 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch-based Representation and Learning for Efficient Deformation Modeling
Jan 08, 2026In this paper, we present a patch-based representation of surfaces, PolyFit, which is obtained by fitting jet functions locally on surface patches. Such a representation can be learned efficiently in a supervised fashion from both analytic functions and real data. Once learned, it can be generalized to various types of surfaces. Using PolyFit, the surfaces can be efficiently deformed by updating a compact set of jet coefficients rather than optimizing per-vertex degrees of freedom for many downstream tasks in computer vision and graphics. We demonstrate the capabilities of our proposed methodologies with two applications: 1) Shape-from-template (SfT): where the goal is to deform the input 3D template of an object as seen in image/video. Using PolyFit, we adopt test-time optimization that delivers competitive accuracy while being markedly faster than offline physics-based solvers, and outperforms recent physics-guided neural simulators in accuracy at modest additional runtime. 2) Garment draping. We train a self-supervised, mesh- and garment-agnostic model that generalizes across resolutions and garment types, delivering up to an order-of-magnitude faster inference than strong baselines.
Non-Rigid Structure-from-Motion via Differential Geometry with Recoverable Conformal Scale
Oct 02, 2025Non-rigid structure-from-motion (NRSfM), a promising technique for addressing the mapping challenges in monocular visual deformable simultaneous localization and mapping (SLAM), has attracted growing attention. We introduce a novel method, called Con-NRSfM, for NRSfM under conformal deformations, encompassing isometric deformations as a subset. Our approach performs point-wise reconstruction using 2D selected image warps optimized through a graph-based framework. Unlike existing methods that rely on strict assumptions, such as locally planar surfaces or locally linear deformations, and fail to recover the conformal scale, our method eliminates these constraints and accurately computes the local conformal scale. Additionally, our framework decouples constraints on depth and conformal scale, which are inseparable in other approaches, enabling more precise depth estimation. To address the sensitivity of the formulated problem, we employ a parallel separable iterative optimization strategy. Furthermore, a self-supervised learning framework, utilizing an encoder-decoder network, is incorporated to generate dense 3D point clouds with texture. Simulation and experimental results using both synthetic and real datasets demonstrate that our method surpasses existing approaches in terms of reconstruction accuracy and robustness. The code for the proposed method will be made publicly available on the project website: https://sites.google.com/view/con-nrsfm.
Image-Guided Shape-from-Template Using Mesh Inextensibility Constraints
Jul 30, 2025Shape-from-Template (SfT) refers to the class of methods that reconstruct the 3D shape of a deforming object from images/videos using a 3D template. Traditional SfT methods require point correspondences between images and the texture of the 3D template in order to reconstruct 3D shapes from images/videos in real time. Their performance severely degrades when encountered with severe occlusions in the images because of the unavailability of correspondences. In contrast, modern SfT methods use a correspondence-free approach by incorporating deep neural networks to reconstruct 3D objects, thus requiring huge amounts of data for supervision. Recent advances use a fully unsupervised or self-supervised approach by combining differentiable physics and graphics to deform 3D template to match input images. In this paper, we propose an unsupervised SfT which uses only image observations: color features, gradients and silhouettes along with a mesh inextensibility constraint to reconstruct at a $400\times$ faster pace than (best-performing) unsupervised SfT. Moreover, when it comes to generating finer details and severe occlusions, our method outperforms the existing methodologies by a large margin. Code is available at https://github.com/dvttran/nsft.
GAPS: Geometry-Aware, Physics-Based, Self-Supervised Neural Garment Draping
Dec 03, 2023



Recent neural, physics-based modeling of garment deformations allows faster and visually aesthetic results as opposed to the existing methods. Material-specific parameters are used by the formulation to control the garment inextensibility. This delivers unrealistic results with physically implausible stretching. Oftentimes, the draped garment is pushed inside the body which is either corrected by an expensive post-processing, thus adding to further inconsistent stretching; or by deploying a separate training regime for each body type, restricting its scalability. Additionally, the flawed skinning process deployed by existing methods produces incorrect results on loose garments. In this paper, we introduce a geometrical constraint to the existing formulation that is collision-aware and imposes garment inextensibility wherever possible. Thus, we obtain realistic results where draped clothes stretch only while covering bigger body regions. Furthermore, we propose a geometry-aware garment skinning method by defining a body-garment closeness measure which works for all garment types, especially the loose ones.
Temporally-Consistent Surface Reconstruction using Metrically-Consistent Atlases
Nov 12, 2021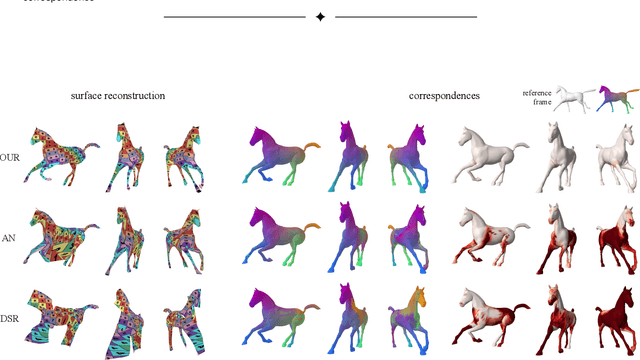
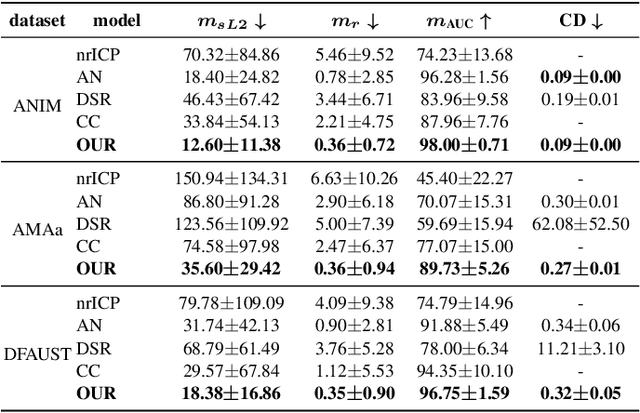
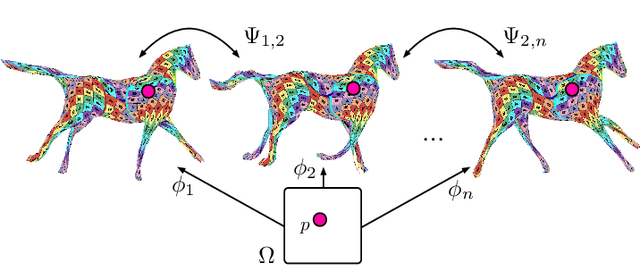
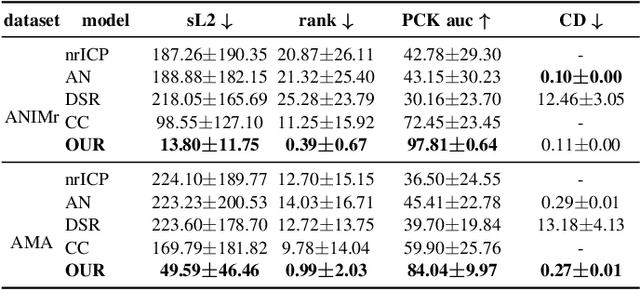
We propose a method for unsupervised reconstruction of a temporally-consistent sequence of surfaces from a sequence of time-evolving point clouds. It yields dense and semantically meaningful correspondences between frames. We represent the reconstructed surfaces as atlases computed by a neural network, which enables us to establish correspondences between frames. The key to making these correspondences semantically meaningful is to guarantee that the metric tensors computed at corresponding points are as similar as possible. We have devised an optimization strategy that makes our method robust to noise and global motions, without a priori correspondences or pre-alignment steps. As a result, our approach outperforms state-of-the-art ones on several challenging datasets. The code is available at https://github.com/bednarikjan/temporally_coherent_surface_reconstruction.
Temporally-Coherent Surface Reconstruction via Metric-Consistent Atlases
Apr 14, 2021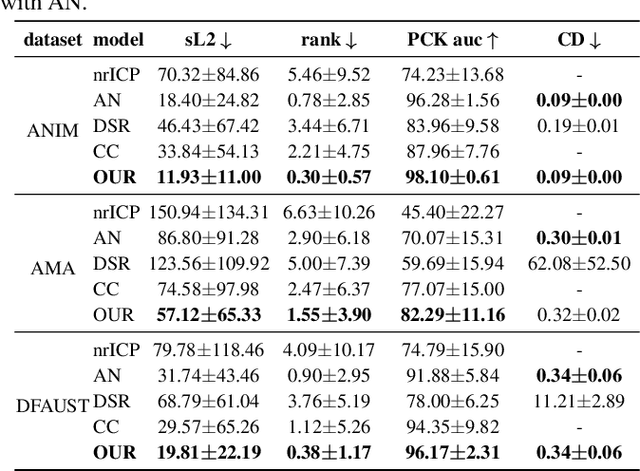
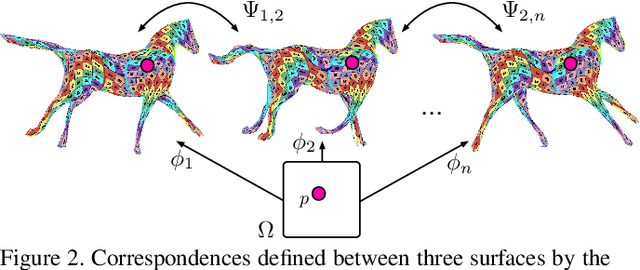

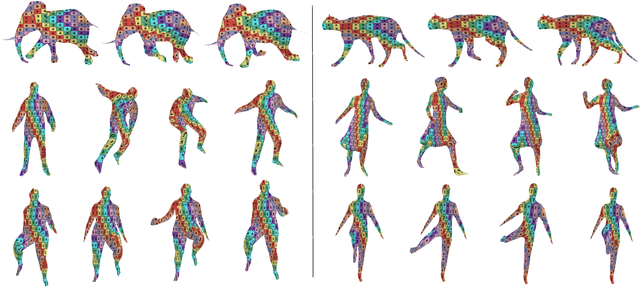
We propose a method for the unsupervised reconstruction of a temporally-coherent sequence of surfaces from a sequence of time-evolving point clouds, yielding dense, semantically meaningful correspondences between all keyframes. We represent the reconstructed surface as an atlas, using a neural network. Using canonical correspondences defined via the atlas, we encourage the reconstruction to be as isometric as possible across frames, leading to semantically-meaningful reconstruction. Through experiments and comparisons, we empirically show that our method achieves results that exceed that state of the art in the accuracy of unsupervised correspondences and accuracy of surface reconstruction.
A Closed-Form Solution to Local Non-Rigid Structure-from-Motion
Nov 23, 2020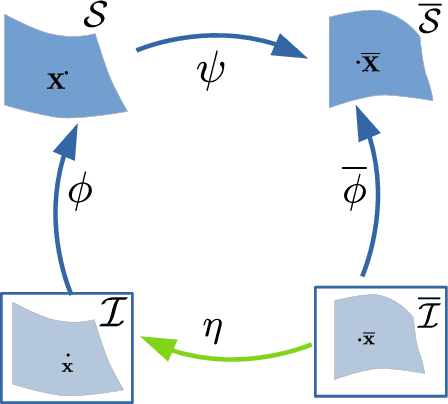
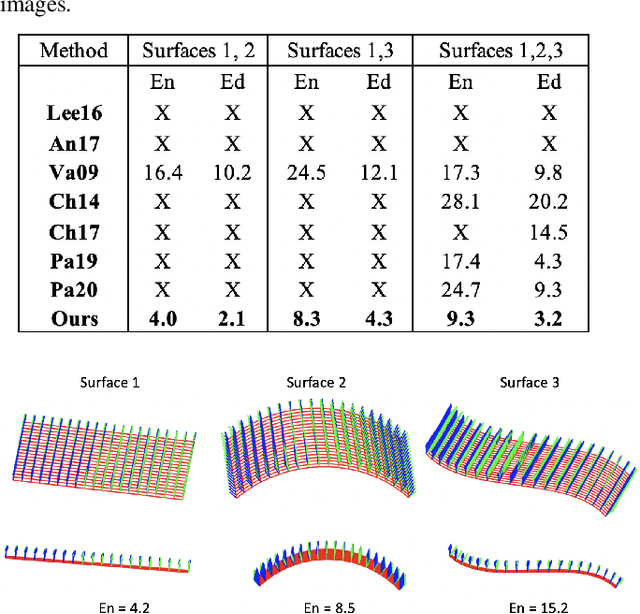

A recent trend in Non-Rigid Structure-from-Motion (NRSfM) is to express local, differential constraints between pairs of images, from which the surface normal at any point can be obtained by solving a system of polynomial equations. The systems of equations derived in previous work, however, are of high degree, having up to five real solutions, thus requiring a computationally expensive strategy to select a unique solution. Furthermore, they suffer from degeneracies that make the resulting estimates unreliable, without any mechanism to identify this situation. In this paper, we show that, under widely applicable assumptions, we can derive a new system of equation in terms of the surface normals whose two solutions can be obtained in closed-form and can easily be disambiguated locally. Our formalism further allows us to assess how reliable the estimated local normals are and, hence, to discard them if they are not. Our experiments show that our reconstructions, obtained from two or more views, are significantly more accurate than those of state-of-the-art methods, while also being faster.
Robust Isometric Non-Rigid Structure-from-Motion
Oct 09, 2020



Non-Rigid Structure-from-Motion (NRSfM) reconstructs a deformable 3D object from the correspondences established between monocular 2D images. Current NRSfM methods lack statistical robustness, which is the ability to cope with correspondence errors.This prevents one to use automatically established correspondences, which are prone to errors, thereby strongly limiting the scope of NRSfM. We propose a three-step automatic pipeline to solve NRSfM robustly by exploiting isometry. Step 1 computes the optical flow from correspondences, step 2 reconstructs each 3D point's normal vector using multiple reference images and integrates them to form surfaces with the best reference and step 3 rejects the 3D points that break isometry in their local neighborhood. Importantly, each step is designed to discard or flag erroneous correspondences. Our contributions include the robustification of optical flow by warp estimation, new fast analytic solutions to local normal reconstruction and their robustification, and a new scale-independent measure of 3D local isometric coherence. Experimental results show that our robust NRSfM method consistently outperforms existing methods on both synthetic and real datasets.
GarNet++: Improving Fast and Accurate Static3D Cloth Draping by Curvature Loss
Jul 20, 2020
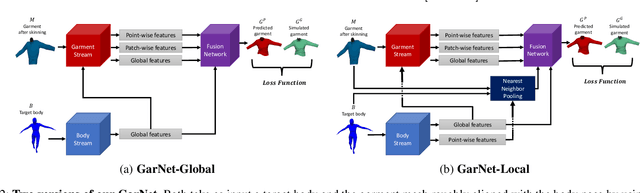
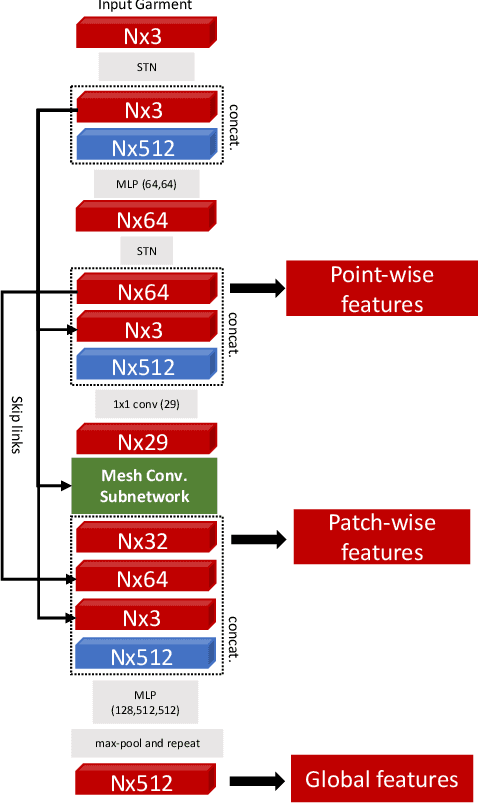
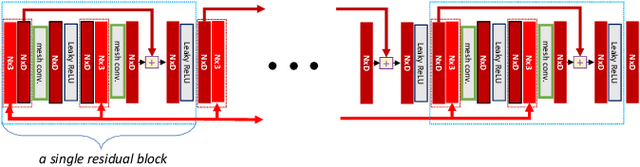
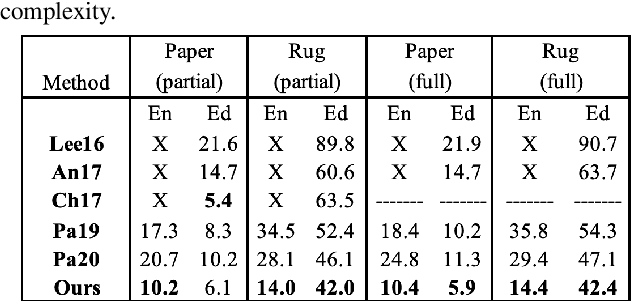
In this paper, we tackle the problem of static 3D cloth draping on virtual human bodies. We introduce a two-stream deep network model that produces a visually plausible draping of a template cloth on virtual 3D bodies by extracting features from both the body and garment shapes. Our network learns to mimic a Physics-Based Simulation (PBS) method while requiring two orders of magnitude less computation time. To train the network, we introduce loss terms inspired by PBS to produce plausible results and make the model collision-aware. To increase the details of the draped garment, we introduce two loss functions that penalize the difference between the curvature of the predicted cloth and PBS. Particularly, we study the impact of mean curvature normal and a novel detail-preserving loss both qualitatively and quantitatively. Our new curvature loss computes the local covariance matrices of the 3D points, and compares the Rayleigh quotients of the prediction and PBS. This leads to more details while performing favorably or comparably against the loss that considers mean curvature normal vectors in the 3D triangulated meshes. We validate our framework on four garment types for various body shapes and poses. Finally, we achieve superior performance against a recently proposed data-driven method.
Shape Reconstruction by Learning Differentiable Surface Representations
Nov 25, 2019
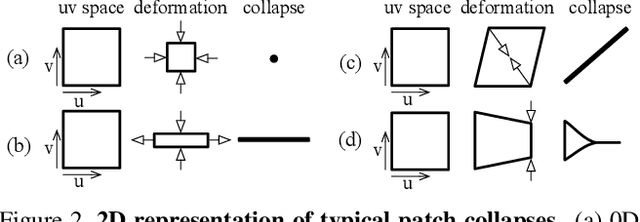
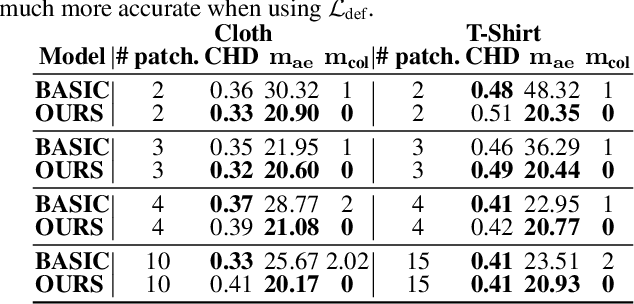
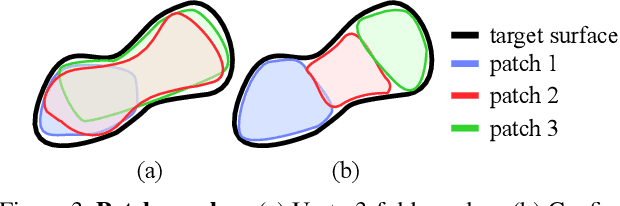
Generative models that produce point clouds have emerged as a powerful tool to represent 3D surfaces, and the best current ones rely on learning an ensemble of parametric representations. Unfortunately, they offer no control over the deformations of the surface patches that form the ensemble and thus fail to prevent them from either overlapping or collapsing into single points or lines. As a consequence, computing shape properties such as surface normals and curvatures becomes difficult and unreliable. In this paper, we show that we can exploit the inherent differentiability of deep networks to leverage differential surface properties during training so as to prevent patch collapse and strongly reduce patch overlap. Furthermore, this lets us reliably compute quantities such as surface normals and curvatures. We will demonstrate on several tasks that this yields more accurate surface reconstructions than the state-of-the-art methods in terms of normals estimation and amount of collapsed and overlapped patches.