 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSR4B: Biomass Map Super-Resolution with Sentinel-1/2 Guidance
Apr 03, 2025

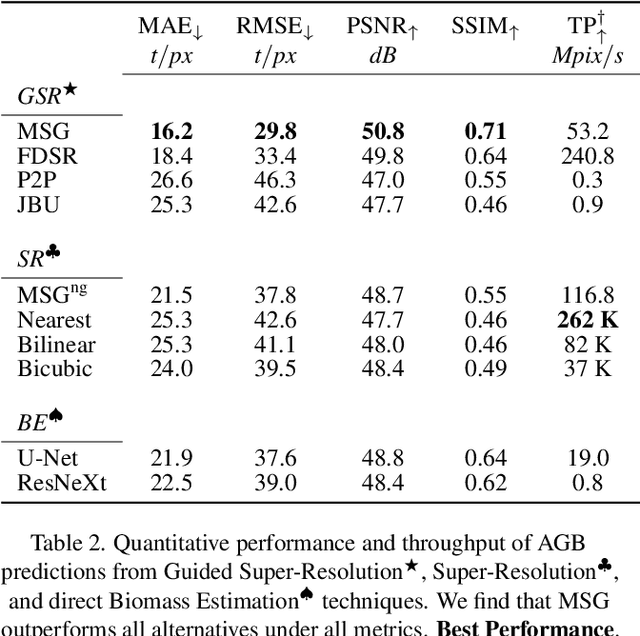

Accurate Above-Ground Biomass (AGB) mapping at both large scale and high spatio-temporal resolution is essential for applications ranging from climate modeling to biodiversity assessment, and sustainable supply chain monitoring. At present, fine-grained AGB mapping relies on costly airborne laser scanning acquisition campaigns usually limited to regional scales. Initiatives such as the ESA CCI map attempt to generate global biomass products from diverse spaceborne sensors but at a coarser resolution. To enable global, high-resolution (HR) mapping, several works propose to regress AGB from HR satellite observations such as ESA Sentinel-1/2 images. We propose a novel way to address HR AGB estimation, by leveraging both HR satellite observations and existing low-resolution (LR) biomass products. We cast this problem as Guided Super-Resolution (GSR), aiming at upsampling LR biomass maps (sources) from $100$ to $10$ m resolution, using auxiliary HR co-registered satellite images (guides). We compare super-resolving AGB maps with and without guidance, against direct regression from satellite images, on the public BioMassters dataset. We observe that Multi-Scale Guidance (MSG) outperforms direct regression both for regression ($-780$ t/ha RMSE) and perception ($+2.0$ dB PSNR) metrics, and better captures high-biomass values, without significant computational overhead. Interestingly, unlike the RGB+Depth setting they were originally designed for, our best-performing AGB GSR approaches are those that most preserve the guide image texture. Our results make a strong case for adopting the GSR framework for accurate HR biomass mapping at scale. Our code and model weights are made publicly available (https://github.com/kaankaramanofficial/GSR4B).
Quadruplet Selection Methods for Deep Embedding Learning
Jul 22, 2019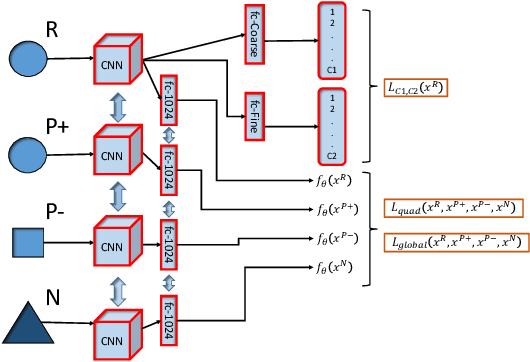
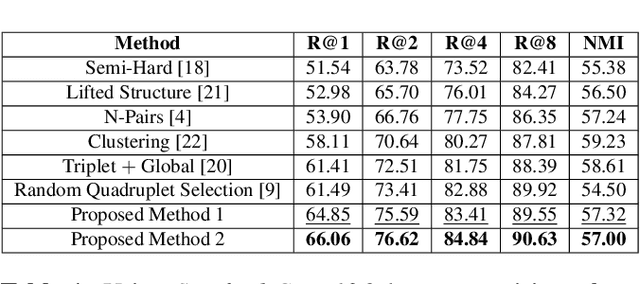
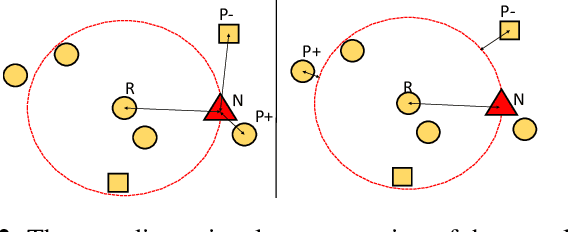
Recognition of objects with subtle differences has been used in many practical applications, such as car model recognition and maritime vessel identification. For discrimination of the objects in fine-grained detail, we focus on deep embedding learning by using a multi-task learning framework, in which the hierarchical labels (coarse and fine labels) of the samples are utilized both for classification and a quadruplet-based loss function. In order to improve the recognition strength of the learned features, we present a novel feature selection method specifically designed for four training samples of a quadruplet. By experiments, it is observed that the selection of very hard negative samples with relatively easy positive ones from the same coarse and fine classes significantly increases some performance metrics in a fine-grained dataset when compared to selecting the quadruplet samples randomly. The feature embedding learned by the proposed method achieves favorable performance against its state-of-the-art counterparts.