 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Densification for Multi-Map Monocular VSLAM in Endoscopy
Mar 18, 2025Multi-map Sparse Monocular visual Simultaneous Localization and Mapping applied to monocular endoscopic sequences has proven efficient to robustly recover tracking after the frequent losses in endoscopy due to motion blur, temporal occlusion, tools interaction or water jets. The sparse multi-maps are adequate for robust camera localization, however they are very poor for environment representation, they are noisy, with a high percentage of inaccurately reconstructed 3D points, including significant outliers, and more importantly with an unacceptable low density for clinical applications. We propose a method to remove outliers and densify the maps of the state of the art for sparse endoscopy multi-map CudaSIFT-SLAM. The NN LightDepth for up-to-scale depth dense predictions are aligned with the sparse CudaSIFT submaps by means of the robust to spurious LMedS. Our system mitigates the inherent scale ambiguity in monocular depth estimation while filtering outliers, leading to reliable densified 3D maps. We provide experimental evidence of accurate densified maps 4.15 mm RMS accuracy at affordable computing time in the C3VD phantom colon dataset. We report qualitative results on the real colonoscopy from the Endomapper dataset.
LightDepth: Single-View Depth Self-Supervision from Illumination Decline
Aug 21, 2023



Single-view depth estimation can be remarkably effective if there is enough ground-truth depth data for supervised training. However, there are scenarios, especially in medicine in the case of endoscopies, where such data cannot be obtained. In such cases, multi-view self-supervision and synthetic-to-real transfer serve as alternative approaches, however, with a considerable performance reduction in comparison to supervised case. Instead, we propose a single-view self-supervised method that achieves a performance similar to the supervised case. In some medical devices, such as endoscopes, the camera and light sources are co-located at a small distance from the target surfaces. Thus, we can exploit that, for any given albedo and surface orientation, pixel brightness is inversely proportional to the square of the distance to the surface, providing a strong single-view self-supervisory signal. In our experiments, our self-supervised models deliver accuracies comparable to those of fully supervised ones, while being applicable without depth ground-truth data.
ColonMapper: topological mapping and localization for colonoscopy
May 09, 2023Mapping and localization in endoluminal cavities from colonoscopies or gastroscopies has to overcome the challenge of significant shape and illumination changes between reobservations of the same endoluminal location. Instead of geometrical maps that strongly rely on a fixed scene geometry, topological maps are more adequate because they focus on visual place recognition, i.e. the capability to determine if two video shots are imaging the same location. We propose a topological mapping and localization system able to operate on real human colonoscopies. The map is a graph where each node codes a colon location by a set of real images of that location. The edges represent traversability between two nodes. For close-in-time images, where scene changes are minor, place recognition can be successfully managed with the recent transformers-based image-matching algorithms. However, under long-term changes -- such as different colonoscopies of the same patient -- feature-based matching fails. To address this, we propose a GeM global descriptor able to achieve high recall with significant changes in the scene. The addition of a Bayesian filter processing the map graph boosts the accuracy of the long-term place recognition, enabling relocalization in a previously built map. In the experiments, we construct a map during the withdrawal phase of a first colonoscopy. Subsequently, we prove the ability to relocalize within this map during a second colonoscopy of the same patient two weeks later. Code and models will be available upon acceptance.
Photometric single-view dense 3D reconstruction in endoscopy
Apr 19, 2022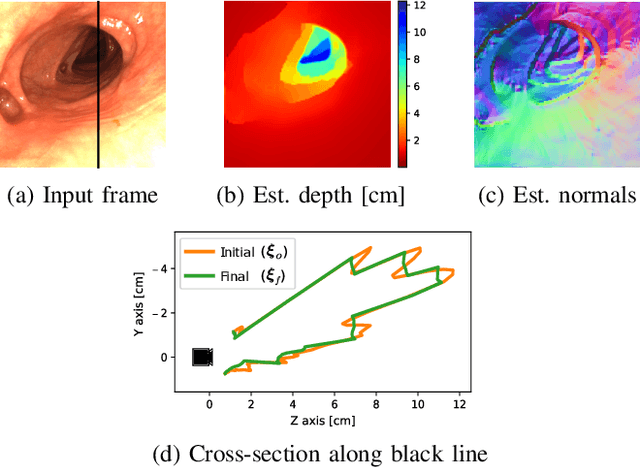
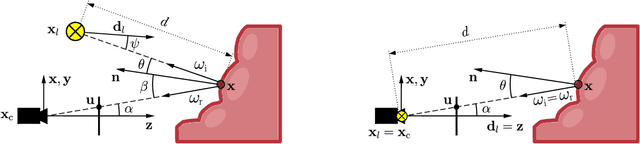
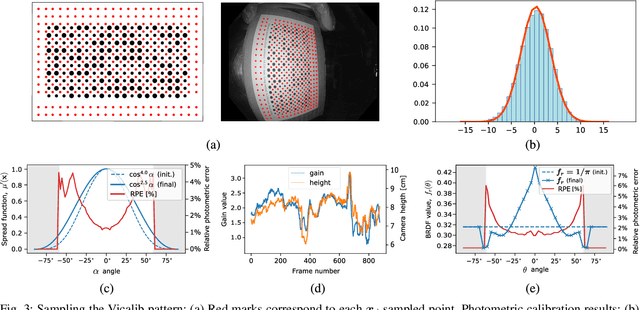

Visual SLAM inside the human body will open the way to computer-assisted navigation in endoscopy. However, due to space limitations, medical endoscopes only provide monocular images, leading to systems lacking true scale. In this paper, we exploit the controlled lighting in colonoscopy to achieve the first in-vivo 3D reconstruction of the human colon using photometric stereo on a calibrated monocular endoscope. Our method works in a real medical environment, providing both a suitable in-place calibration procedure and a depth estimation technique adapted to the colon's tubular geometry. We validate our method on simulated colonoscopies, obtaining a mean error of 7% on depth estimation, which is below 3 mm on average. Our qualitative results on the EndoMapper dataset show that the method is able to correctly estimate the colon shape in real human colonoscopies, paving the ground for true-scale monocular SLAM in endoscopy.
Reuse your features: unifying retrieval and feature-metric alignment
Apr 13, 2022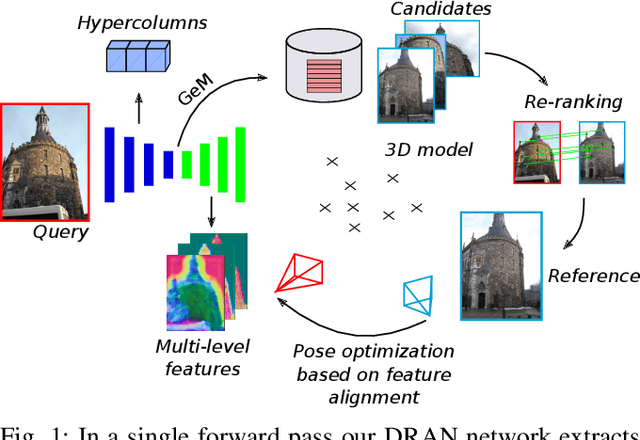
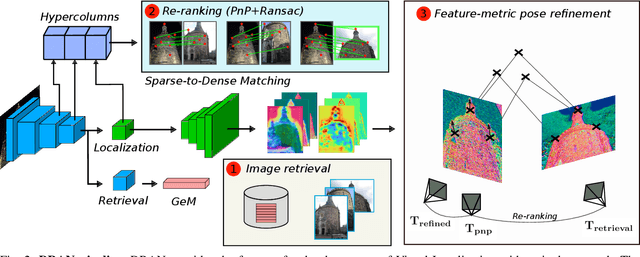
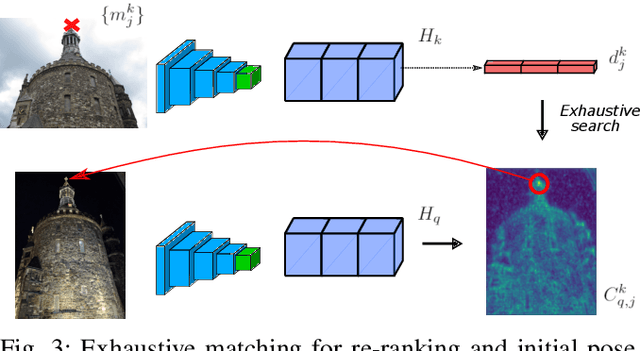
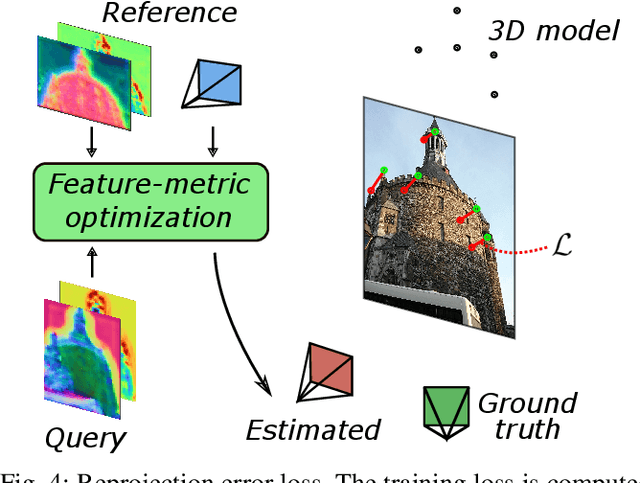
We propose a compact pipeline to unify all the steps of Visual Localization: image retrieval, candidate re-ranking and initial pose estimation, and camera pose refinement. Our key assumption is that the deep features used for these individual tasks share common characteristics, so we should reuse them in all the procedures of the pipeline. Our DRAN (Deep Retrieval and image Alignment Network) is able to extract global descriptors for efficient image retrieval, use intermediate hierarchical features to re-rank the retrieval list and produce an intial pose guess, which is finally refined by means of a feature-metric optimization based on learned deep multi-scale dense features. DRAN is the first single network able to produce the features for the three steps of visual localization. DRAN achieves a competitive performance in terms of robustness and accuracy specially in extreme day-night changes.
Direct and Sparse Deformable Tracking
Sep 15, 2021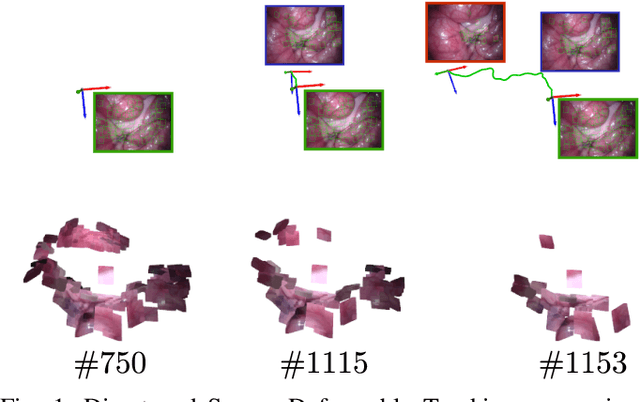
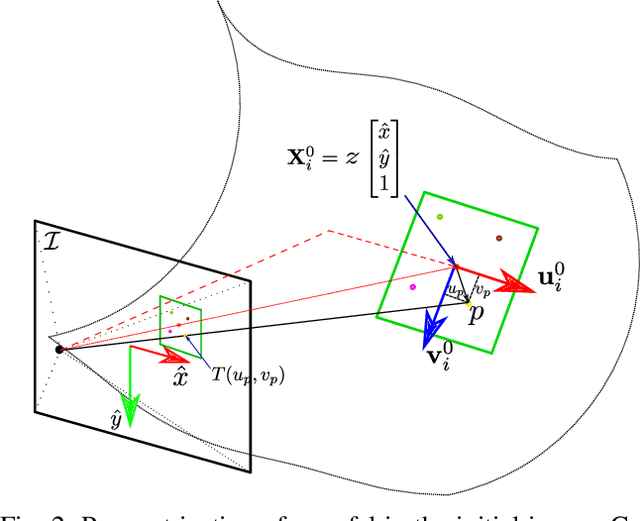
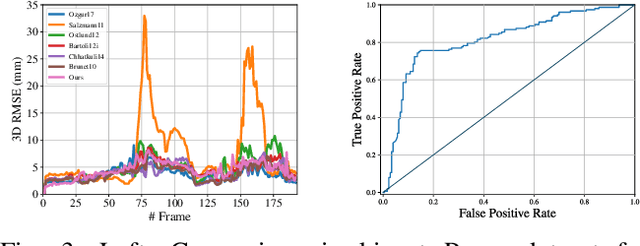
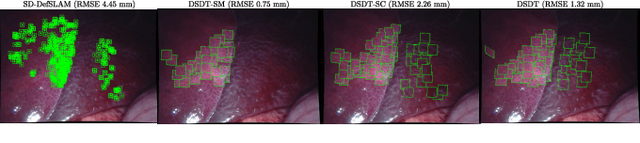
Deformable Monocular SLAM algorithms recover the localization of a camera in an unknown deformable environment. Current approaches use a template-based deformable tracking to recover the camera pose and the deformation of the map. These template-based methods use an underlying global deformation model. In this paper, we introduce a novel deformable camera tracking method with a local deformation model for each point. Each map point is defined as a single textured surfel that moves independently of the other map points. Thanks to a direct photometric error cost function, we can track the position and orientation of the surfel without an explicit global deformation model. In our experiments, we validate the proposed system and observe that our local deformation model estimates more accurately and robustly the targeted deformations of the map in both laboratory-controlled experiments and in-body scenarios undergoing non-isometric deformations, with changing topology or discontinuities.
Endo-Depth-and-Motion: Localization and Reconstruction in Endoscopic Videos using Depth Networks and Photometric Constraints
Mar 30, 2021



Estimating a scene reconstruction and the camera motion from in-body videos is challenging due to several factors, e.g. the deformation of in-body cavities or the lack of texture. In this paper we present Endo-Depth-and-Motion, a pipeline that estimates the 6-degrees-of-freedom camera pose and dense 3D scene models from monocular endoscopic videos. Our approach leverages recent advances in self-supervised depth networks to generate pseudo-RGBD frames, then tracks the camera pose using photometric residuals and fuses the registered depth maps in a volumetric representation. We present an extensive experimental evaluation in the public dataset Hamlyn, showing high-quality results and comparisons against relevant baselines. We also release all models and code for future comparisons.
ORBSLAM-Atlas: a robust and accurate multi-map system
Aug 30, 2019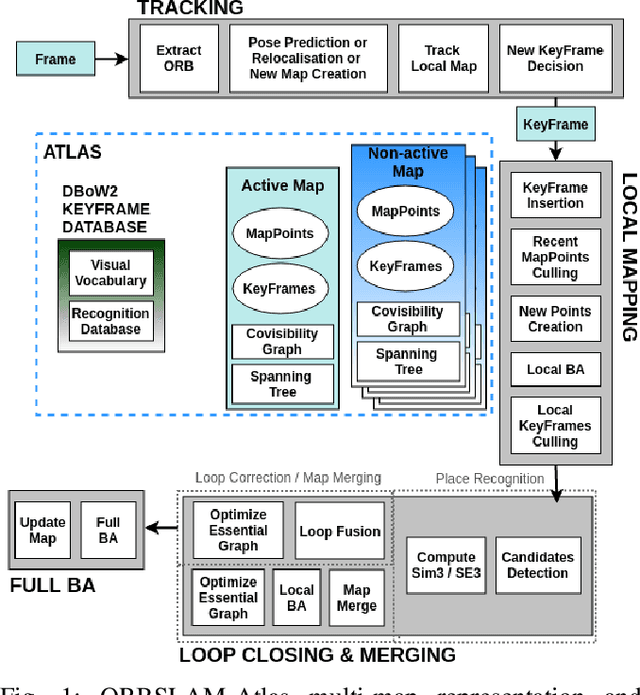
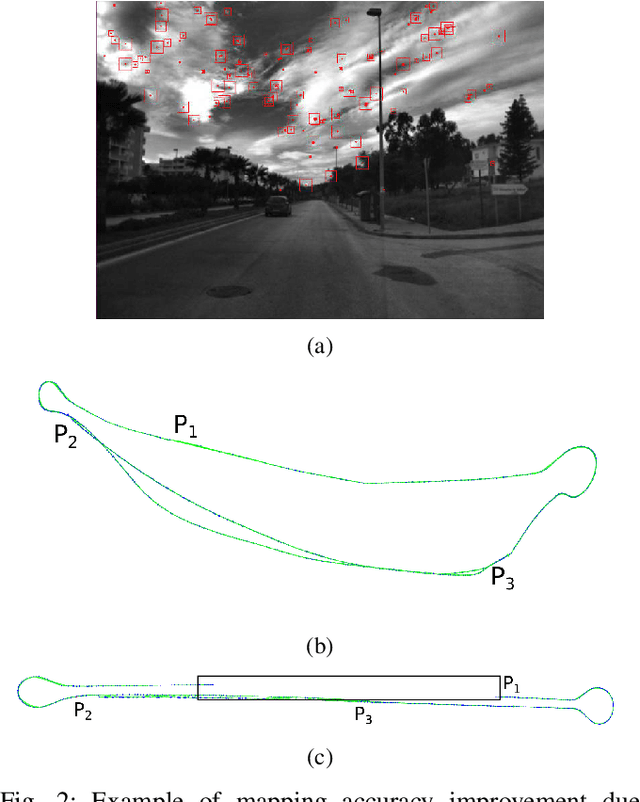
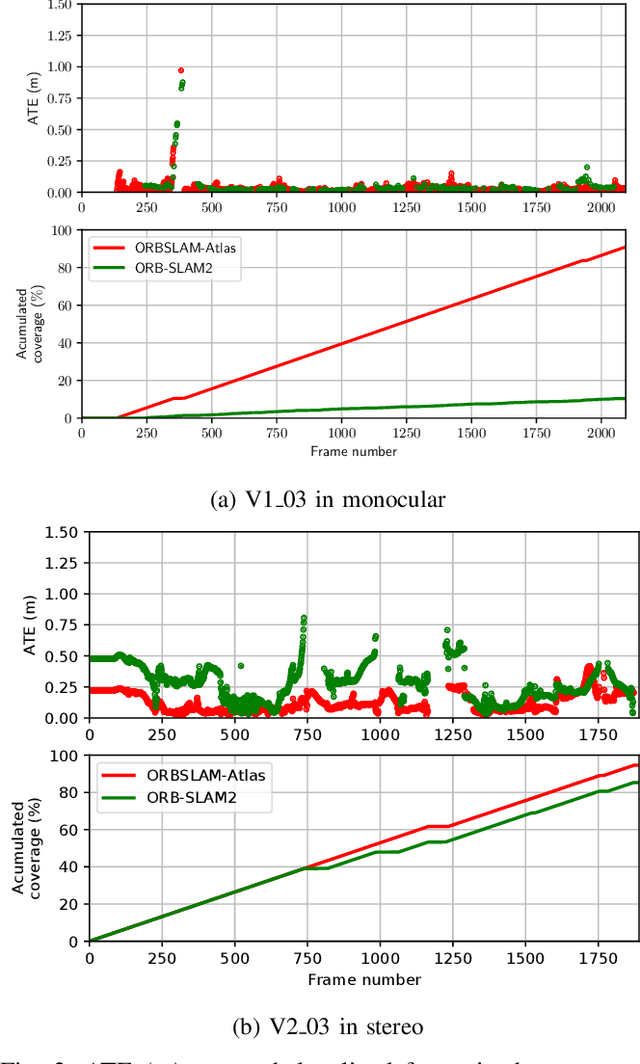
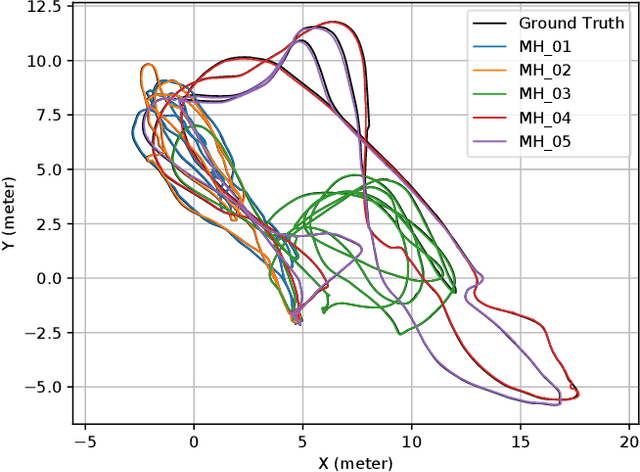
We propose ORBSLAM-Atlas, a system able to handle an unlimited number of disconnected sub-maps, that includes a robust map merging algorithm able to detect sub-maps with common regions and seamlessly fuse them. The outstanding robustness and accuracy of ORBSLAM are due to its ability to detect wide-baseline matches between keyframes, and to exploit them by means of non-linear optimization, however it only can handle a single map. ORBSLAM-Atlas brings the wide-baseline matching detection and exploitation to the multiple map arena. The result is a SLAM system significantly more general and robust, able to perform multi-session mapping. If tracking is lost during exploration, instead of freezing the map, a new sub-map is launched, and it can be fused with the previous map when common parts are visited. Our criteria to declare the camera lost contrast with previous approaches that simply count the number of tracked points, we propose to discard also inaccurately estimated camera poses due to bad geometrical conditioning. As a result, the map is split into more accurate sub-maps, that are eventually merged in a more accurate global map, thanks to the multi-mapping capabilities. We provide extensive experimental validation in the EuRoC datasets, where ORBSLAM-Atlas obtains accurate monocular and stereo results in the difficult sequences where ORBSLAM failed. We also build global maps after multiple sessions in the same room, obtaining the best results to date, between 2 and 3 times more accurate than competing multi-map approaches. We also show the robustness and capability of our system to deal with dynamic scenes, quantitatively in the EuRoC datasets and qualitatively in a densely populated corridor where camera occlusions and tracking losses are frequent.
Fast and Robust Initialization for Visual-Inertial SLAM
Aug 28, 2019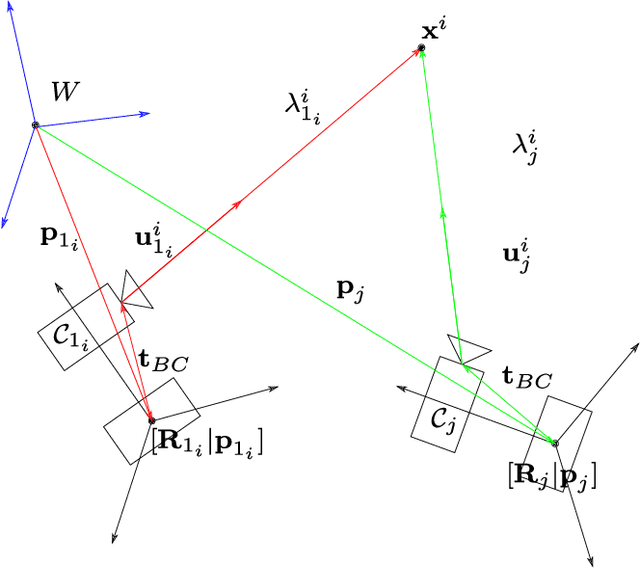
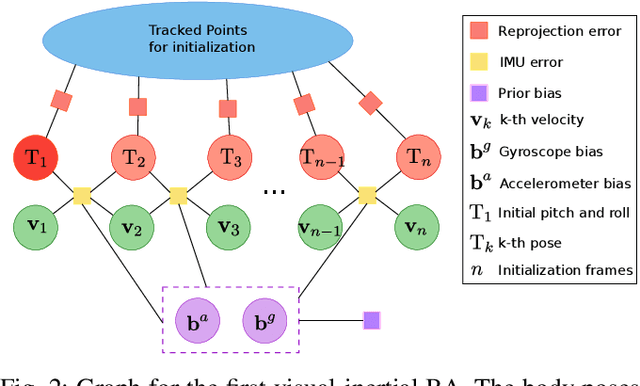
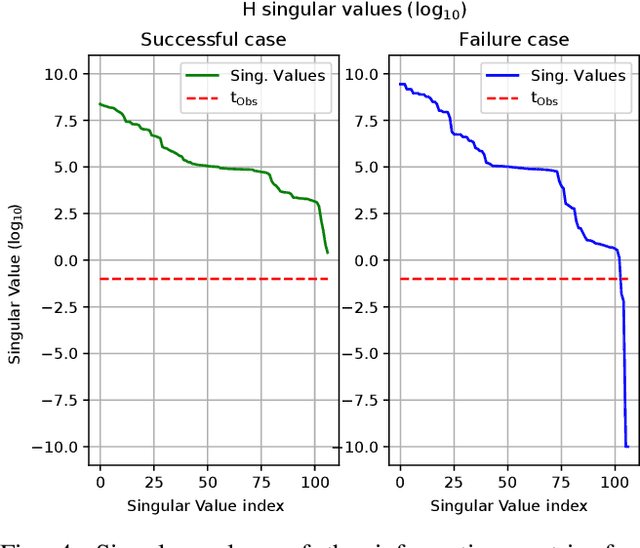
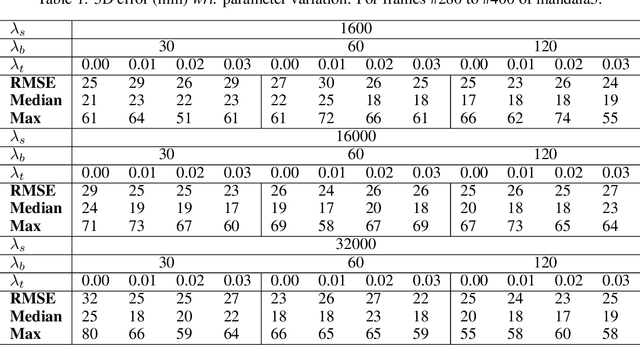
Visual-inertial SLAM (VI-SLAM) requires a good initial estimation of the initial velocity, orientation with respect to gravity and gyroscope and accelerometer biases. In this paper we build on the initialization method proposed by Martinelli and extended by Kaiser et al. , modifying it to be more general and efficient. We improve accuracy with several rounds of visual-inertial bundle adjustment, and robustify the method with novel observability and consensus tests, that discard erroneous solutions. Our results on the EuRoC dataset show that, while the original method produces scale errors up to 156%, our method is able to consistently initialize in less than two seconds with scale errors around 5%, which can be further reduced to less than 1% performing visual-inertial bundle adjustment after ten seconds.
* 2019 International Conference on Robotics and Automation
DefSLAM: Tracking and Mapping of Deforming Scenes from Monocular Sequences
Aug 20, 2019
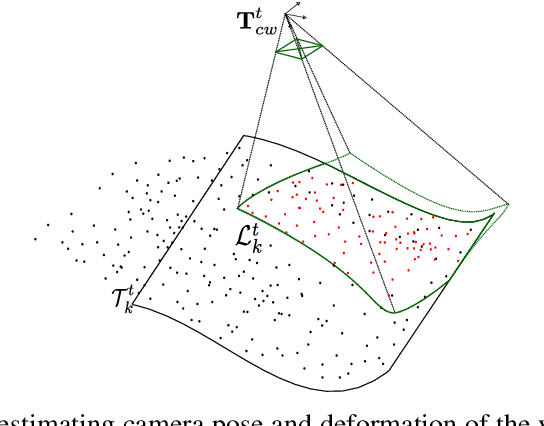
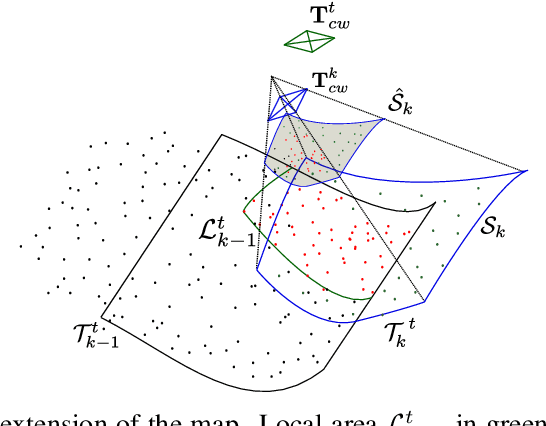
We present the first monocular SLAM capable of operating in deforming scenes in real-time. Our DefSLAM approach fuses isometric Shape-from-Template (SfT) and Non-Rigid Structure-from-Motion (NRSfM) techniques to deal with the exploratory sequences typical of SLAM. A deformation tracking thread recovers the pose of the camera and the deformation of the observed map at frame rate by means of SfT. A deformation mapping thread runs in parallel to update the template at keyframe rate by means of NRSfM with a batch of covisible keyframes. In our experiments, DefSLAM processes sequences of deforming scenes both in a laboratory controlled experiment and in medical endoscopy sequences, being able to produce accurate 3D models of the scene with respect to the moving camera.