 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpty Cities: Image Inpainting for a Dynamic-Object-Invariant Space
Paper and Code

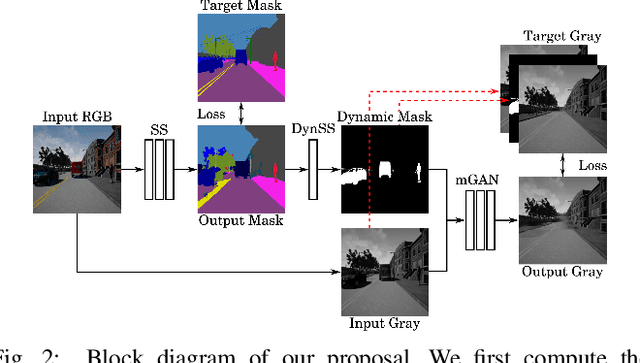

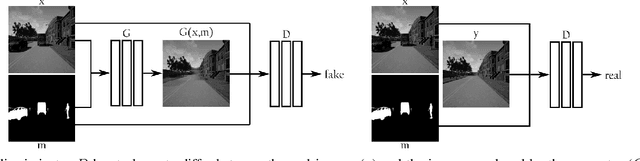
In this paper we present an end-to-end deep learning framework to turn images that show dynamic content, such as vehicles or pedestrians, into realistic static frames. This objective encounters two main challenges: detecting the dynamic objects, and inpainting the static occluded background. The second challenge is approached with a conditional generative adversarial model that, taking as input the original dynamic image and the computed dynamic/static binary mask, is capable of generating the final static image. The former challenge is addressed by the use of a convolutional network that learns a multi-class semantic segmentation of the image. The objective of this network is producing an accurate segmentation and helping the previous generative model to output a realistic static image. These generated images can be used for applications such as virtual reality or vision-based robot localization purposes. To validate our approach, we show both qualitative and quantitative comparisons against other inpainting methods by removing the dynamic objects and hallucinating the static structure behind them. Furthermore, to demonstrate the potential of our results, we conduct pilot experiments showing the benefits of our proposal for visual place recognition. Code has been made available on https://github.com/bertabescos/EmptyCities.