 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-aware direct monocular odometry
Sep 21, 2021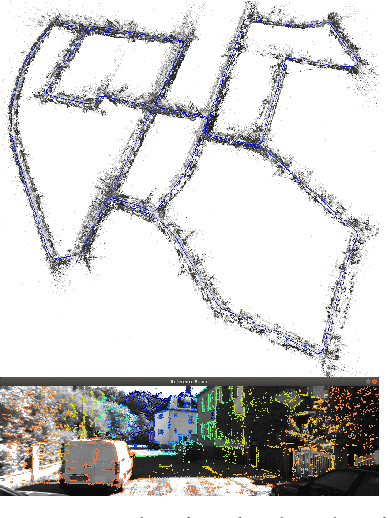
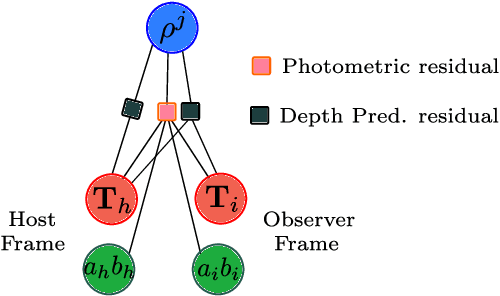
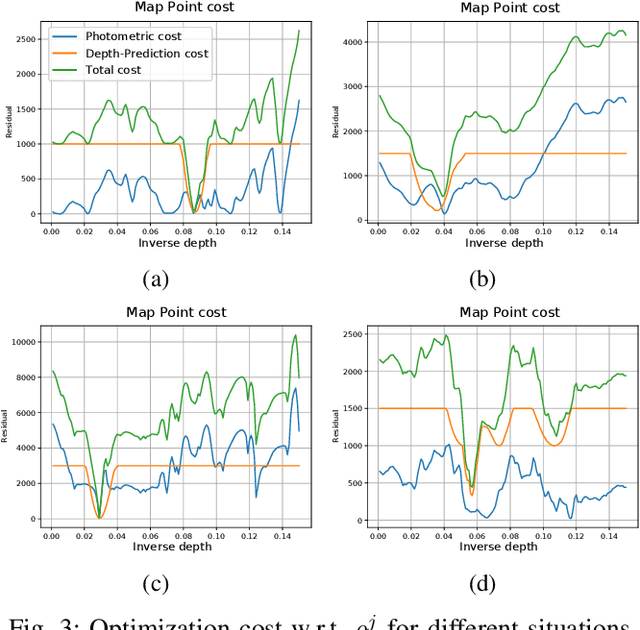
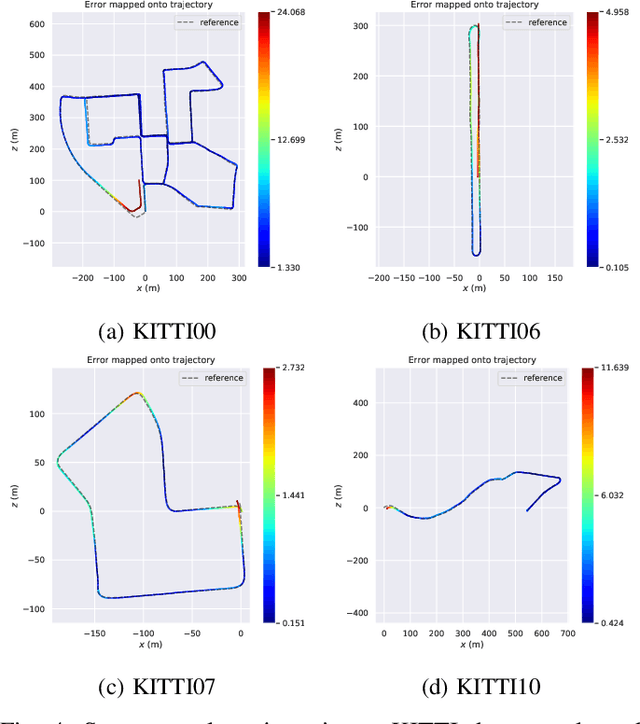
We present a framework for direct monocular odometry based on depth prediction from a deep neural network. In contrast with existing methods where depth information is only partially exploited, we formulate a novel depth prediction residual which allows us to incorporate multi-view depth information. In addition, we propose to use a truncated robust cost function which prevents considering inconsistent depth estimations. The photometric and depth-prediction measurements are integrated in a tightly-coupled optimization leading to a scale-aware monocular system which does not accumulate scale drift. We demonstrate the validity of our proposal evaluating it on the KITTI odometry dataset and comparing it with state-of-the-art monocular and stereo SLAM systems. Experiments show that our proposal largely outperforms classic monocular SLAM, being 5 to 9 times more precise, with an accuracy which is closer to that of stereo systems.
DynaSLAM II: Tightly-Coupled Multi-Object Tracking and SLAM
Oct 15, 2020
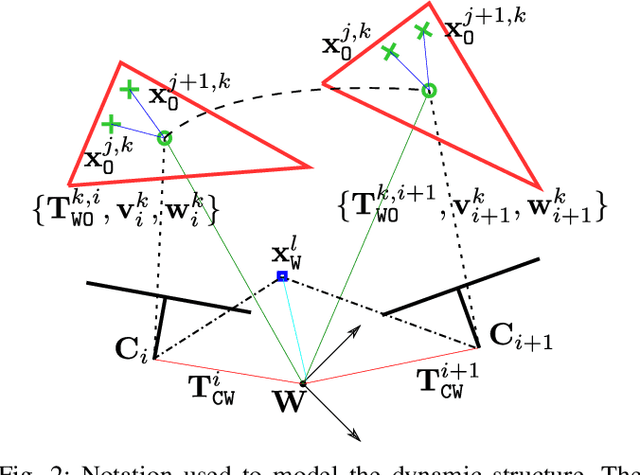
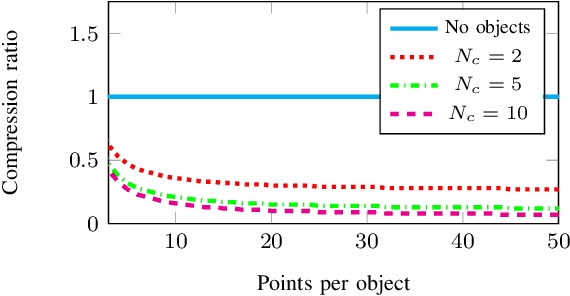
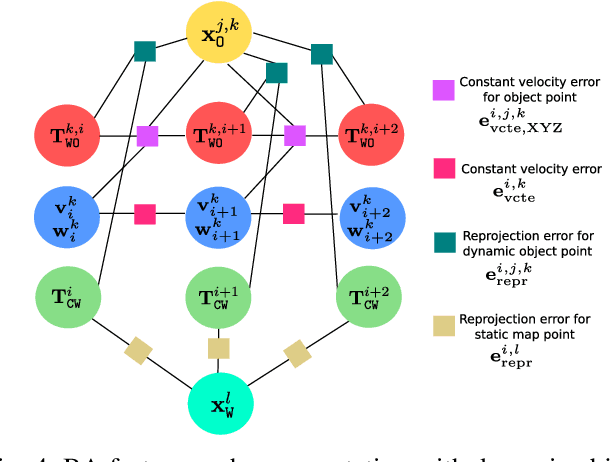
The assumption of scene rigidity is common in visual SLAM algorithms. However, it limits their applicability in populated real-world environments. Furthermore, most scenarios including autonomous driving, multi-robot collaboration and augmented/virtual reality, require explicit motion information of the surroundings to help with decision making and scene understanding. We present in this paper DynaSLAM II, a visual SLAM system for stereo and RGB-D configurations that tightly integrates the multi-object tracking capability. DynaSLAM II makes use of instance semantic segmentation and of ORB features to track dynamic objects. The structure of the static scene and of the dynamic objects is optimized jointly with the trajectories of both the camera and the moving agents within a novel bundle adjustment proposal. The 3D bounding boxes of the objects are also estimated and loosely optimized within a fixed temporal window. We demonstrate that tracking dynamic objects does not only provide rich clues for scene understanding but is also beneficial for camera tracking. The project code will be released upon acceptance.
ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual-Inertial and Multi-Map SLAM
Jul 23, 2020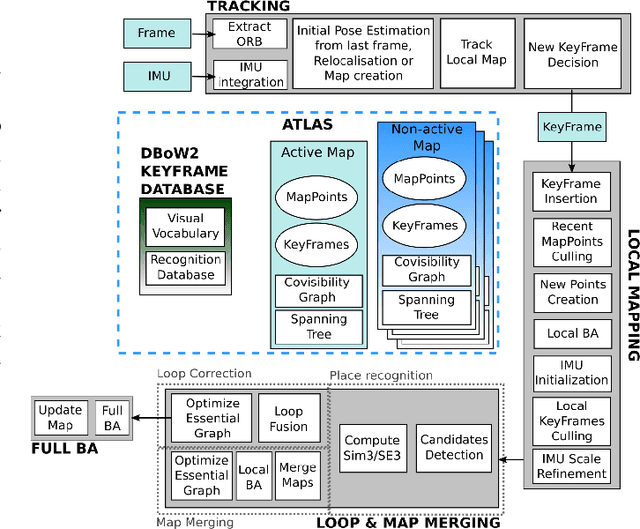
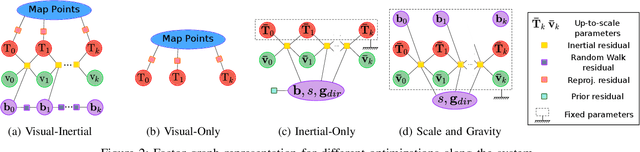
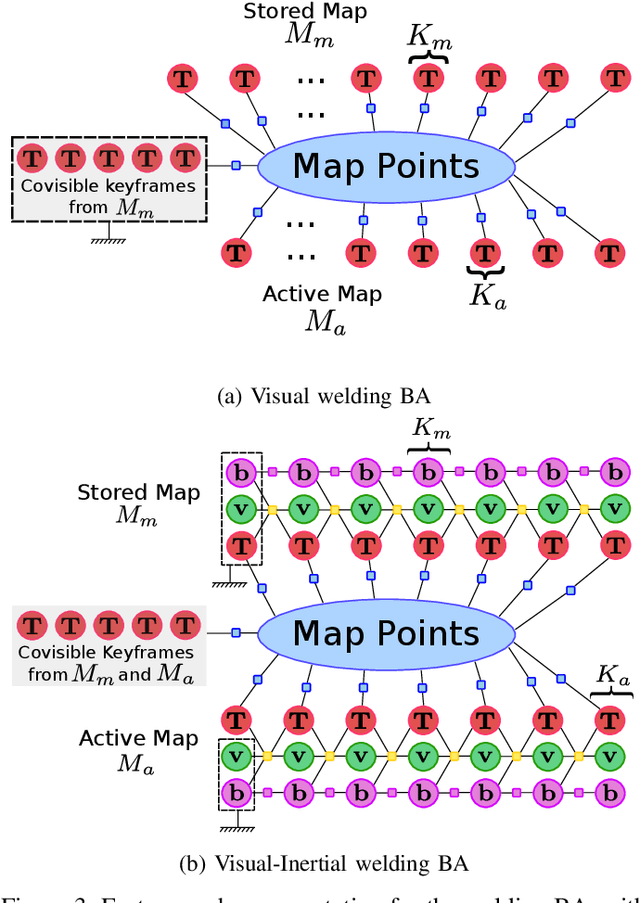
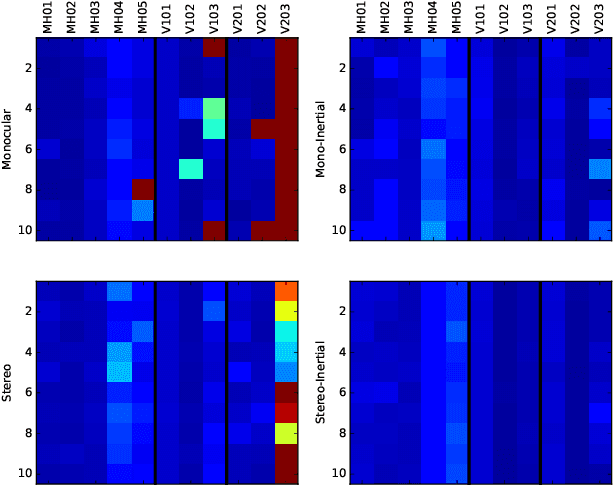
This paper presents ORB-SLAM3, the first system able to perform visual, visual-inertial and multi-map SLAM with monocular, stereo and RGB-D cameras, using pin-hole and fisheye lens models. The first main novelty is a feature-based tightly-integrated visual-inertial SLAM system that fully relies on Maximum-a-Posteriori (MAP) estimation, even during the IMU initialization phase. The result is a system that operates robustly in real-time, in small and large, indoor and outdoor environments, and is 2 to 5 times more accurate than previous approaches. The second main novelty is a multiple map system that relies on a new place recognition method with improved recall. Thanks to it, ORB-SLAM3 is able to survive to long periods of poor visual information: when it gets lost, it starts a new map that will be seamlessly merged with previous maps when revisiting mapped areas. Compared with visual odometry systems that only use information from the last few seconds, ORB-SLAM3 is the first system able to reuse in all the algorithm stages all previous information. This allows to include in bundle adjustment co-visible keyframes, that provide high parallax observations boosting accuracy, even if they are widely separated in time or if they come from a previous mapping session. Our experiments show that, in all sensor configurations, ORB-SLAM3 is as robust as the best systems available in the literature, and significantly more accurate. Notably, our stereo-inertial SLAM achieves an average accuracy of 3.6 cm on the EuRoC drone and 9 mm under quick hand-held motions in the room of TUM-VI dataset, a setting representative of AR/VR scenarios. For the benefit of the community we make public the source code.
Inertial-Only Optimization for Visual-Inertial Initialization
Mar 12, 2020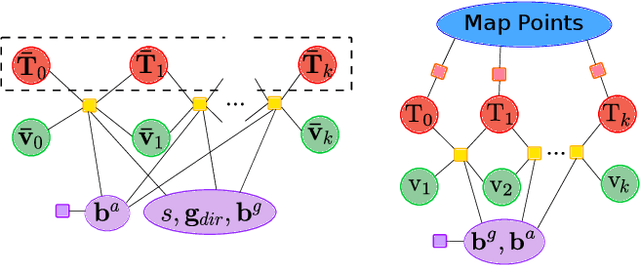
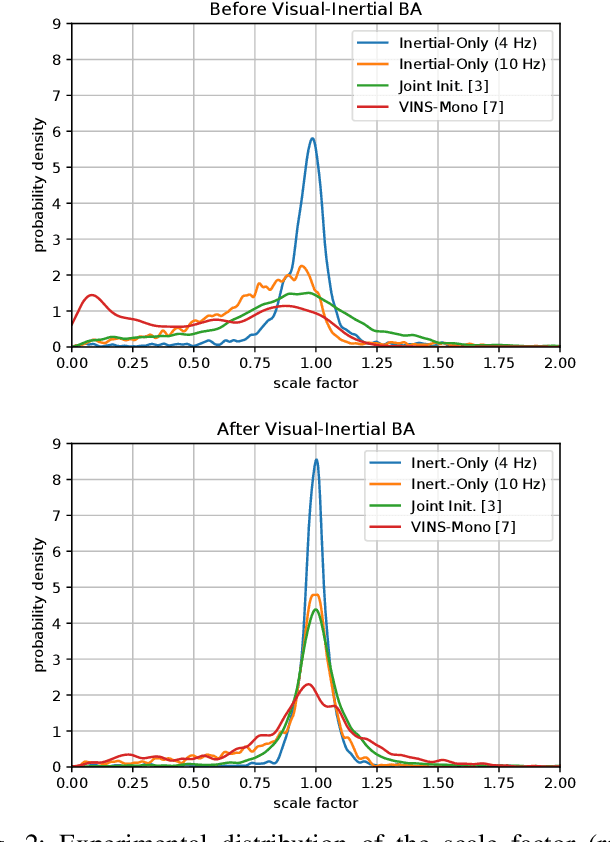
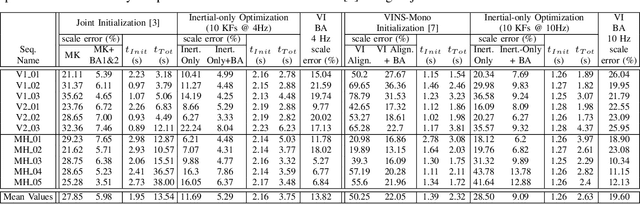
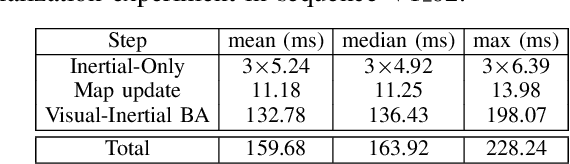
We formulate for the first time visual-inertial initialization as an optimal estimation problem, in the sense of maximum-a-posteriori (MAP) estimation. This allows us to properly take into account IMU measurement uncertainty, which was neglected in previous methods that either solved sets of algebraic equations, or minimized ad-hoc cost functions using least squares. Our exhaustive initialization tests on EuRoC dataset show that our proposal largely outperforms the best methods in the literature, being able to initialize in less than 4 seconds in almost any point of the trajectory, with a scale error of 5.3% on average. This initialization has been integrated into ORB-SLAM Visual-Inertial boosting its robustness and efficiency while maintaining its excellent accuracy.
Fast and Robust Initialization for Visual-Inertial SLAM
Aug 28, 2019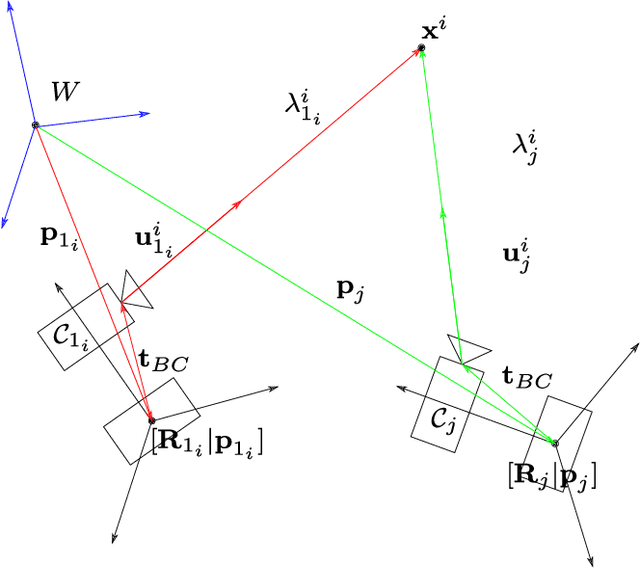
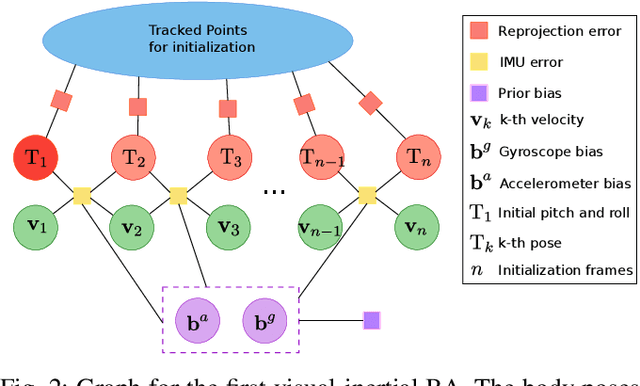
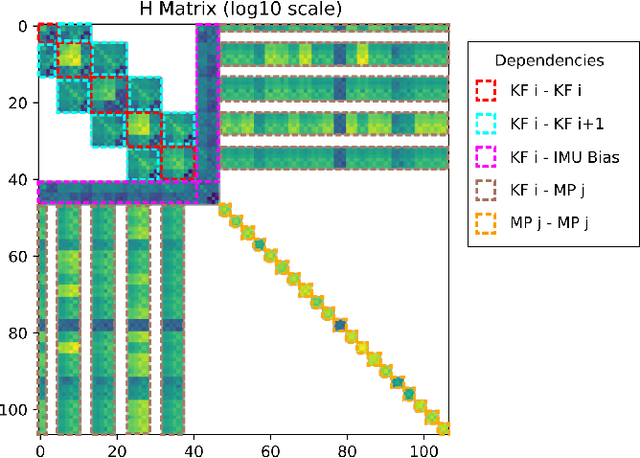
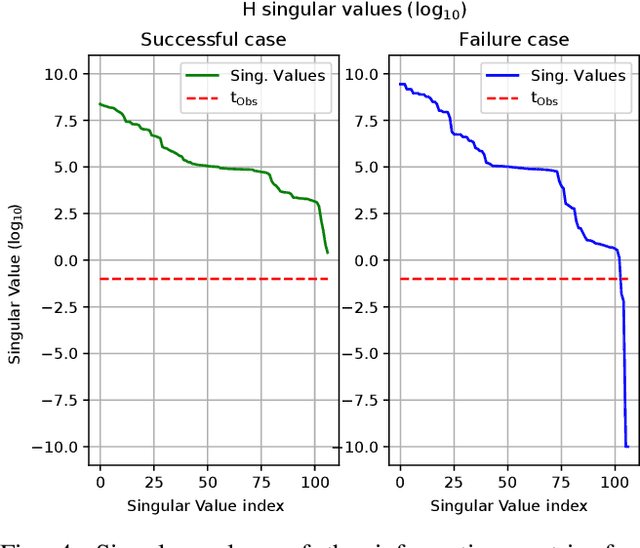
Visual-inertial SLAM (VI-SLAM) requires a good initial estimation of the initial velocity, orientation with respect to gravity and gyroscope and accelerometer biases. In this paper we build on the initialization method proposed by Martinelli and extended by Kaiser et al. , modifying it to be more general and efficient. We improve accuracy with several rounds of visual-inertial bundle adjustment, and robustify the method with novel observability and consensus tests, that discard erroneous solutions. Our results on the EuRoC dataset show that, while the original method produces scale errors up to 156%, our method is able to consistently initialize in less than two seconds with scale errors around 5%, which can be further reduced to less than 1% performing visual-inertial bundle adjustment after ten seconds.
* 2019 International Conference on Robotics and Automation