 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Drunkard's Odometry: Estimating Camera Motion in Deforming Scenes
Jun 29, 2023Estimating camera motion in deformable scenes poses a complex and open research challenge. Most existing non-rigid structure from motion techniques assume to observe also static scene parts besides deforming scene parts in order to establish an anchoring reference. However, this assumption does not hold true in certain relevant application cases such as endoscopies. Deformable odometry and SLAM pipelines, which tackle the most challenging scenario of exploratory trajectories, suffer from a lack of robustness and proper quantitative evaluation methodologies. To tackle this issue with a common benchmark, we introduce the Drunkard's Dataset, a challenging collection of synthetic data targeting visual navigation and reconstruction in deformable environments. This dataset is the first large set of exploratory camera trajectories with ground truth inside 3D scenes where every surface exhibits non-rigid deformations over time. Simulations in realistic 3D buildings lets us obtain a vast amount of data and ground truth labels, including camera poses, RGB images and depth, optical flow and normal maps at high resolution and quality. We further present a novel deformable odometry method, dubbed the Drunkard's Odometry, which decomposes optical flow estimates into rigid-body camera motion and non-rigid scene deformations. In order to validate our data, our work contains an evaluation of several baselines as well as a novel tracking error metric which does not require ground truth data. Dataset and code: https://davidrecasens.github.io/TheDrunkard'sOdometry/
EndoMapper dataset of complete calibrated endoscopy procedures
Apr 29, 2022
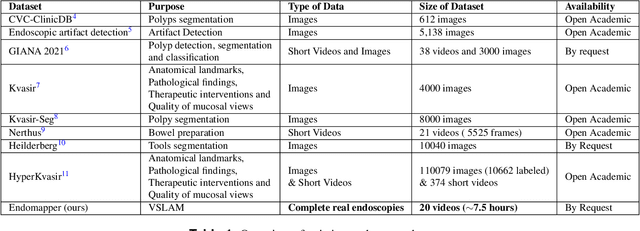


Computer-assisted systems are becoming broadly used in medicine. In endoscopy, most research focuses on automatic detection of polyps or other pathologies, but localization and navigation of the endoscope is completely performed manually by physicians. To broaden this research and bring spatial Artificial Intelligence to endoscopies, data from complete procedures are needed. This data will be used to build a 3D mapping and localization systems that can perform special task like, for example, detect blind zones during exploration, provide automatic polyp measurements, guide doctors to a polyp found in a previous exploration and retrieve previous images of the same area aligning them for easy comparison. These systems will provide an improvement in the quality and precision of the procedures while lowering the burden on the physicians. This paper introduces the Endomapper dataset, the first collection of complete endoscopy sequences acquired during regular medical practice, including slow and careful screening explorations, making secondary use of medical data. Its original purpose is to facilitate the development and evaluation of VSLAM (Visual Simultaneous Localization and Mapping) methods in real endoscopy data. The first release of the dataset is composed of 59 sequences with more than 15 hours of video. It is also the first endoscopic dataset that includes both the computed geometric and photometric endoscope calibration with the original calibration videos. Meta-data and annotations associated to the dataset varies from anatomical landmark and description of the procedure labeling, tools segmentation masks, COLMAP 3D reconstructions, simulated sequences with groundtruth and meta-data related to special cases, such as sequences from the same patient. This information will improve the research in endoscopic VSLAM, as well as other research lines, and create new research lines.
On the Uncertain Single-View Depths in Endoscopies
Dec 16, 2021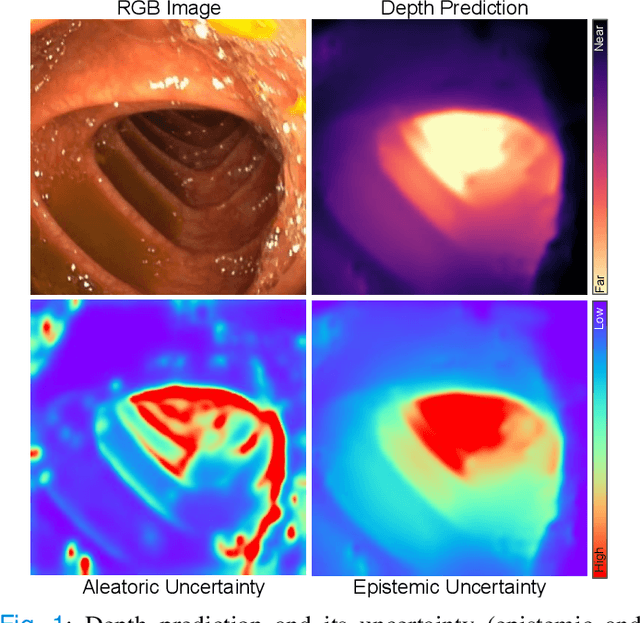
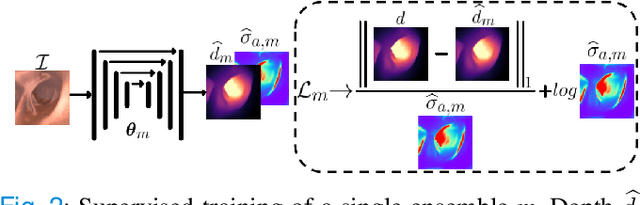
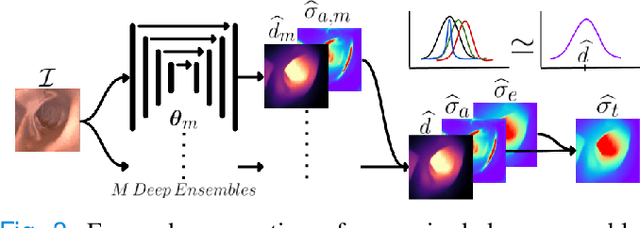
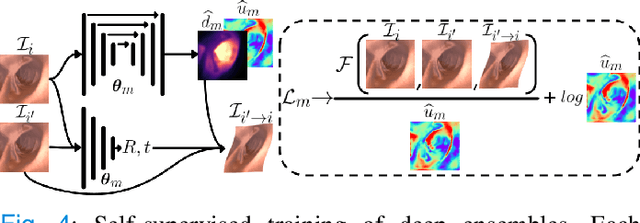
Estimating depth from endoscopic images is a pre-requisite for a wide set of AI-assisted technologies, namely accurate localization, measurement of tumors, or identification of non-inspected areas. As the domain specificity of colonoscopies -- a deformable low-texture environment with fluids, poor lighting conditions and abrupt sensor motions -- pose challenges to multi-view approaches, single-view depth learning stands out as a promising line of research. In this paper, we explore for the first time Bayesian deep networks for single-view depth estimation in colonoscopies. Their uncertainty quantification offers great potential for such a critical application area. Our specific contribution is two-fold: 1) an exhaustive analysis of Bayesian deep networks for depth estimation in three different datasets, highlighting challenges and conclusions regarding synthetic-to-real domain changes and supervised vs. self-supervised methods; and 2) a novel teacher-student approach to deep depth learning that takes into account the teacher uncertainty.
Endo-Depth-and-Motion: Localization and Reconstruction in Endoscopic Videos using Depth Networks and Photometric Constraints
Mar 30, 2021



Estimating a scene reconstruction and the camera motion from in-body videos is challenging due to several factors, e.g. the deformation of in-body cavities or the lack of texture. In this paper we present Endo-Depth-and-Motion, a pipeline that estimates the 6-degrees-of-freedom camera pose and dense 3D scene models from monocular endoscopic videos. Our approach leverages recent advances in self-supervised depth networks to generate pseudo-RGBD frames, then tracks the camera pose using photometric residuals and fuses the registered depth maps in a volumetric representation. We present an extensive experimental evaluation in the public dataset Hamlyn, showing high-quality results and comparisons against relevant baselines. We also release all models and code for future comparisons.