 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Densification for Multi-Map Monocular VSLAM in Endoscopy
Mar 18, 2025Multi-map Sparse Monocular visual Simultaneous Localization and Mapping applied to monocular endoscopic sequences has proven efficient to robustly recover tracking after the frequent losses in endoscopy due to motion blur, temporal occlusion, tools interaction or water jets. The sparse multi-maps are adequate for robust camera localization, however they are very poor for environment representation, they are noisy, with a high percentage of inaccurately reconstructed 3D points, including significant outliers, and more importantly with an unacceptable low density for clinical applications. We propose a method to remove outliers and densify the maps of the state of the art for sparse endoscopy multi-map CudaSIFT-SLAM. The NN LightDepth for up-to-scale depth dense predictions are aligned with the sparse CudaSIFT submaps by means of the robust to spurious LMedS. Our system mitigates the inherent scale ambiguity in monocular depth estimation while filtering outliers, leading to reliable densified 3D maps. We provide experimental evidence of accurate densified maps 4.15 mm RMS accuracy at affordable computing time in the C3VD phantom colon dataset. We report qualitative results on the real colonoscopy from the Endomapper dataset.
LightDepth: Single-View Depth Self-Supervision from Illumination Decline
Aug 21, 2023



Single-view depth estimation can be remarkably effective if there is enough ground-truth depth data for supervised training. However, there are scenarios, especially in medicine in the case of endoscopies, where such data cannot be obtained. In such cases, multi-view self-supervision and synthetic-to-real transfer serve as alternative approaches, however, with a considerable performance reduction in comparison to supervised case. Instead, we propose a single-view self-supervised method that achieves a performance similar to the supervised case. In some medical devices, such as endoscopes, the camera and light sources are co-located at a small distance from the target surfaces. Thus, we can exploit that, for any given albedo and surface orientation, pixel brightness is inversely proportional to the square of the distance to the surface, providing a strong single-view self-supervisory signal. In our experiments, our self-supervised models deliver accuracies comparable to those of fully supervised ones, while being applicable without depth ground-truth data.
On the Uncertain Single-View Depths in Endoscopies
Dec 16, 2021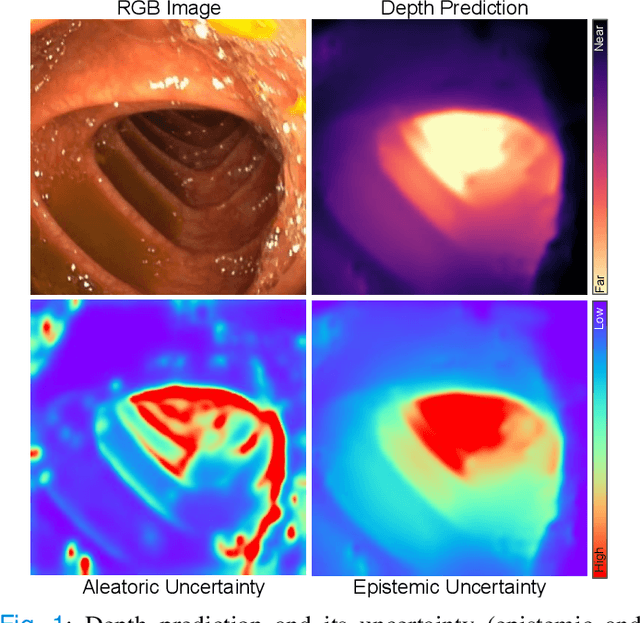
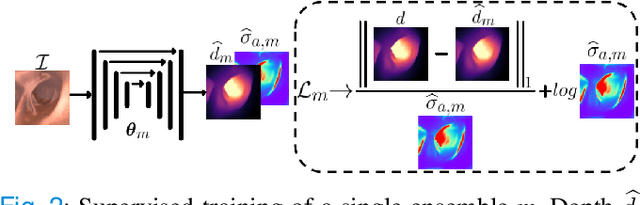
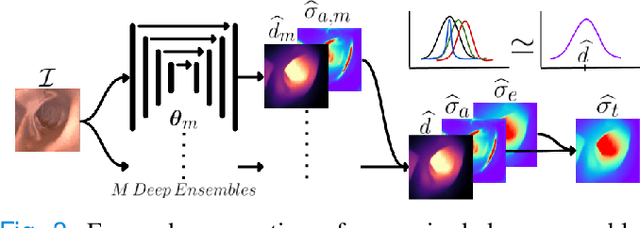
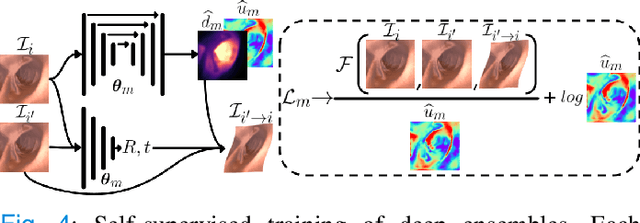
Estimating depth from endoscopic images is a pre-requisite for a wide set of AI-assisted technologies, namely accurate localization, measurement of tumors, or identification of non-inspected areas. As the domain specificity of colonoscopies -- a deformable low-texture environment with fluids, poor lighting conditions and abrupt sensor motions -- pose challenges to multi-view approaches, single-view depth learning stands out as a promising line of research. In this paper, we explore for the first time Bayesian deep networks for single-view depth estimation in colonoscopies. Their uncertainty quantification offers great potential for such a critical application area. Our specific contribution is two-fold: 1) an exhaustive analysis of Bayesian deep networks for depth estimation in three different datasets, highlighting challenges and conclusions regarding synthetic-to-real domain changes and supervised vs. self-supervised methods; and 2) a novel teacher-student approach to deep depth learning that takes into account the teacher uncertainty.
Bayesian Deep Networks for Supervised Single-View Depth Learning
Apr 29, 2021
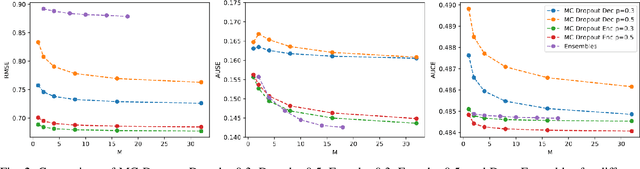
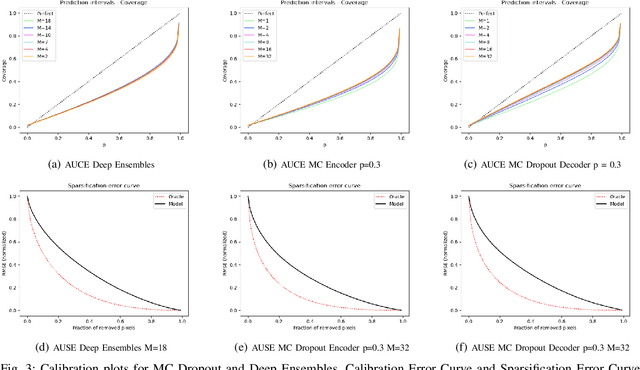
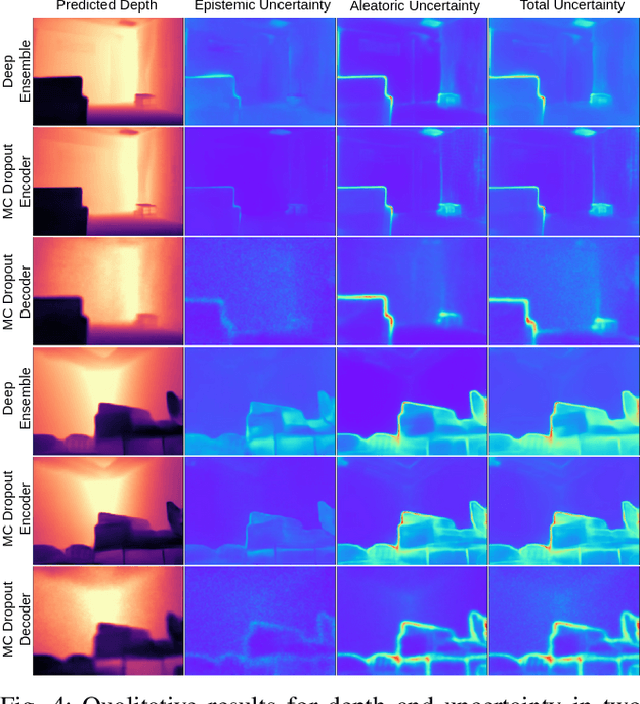
Uncertainty quantification is a key aspect in robotic perception, as overconfident or point estimators can lead to collisions and damages to the environment and the robot. In this paper, we evaluate scalable approaches to uncertainty quantification in single-view supervised depth learning, specifically MC dropout and deep ensembles. For MC dropout, in particular, we explore the effect of the dropout at different levels in the architecture. We demonstrate that adding dropout in the encoder leads to better results than adding it in the decoder, the latest being the usual approach in the literature for similar problems. We also propose the use of depth uncertainty in the application of pseudo-RGBD ICP and demonstrate its potential for improving the accuracy in such a task.