 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC3VD-DEFCOL: A Deformable Colonoscopy Dataset with Time-Resolved 3D Ground Truth and Realistic Appearance
Jun 05, 20263D reconstruction could improve colonoscopy by estimating mucosal coverage and alerting clinicians to missed regions during screening. However, algorithm development is limited as no current datasets provide both a realistic in vivo appearance and dense, time-resolved 3D ground truth, especially under non-rigid deformation. We present C3VD-DEFCOL, a framework and dataset for evaluating deformable colonoscopy reconstruction with paired geometry and realistic texture. Starting from C3VD/C3VDv2 colon meshes and camera trajectories, we generate controlled deformations of the colon surface, including peristaltic waves and centerline motion, and render per-frame depth, surface normals, optical flow, camera poses, and time-stamped 3D meshes. We then use the rendered geometry, primarily depth, to condition an LTX-2.3-based sim-to-real translation model that produces RGB clips with in vivo-like mucosal color, texture, vasculature, and specular appearance while preserving the underlying 3D scene structure. The resulting dataset contains 110 videos from 11 unique colon mesh geometries, with varying camera trajectories, appearances, and parameterized deformation regimes, including three peristaltic severity levels that serve as controlled evaluation axes. We evaluate the generated videos using appearance realism, geometric consistency, and temporal consistency metrics, and use the paired ground truth to benchmark the downstream task of pose estimation in deformable 3D reconstruction. Our experiments show how pose estimation error increases with increasing deformation severity, providing a controlled stress test that is not possible with existing in vivo datasets. Overall, C3VD-DEFCOL is designed as a reproducible, quantitative evaluation platform for testing deformable 3D reconstruction algorithms, with the goal of reducing the domain gap between synthetic datasets and in vivo colonoscopy.
EndoMetric: Near-light metric scale monocular SLAM
Oct 19, 2024

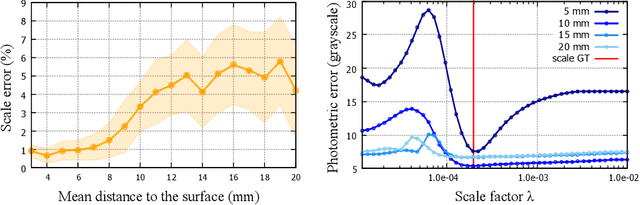
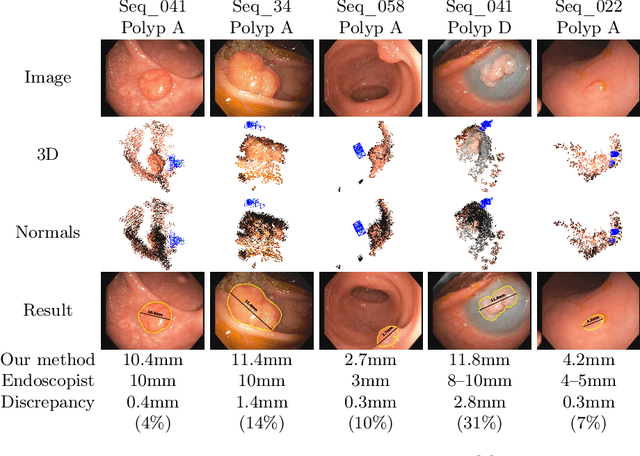
Geometric reconstruction and SLAM with endoscopic images have seen significant advancements in recent years. In most medical specialties, the endoscopes used are monocular, and the algorithms applied are typically extensions of those designed for external environments, resulting in 3D reconstructions up to an unknown scale factor. In this paper, we take advantage of the fact that standard endoscopes are equipped with near-light sources positioned at a small but non-zero baseline from the camera. By leveraging the inverse-square law of light decay, we enable, for the first time, monocular reconstructions with accurate metric scale. This paves the way to transform any endoscope into a metric device, which is essential for practical applications such as measuring polyps, stenosis, or the extent of tissue affected by disease.
LightNeuS: Neural Surface Reconstruction in Endoscopy using Illumination Decline
Sep 06, 2023We propose a new approach to 3D reconstruction from sequences of images acquired by monocular endoscopes. It is based on two key insights. First, endoluminal cavities are watertight, a property naturally enforced by modeling them in terms of a signed distance function. Second, the scene illumination is variable. It comes from the endoscope's light sources and decays with the inverse of the squared distance to the surface. To exploit these insights, we build on NeuS, a neural implicit surface reconstruction technique with an outstanding capability to learn appearance and a SDF surface model from multiple views, but currently limited to scenes with static illumination. To remove this limitation and exploit the relation between pixel brightness and depth, we modify the NeuS architecture to explicitly account for it and introduce a calibrated photometric model of the endoscope's camera and light source. Our method is the first one to produce watertight reconstructions of whole colon sections. We demonstrate excellent accuracy on phantom imagery. Remarkably, the watertight prior combined with illumination decline, allows to complete the reconstruction of unseen portions of the surface with acceptable accuracy, paving the way to automatic quality assessment of cancer screening explorations, measuring the global percentage of observed mucosa.
LightDepth: Single-View Depth Self-Supervision from Illumination Decline
Aug 21, 2023



Single-view depth estimation can be remarkably effective if there is enough ground-truth depth data for supervised training. However, there are scenarios, especially in medicine in the case of endoscopies, where such data cannot be obtained. In such cases, multi-view self-supervision and synthetic-to-real transfer serve as alternative approaches, however, with a considerable performance reduction in comparison to supervised case. Instead, we propose a single-view self-supervised method that achieves a performance similar to the supervised case. In some medical devices, such as endoscopes, the camera and light sources are co-located at a small distance from the target surfaces. Thus, we can exploit that, for any given albedo and surface orientation, pixel brightness is inversely proportional to the square of the distance to the surface, providing a strong single-view self-supervisory signal. In our experiments, our self-supervised models deliver accuracies comparable to those of fully supervised ones, while being applicable without depth ground-truth data.