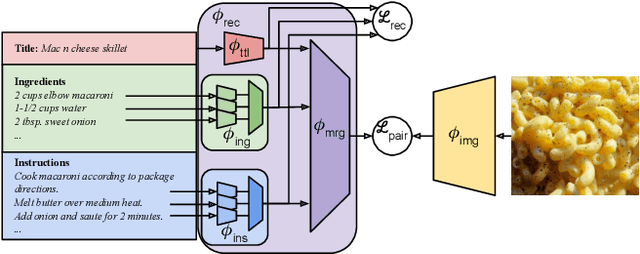
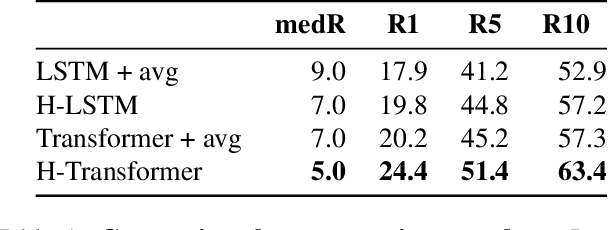

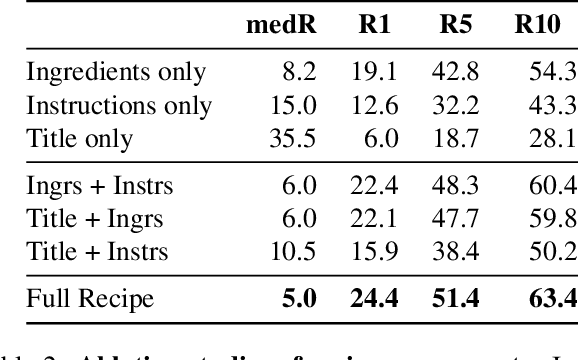
Cross-modal recipe retrieval has recently gained substantial attention due to the importance of food in people's lives, as well as the availability of vast amounts of digital cooking recipes and food images to train machine learning models. In this work, we revisit existing approaches for cross-modal recipe retrieval and propose a simplified end-to-end model based on well established and high performing encoders for text and images. We introduce a hierarchical recipe Transformer which attentively encodes individual recipe components (titles, ingredients and instructions). Further, we propose a self-supervised loss function computed on top of pairs of individual recipe components, which is able to leverage semantic relationships within recipes, and enables training using both image-recipe and recipe-only samples. We conduct a thorough analysis and ablation studies to validate our design choices. As a result, our proposed method achieves state-of-the-art performance in the cross-modal recipe retrieval task on the Recipe1M dataset. We make code and models publicly available.
GarNet++: Improving Fast and Accurate Static3D Cloth Draping by Curvature Loss
Jul 20, 2020
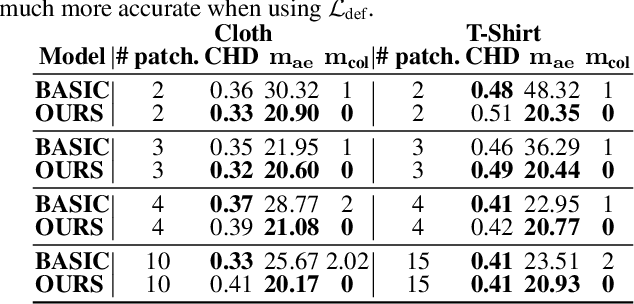
In this paper, we tackle the problem of static 3D cloth draping on virtual human bodies. We introduce a two-stream deep network model that produces a visually plausible draping of a template cloth on virtual 3D bodies by extracting features from both the body and garment shapes. Our network learns to mimic a Physics-Based Simulation (PBS) method while requiring two orders of magnitude less computation time. To train the network, we introduce loss terms inspired by PBS to produce plausible results and make the model collision-aware. To increase the details of the draped garment, we introduce two loss functions that penalize the difference between the curvature of the predicted cloth and PBS. Particularly, we study the impact of mean curvature normal and a novel detail-preserving loss both qualitatively and quantitatively. Our new curvature loss computes the local covariance matrices of the 3D points, and compares the Rayleigh quotients of the prediction and PBS. This leads to more details while performing favorably or comparably against the loss that considers mean curvature normal vectors in the 3D triangulated meshes. We validate our framework on four garment types for various body shapes and poses. Finally, we achieve superior performance against a recently proposed data-driven method.
Shape Reconstruction by Learning Differentiable Surface Representations
Nov 25, 2019
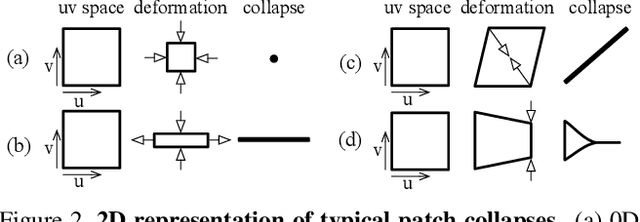
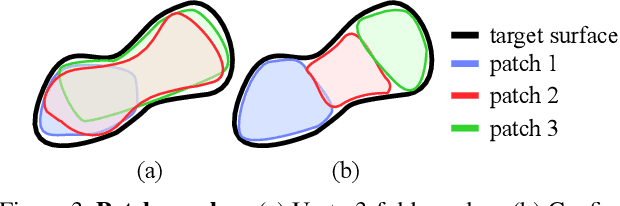
Generative models that produce point clouds have emerged as a powerful tool to represent 3D surfaces, and the best current ones rely on learning an ensemble of parametric representations. Unfortunately, they offer no control over the deformations of the surface patches that form the ensemble and thus fail to prevent them from either overlapping or collapsing into single points or lines. As a consequence, computing shape properties such as surface normals and curvatures becomes difficult and unreliable. In this paper, we show that we can exploit the inherent differentiability of deep networks to leverage differential surface properties during training so as to prevent patch collapse and strongly reduce patch overlap. Furthermore, this lets us reliably compute quantities such as surface normals and curvatures. We will demonstrate on several tasks that this yields more accurate surface reconstructions than the state-of-the-art methods in terms of normals estimation and amount of collapsed and overlapped patches.
Quadruplet Selection Methods for Deep Embedding Learning
Jul 22, 2019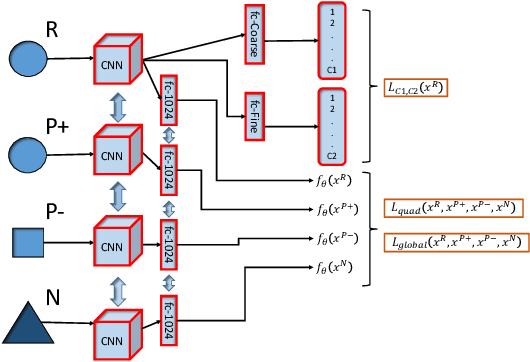
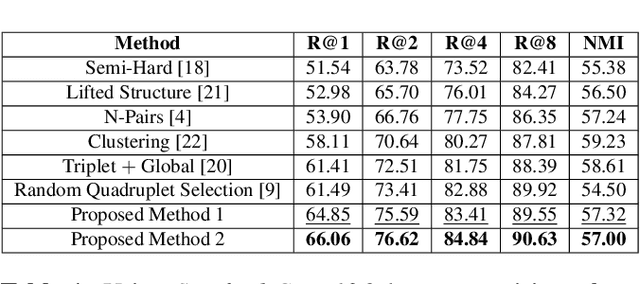
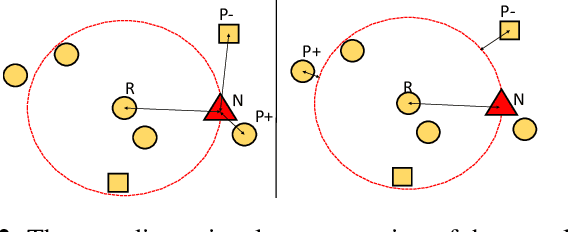
Recognition of objects with subtle differences has been used in many practical applications, such as car model recognition and maritime vessel identification. For discrimination of the objects in fine-grained detail, we focus on deep embedding learning by using a multi-task learning framework, in which the hierarchical labels (coarse and fine labels) of the samples are utilized both for classification and a quadruplet-based loss function. In order to improve the recognition strength of the learned features, we present a novel feature selection method specifically designed for four training samples of a quadruplet. By experiments, it is observed that the selection of very hard negative samples with relatively easy positive ones from the same coarse and fine classes significantly increases some performance metrics in a fine-grained dataset when compared to selecting the quadruplet samples randomly. The feature embedding learned by the proposed method achieves favorable performance against its state-of-the-art counterparts.
GarNet: A Two-stream Network for Fast and Accurate 3D Cloth Draping
Nov 27, 2018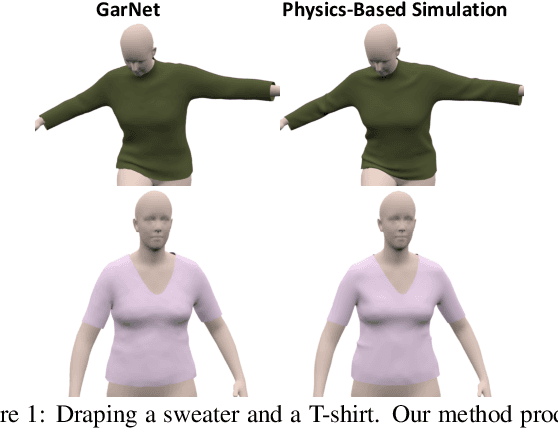
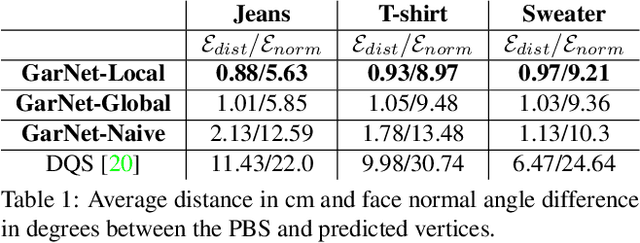
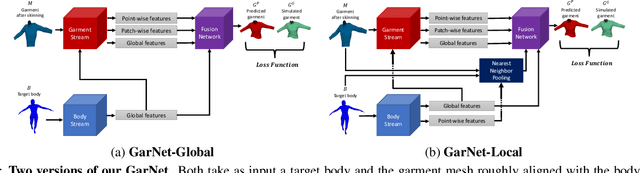
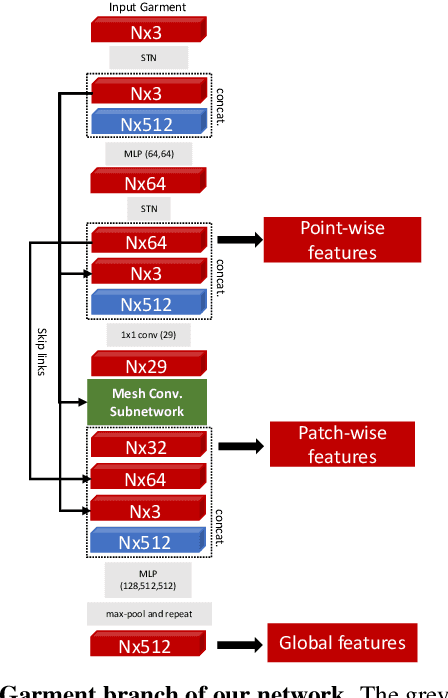
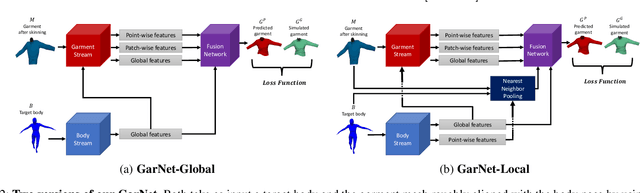
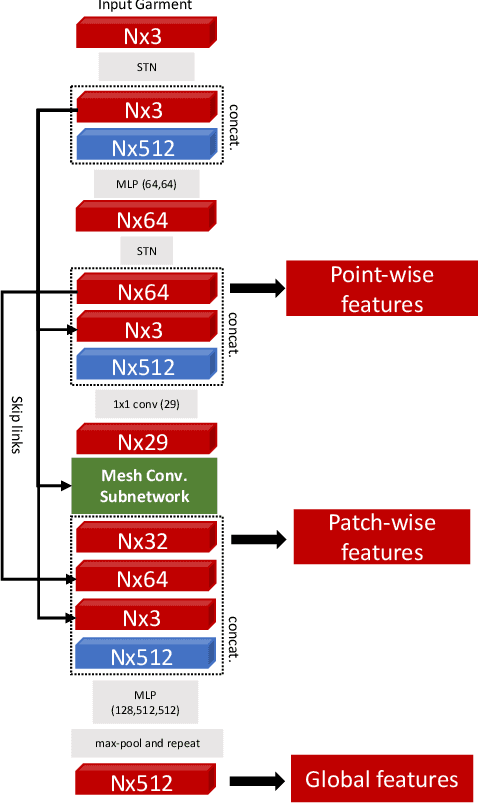
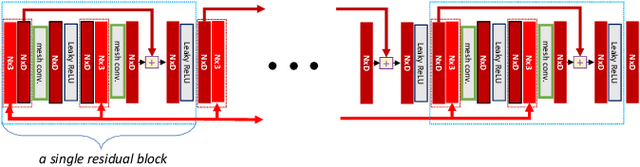
While Physics-Based Simulation (PBS) can highly accurately drape a 3D garment model on a 3D body, it remains too costly for real-time applications, such as virtual try-on. By contrast, inference in a deep network, that is, a single forward pass, is typically quite fast. In this paper, we leverage this property and introduce a novel architecture to fit a 3D garment template to a 3D body model. Specifically, we build upon the recent progress in 3D point-cloud processing with deep networks to extract garment features at varying levels of detail, including point-wise, patch-wise and global features. We then fuse these features with those extracted in parallel from the 3D body, so as to model the cloth-body interactions. The resulting two-stream architecture is trained with a loss function inspired by physics-based modeling, and delivers realistic garment shapes whose 3D points are, on average, less than 1.5cm away from those of a PBS method, while running 40 times faster.
Good Features to Correlate for Visual Tracking
Mar 10, 2018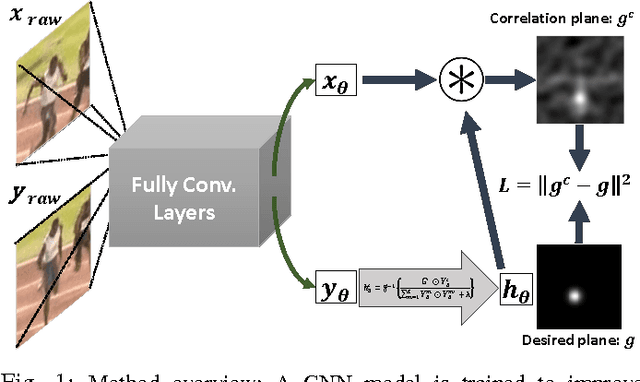



During the recent years, correlation filters have shown dominant and spectacular results for visual object tracking. The types of the features that are employed in these family of trackers significantly affect the performance of visual tracking. The ultimate goal is to utilize robust features invariant to any kind of appearance change of the object, while predicting the object location as properly as in the case of no appearance change. As the deep learning based methods have emerged, the study of learning features for specific tasks has accelerated. For instance, discriminative visual tracking methods based on deep architectures have been studied with promising performance. Nevertheless, correlation filter based (CFB) trackers confine themselves to use the pre-trained networks which are trained for object classification problem. To this end, in this manuscript the problem of learning deep fully convolutional features for the CFB visual tracking is formulated. In order to learn the proposed model, a novel and efficient backpropagation algorithm is presented based on the loss function of the network. The proposed learning framework enables the network model to be flexible for a custom design. Moreover, it alleviates the dependency on the network trained for classification. Extensive performance analysis shows the efficacy of the proposed custom design in the CFB tracking framework. By fine-tuning the convolutional parts of a state-of-the-art network and integrating this model to a CFB tracker, which is the top performing one of VOT2016, 18% increase is achieved in terms of expected average overlap, and tracking failures are decreased by 25%, while maintaining the superiority over the state-of-the-art methods in OTB-2013 and OTB-2015 tracking datasets.
* Accepted version of IEEE Transactions on Image Processing