 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaSLAM II: Tightly-Coupled Multi-Object Tracking and SLAM
Oct 15, 2020
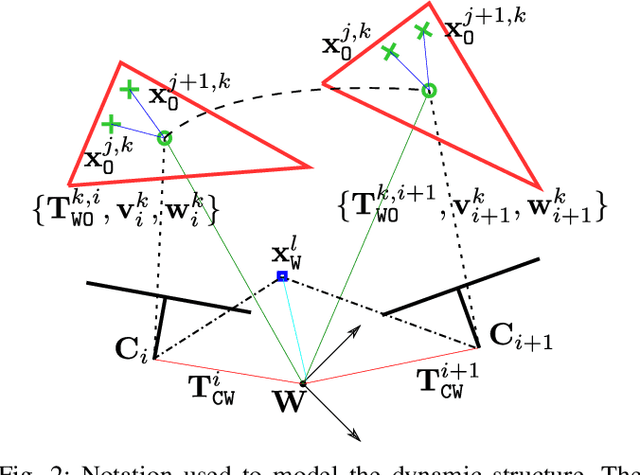
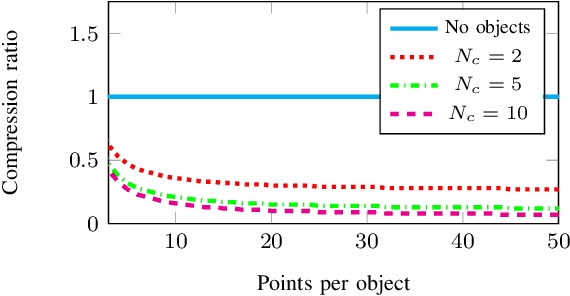
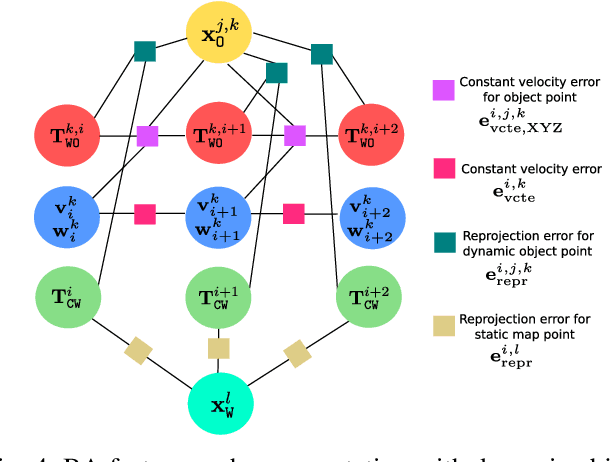
The assumption of scene rigidity is common in visual SLAM algorithms. However, it limits their applicability in populated real-world environments. Furthermore, most scenarios including autonomous driving, multi-robot collaboration and augmented/virtual reality, require explicit motion information of the surroundings to help with decision making and scene understanding. We present in this paper DynaSLAM II, a visual SLAM system for stereo and RGB-D configurations that tightly integrates the multi-object tracking capability. DynaSLAM II makes use of instance semantic segmentation and of ORB features to track dynamic objects. The structure of the static scene and of the dynamic objects is optimized jointly with the trajectories of both the camera and the moving agents within a novel bundle adjustment proposal. The 3D bounding boxes of the objects are also estimated and loosely optimized within a fixed temporal window. We demonstrate that tracking dynamic objects does not only provide rich clues for scene understanding but is also beneficial for camera tracking. The project code will be released upon acceptance.
Empty Cities: Image Inpainting for a Dynamic-Object-Invariant Space
Sep 20, 2018
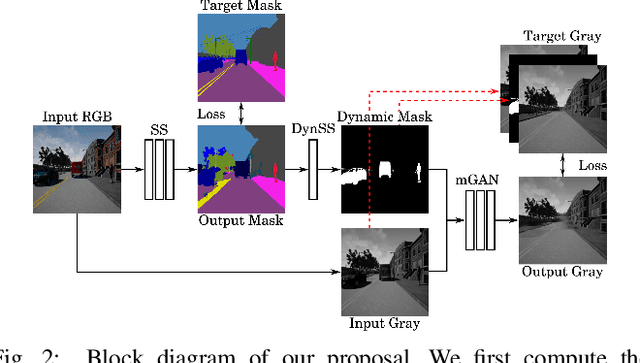

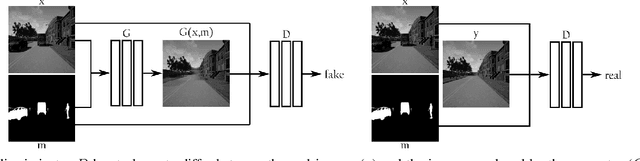
In this paper we present an end-to-end deep learning framework to turn images that show dynamic content, such as vehicles or pedestrians, into realistic static frames. This objective encounters two main challenges: detecting the dynamic objects, and inpainting the static occluded background. The second challenge is approached with a conditional generative adversarial model that, taking as input the original dynamic image and the computed dynamic/static binary mask, is capable of generating the final static image. The former challenge is addressed by the use of a convolutional network that learns a multi-class semantic segmentation of the image. The objective of this network is producing an accurate segmentation and helping the previous generative model to output a realistic static image. These generated images can be used for applications such as virtual reality or vision-based robot localization purposes. To validate our approach, we show both qualitative and quantitative comparisons against other inpainting methods by removing the dynamic objects and hallucinating the static structure behind them. Furthermore, to demonstrate the potential of our results, we conduct pilot experiments showing the benefits of our proposal for visual place recognition. Code has been made available on https://github.com/bertabescos/EmptyCities.
DynaSLAM: Tracking, Mapping and Inpainting in Dynamic Scenes
Aug 15, 2018

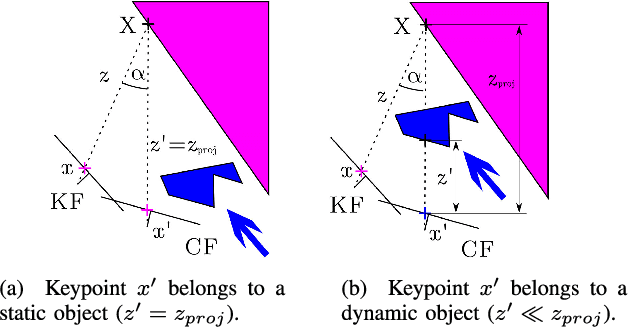

The assumption of scene rigidity is typical in SLAM algorithms. Such a strong assumption limits the use of most visual SLAM systems in populated real-world environments, which are the target of several relevant applications like service robotics or autonomous vehicles. In this paper we present DynaSLAM, a visual SLAM system that, building over ORB-SLAM2 [1], adds the capabilities of dynamic object detection and background inpainting. DynaSLAM is robust in dynamic scenarios for monocular, stereo and RGB-D configurations. We are capable of detecting the moving objects either by multi-view geometry, deep learning or both. Having a static map of the scene allows inpainting the frame background that has been occluded by such dynamic objects. We evaluate our system in public monocular, stereo and RGB-D datasets. We study the impact of several accuracy/speed trade-offs to assess the limits of the proposed methodology. DynaSLAM outperforms the accuracy of standard visual SLAM baselines in highly dynamic scenarios. And it also estimates a map of the static parts of the scene, which is a must for long-term applications in real-world environments.
* This work has been accepted at IEEE Robotics and Automation Letters, and will be presented at the IEEE Conference on Intelligent Robots and Systems 2018
Dynamic Objects Segmentation for Visual Localization in Urban Environments
Jul 09, 2018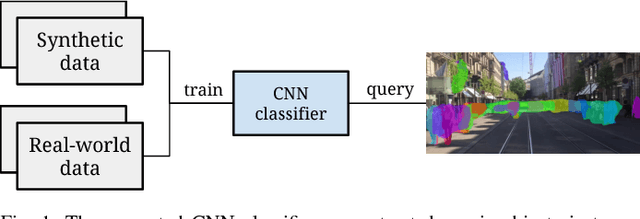
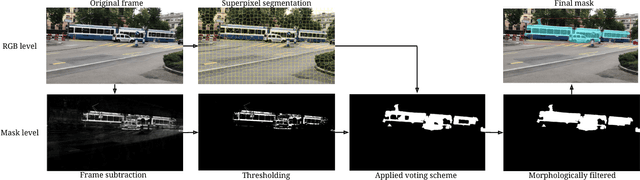
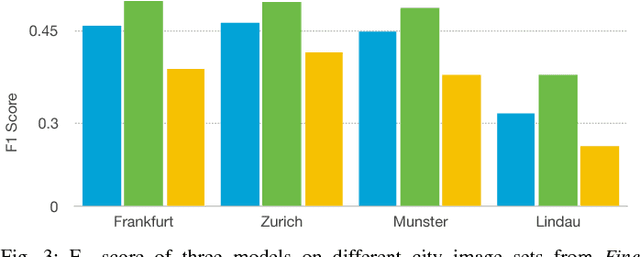

Visual localization and mapping is a crucial capability to address many challenges in mobile robotics. It constitutes a robust, accurate and cost-effective approach for local and global pose estimation within prior maps. Yet, in highly dynamic environments, like crowded city streets, problems arise as major parts of the image can be covered by dynamic objects. Consequently, visual odometry pipelines often diverge and the localization systems malfunction as detected features are not consistent with the precomputed 3D model. In this work, we present an approach to automatically detect dynamic object instances to improve the robustness of vision-based localization and mapping in crowded environments. By training a convolutional neural network model with a combination of synthetic and real-world data, dynamic object instance masks are learned in a semi-supervised way. The real-world data can be collected with a standard camera and requires minimal further post-processing. Our experiments show that a wide range of dynamic objects can be reliably detected using the presented method. Promising performance is demonstrated on our own and also publicly available datasets, which also shows the generalization capabilities of this approach.