 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEndo-Depth-and-Motion: Localization and Reconstruction in Endoscopic Videos using Depth Networks and Photometric Constraints
Mar 30, 2021



Estimating a scene reconstruction and the camera motion from in-body videos is challenging due to several factors, e.g. the deformation of in-body cavities or the lack of texture. In this paper we present Endo-Depth-and-Motion, a pipeline that estimates the 6-degrees-of-freedom camera pose and dense 3D scene models from monocular endoscopic videos. Our approach leverages recent advances in self-supervised depth networks to generate pseudo-RGBD frames, then tracks the camera pose using photometric residuals and fuses the registered depth maps in a volumetric representation. We present an extensive experimental evaluation in the public dataset Hamlyn, showing high-quality results and comparisons against relevant baselines. We also release all models and code for future comparisons.
Single-View Place Recognition under Seasonal Changes
Aug 20, 2018

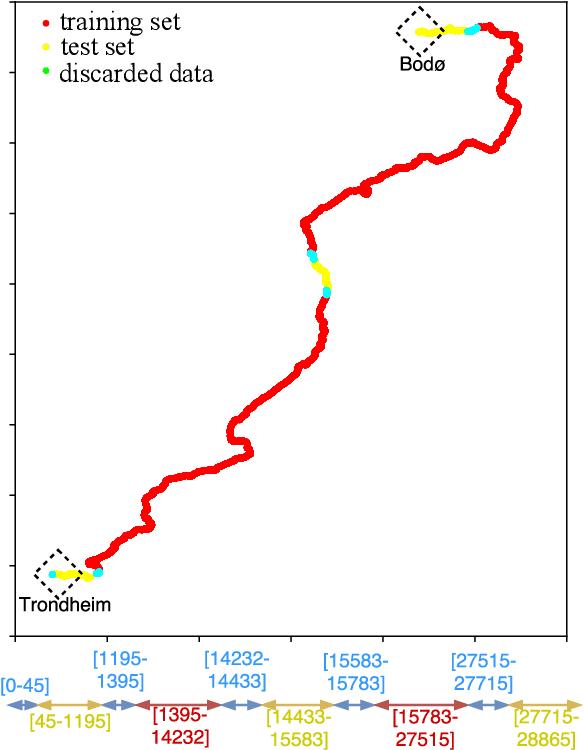
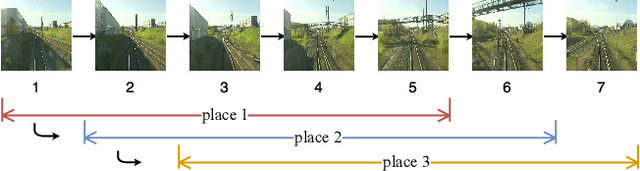
Single-view place recognition, that we can define as finding an image that corresponds to the same place as a given query image, is a key capability for autonomous navigation and mapping. Although there has been a considerable amount of research in the topic, the high degree of image variability (with viewpoint, illumination or occlusions for example) makes it a research challenge. One of the particular challenges, that we address in this work, is weather variation. Seasonal changes can produce drastic appearance changes, that classic low-level features do not model properly. Our contributions in this paper are twofold. First we pre-process and propose a partition for the Nordland dataset, frequently used for place recognition research without consensus on the partitions. And second, we evaluate several neural network architectures such as pre-trained, siamese and triplet for this problem. Our best results outperform the state of the art of the field. A video showing our results can be found in https://youtu.be/VrlxsYZoHDM. The partitioned version of the Nordland dataset at http://webdiis.unizar.es/~jmfacil/pr-nordland/.
DynaSLAM: Tracking, Mapping and Inpainting in Dynamic Scenes
Aug 15, 2018

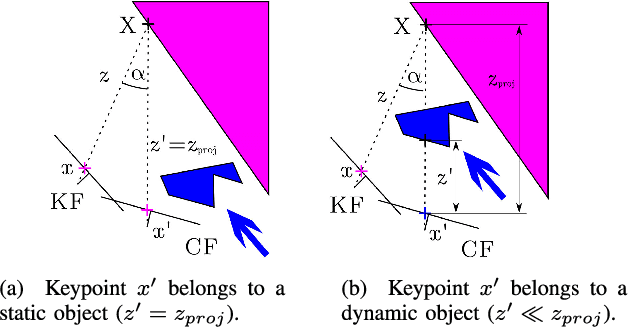

The assumption of scene rigidity is typical in SLAM algorithms. Such a strong assumption limits the use of most visual SLAM systems in populated real-world environments, which are the target of several relevant applications like service robotics or autonomous vehicles. In this paper we present DynaSLAM, a visual SLAM system that, building over ORB-SLAM2 [1], adds the capabilities of dynamic object detection and background inpainting. DynaSLAM is robust in dynamic scenarios for monocular, stereo and RGB-D configurations. We are capable of detecting the moving objects either by multi-view geometry, deep learning or both. Having a static map of the scene allows inpainting the frame background that has been occluded by such dynamic objects. We evaluate our system in public monocular, stereo and RGB-D datasets. We study the impact of several accuracy/speed trade-offs to assess the limits of the proposed methodology. DynaSLAM outperforms the accuracy of standard visual SLAM baselines in highly dynamic scenarios. And it also estimates a map of the static parts of the scene, which is a must for long-term applications in real-world environments.
* This work has been accepted at IEEE Robotics and Automation Letters, and will be presented at the IEEE Conference on Intelligent Robots and Systems 2018
Single-View and Multi-View Depth Fusion
Jun 27, 2017



Dense and accurate 3D mapping from a monocular sequence is a key technology for several applications and still an open research area. This paper leverages recent results on single-view CNN-based depth estimation and fuses them with multi-view depth estimation. Both approaches present complementary strengths. Multi-view depth is highly accurate but only in high-texture areas and high-parallax cases. Single-view depth captures the local structure of mid-level regions, including texture-less areas, but the estimated depth lacks global coherence. The single and multi-view fusion we propose is challenging in several aspects. First, both depths are related by a deformation that depends on the image content. Second, the selection of multi-view points of high accuracy might be difficult for low-parallax configurations. We present contributions for both problems. Our results in the public datasets of NYUv2 and TUM shows that our algorithm outperforms the individual single and multi-view approaches. A video showing the key aspects of mapping in our Single and Multi-view depth proposal is available at https://youtu.be/ipc5HukTb4k