 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC3VD-DEFCOL: A Deformable Colonoscopy Dataset with Time-Resolved 3D Ground Truth and Realistic Appearance
Jun 05, 20263D reconstruction could improve colonoscopy by estimating mucosal coverage and alerting clinicians to missed regions during screening. However, algorithm development is limited as no current datasets provide both a realistic in vivo appearance and dense, time-resolved 3D ground truth, especially under non-rigid deformation. We present C3VD-DEFCOL, a framework and dataset for evaluating deformable colonoscopy reconstruction with paired geometry and realistic texture. Starting from C3VD/C3VDv2 colon meshes and camera trajectories, we generate controlled deformations of the colon surface, including peristaltic waves and centerline motion, and render per-frame depth, surface normals, optical flow, camera poses, and time-stamped 3D meshes. We then use the rendered geometry, primarily depth, to condition an LTX-2.3-based sim-to-real translation model that produces RGB clips with in vivo-like mucosal color, texture, vasculature, and specular appearance while preserving the underlying 3D scene structure. The resulting dataset contains 110 videos from 11 unique colon mesh geometries, with varying camera trajectories, appearances, and parameterized deformation regimes, including three peristaltic severity levels that serve as controlled evaluation axes. We evaluate the generated videos using appearance realism, geometric consistency, and temporal consistency metrics, and use the paired ground truth to benchmark the downstream task of pose estimation in deformable 3D reconstruction. Our experiments show how pose estimation error increases with increasing deformation severity, providing a controlled stress test that is not possible with existing in vivo datasets. Overall, C3VD-DEFCOL is designed as a reproducible, quantitative evaluation platform for testing deformable 3D reconstruction algorithms, with the goal of reducing the domain gap between synthetic datasets and in vivo colonoscopy.
SuperPoint-E: local features for 3D reconstruction via tracking adaptation in endoscopy
Feb 04, 2026In this work, we focus on boosting the feature extraction to improve the performance of Structure-from-Motion (SfM) in endoscopy videos. We present SuperPoint-E, a new local feature extraction method that, using our proposed Tracking Adaptation supervision strategy, significantly improves the quality of feature detection and description in endoscopy. Extensive experimentation on real endoscopy recordings studies our approach's most suitable configuration and evaluates SuperPoint-E feature quality. The comparison with other baselines also shows that our 3D reconstructions are denser and cover more and longer video segments because our detector fires more densely and our features are more likely to survive (i.e. higher detection precision). In addition, our descriptor is more discriminative, making the guided matching step almost redundant. The presented approach brings significant improvements in the 3D reconstructions obtained, via SfM on endoscopy videos, compared to the original SuperPoint and the gold standard SfM COLMAP pipeline.
EndoMetric: Near-light metric scale monocular SLAM
Oct 19, 2024

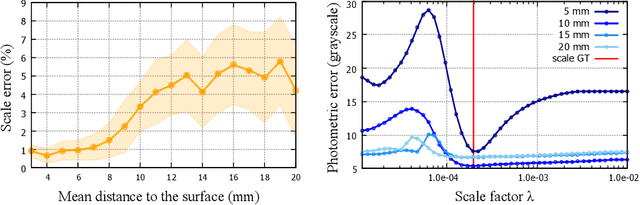
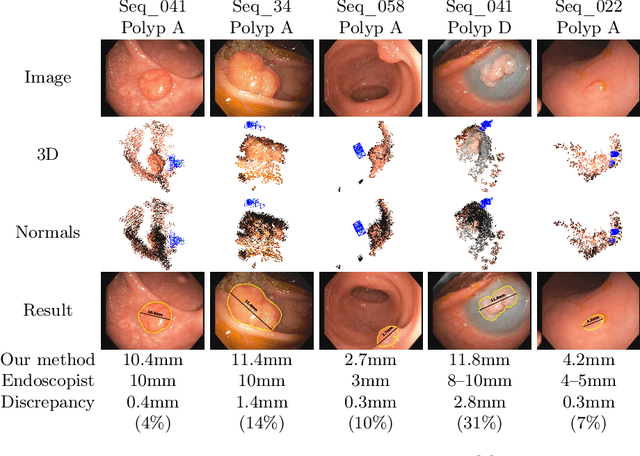
Geometric reconstruction and SLAM with endoscopic images have seen significant advancements in recent years. In most medical specialties, the endoscopes used are monocular, and the algorithms applied are typically extensions of those designed for external environments, resulting in 3D reconstructions up to an unknown scale factor. In this paper, we take advantage of the fact that standard endoscopes are equipped with near-light sources positioned at a small but non-zero baseline from the camera. By leveraging the inverse-square law of light decay, we enable, for the first time, monocular reconstructions with accurate metric scale. This paves the way to transform any endoscope into a metric device, which is essential for practical applications such as measuring polyps, stenosis, or the extent of tissue affected by disease.
Topological SLAM in colonoscopies leveraging deep features and topological priors
Sep 25, 2024We introduce ColonSLAM, a system that combines classical multiple-map metric SLAM with deep features and topological priors to create topological maps of the whole colon. The SLAM pipeline by itself is able to create disconnected individual metric submaps representing locations from short video subsections of the colon, but is not able to merge covisible submaps due to deformations and the limited performance of the SIFT descriptor in the medical domain. ColonSLAM is guided by topological priors and combines a deep localization network trained to distinguish if two images come from the same place or not and the soft verification of a transformer-based matching network, being able to relate far-in-time submaps during an exploration, grouping them in nodes imaging the same colon place, building more complex maps than any other approach in the literature. We demonstrate our approach in the Endomapper dataset, showing its potential for producing maps of the whole colon in real human explorations. Code and models are available at: https://github.com/endomapper/ColonSLAM.
CudaSIFT-SLAM: multiple-map visual SLAM for full procedure mapping in real human endoscopy
May 27, 2024


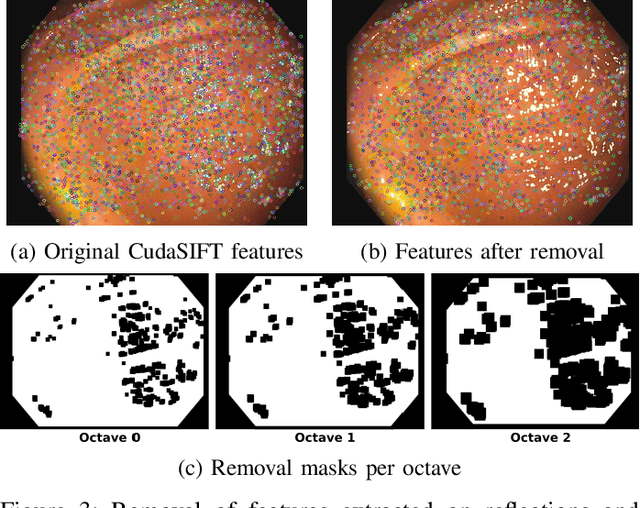
Monocular visual simultaneous localization and mapping (V-SLAM) is nowadays an irreplaceable tool in mobile robotics and augmented reality, where it performs robustly. However, human colonoscopies pose formidable challenges like occlusions, blur, light changes, lack of texture, deformation, water jets or tool interaction, which result in very frequent tracking losses. ORB-SLAM3, the top performing multiple-map V-SLAM, is unable to recover from them by merging sub-maps or relocalizing the camera, due to the poor performance of its place recognition algorithm based on ORB features and DBoW2 bag-of-words. We present CudaSIFT-SLAM, the first V-SLAM system able to process complete human colonoscopies in real-time. To overcome the limitations of ORB-SLAM3, we use SIFT instead of ORB features and replace the DBoW2 direct index with the more computationally demanding brute-force matching, being able to successfully match images separated in time for relocation and map merging. Real-time performance is achieved thanks to CudaSIFT, a GPU implementation for SIFT extraction and brute-force matching. We benchmark our system in the C3VD phantom colon dataset, and in a full real colonoscopy from the Endomapper dataset, demonstrating the capabilities to merge sub-maps and relocate in them, obtaining significantly longer sub-maps. Our system successfully maps in real-time 88 % of the frames in the C3VD dataset. In a real screening colonoscopy, despite the much higher prevalence of occluded and blurred frames, the mapping coverage is 53 % in carefully explored areas and 38 % in the full sequence, a 70 % improvement over ORB-SLAM3.
LightNeuS: Neural Surface Reconstruction in Endoscopy using Illumination Decline
Sep 06, 2023We propose a new approach to 3D reconstruction from sequences of images acquired by monocular endoscopes. It is based on two key insights. First, endoluminal cavities are watertight, a property naturally enforced by modeling them in terms of a signed distance function. Second, the scene illumination is variable. It comes from the endoscope's light sources and decays with the inverse of the squared distance to the surface. To exploit these insights, we build on NeuS, a neural implicit surface reconstruction technique with an outstanding capability to learn appearance and a SDF surface model from multiple views, but currently limited to scenes with static illumination. To remove this limitation and exploit the relation between pixel brightness and depth, we modify the NeuS architecture to explicitly account for it and introduce a calibrated photometric model of the endoscope's camera and light source. Our method is the first one to produce watertight reconstructions of whole colon sections. We demonstrate excellent accuracy on phantom imagery. Remarkably, the watertight prior combined with illumination decline, allows to complete the reconstruction of unseen portions of the surface with acceptable accuracy, paving the way to automatic quality assessment of cancer screening explorations, measuring the global percentage of observed mucosa.
SimCol3D -- 3D Reconstruction during Colonoscopy Challenge
Jul 20, 2023Colorectal cancer is one of the most common cancers in the world. While colonoscopy is an effective screening technique, navigating an endoscope through the colon to detect polyps is challenging. A 3D map of the observed surfaces could enhance the identification of unscreened colon tissue and serve as a training platform. However, reconstructing the colon from video footage remains unsolved due to numerous factors such as self-occlusion, reflective surfaces, lack of texture, and tissue deformation that limit feature-based methods. Learning-based approaches hold promise as robust alternatives, but necessitate extensive datasets. By establishing a benchmark, the 2022 EndoVis sub-challenge SimCol3D aimed to facilitate data-driven depth and pose prediction during colonoscopy. The challenge was hosted as part of MICCAI 2022 in Singapore. Six teams from around the world and representatives from academia and industry participated in the three sub-challenges: synthetic depth prediction, synthetic pose prediction, and real pose prediction. This paper describes the challenge, the submitted methods, and their results. We show that depth prediction in virtual colonoscopy is robustly solvable, while pose estimation remains an open research question.
EndoMapper dataset of complete calibrated endoscopy procedures
Apr 29, 2022
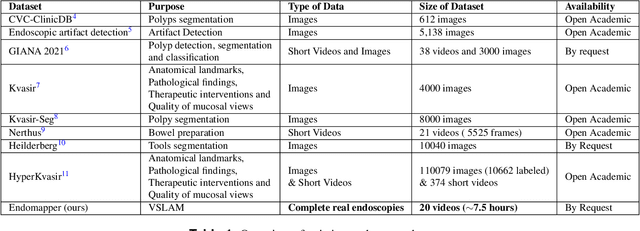


Computer-assisted systems are becoming broadly used in medicine. In endoscopy, most research focuses on automatic detection of polyps or other pathologies, but localization and navigation of the endoscope is completely performed manually by physicians. To broaden this research and bring spatial Artificial Intelligence to endoscopies, data from complete procedures are needed. This data will be used to build a 3D mapping and localization systems that can perform special task like, for example, detect blind zones during exploration, provide automatic polyp measurements, guide doctors to a polyp found in a previous exploration and retrieve previous images of the same area aligning them for easy comparison. These systems will provide an improvement in the quality and precision of the procedures while lowering the burden on the physicians. This paper introduces the Endomapper dataset, the first collection of complete endoscopy sequences acquired during regular medical practice, including slow and careful screening explorations, making secondary use of medical data. Its original purpose is to facilitate the development and evaluation of VSLAM (Visual Simultaneous Localization and Mapping) methods in real endoscopy data. The first release of the dataset is composed of 59 sequences with more than 15 hours of video. It is also the first endoscopic dataset that includes both the computed geometric and photometric endoscope calibration with the original calibration videos. Meta-data and annotations associated to the dataset varies from anatomical landmark and description of the procedure labeling, tools segmentation masks, COLMAP 3D reconstructions, simulated sequences with groundtruth and meta-data related to special cases, such as sequences from the same patient. This information will improve the research in endoscopic VSLAM, as well as other research lines, and create new research lines.
SD-DefSLAM: Semi-Direct Monocular SLAM for Deformable and Intracorporeal Scenes
Oct 19, 2020
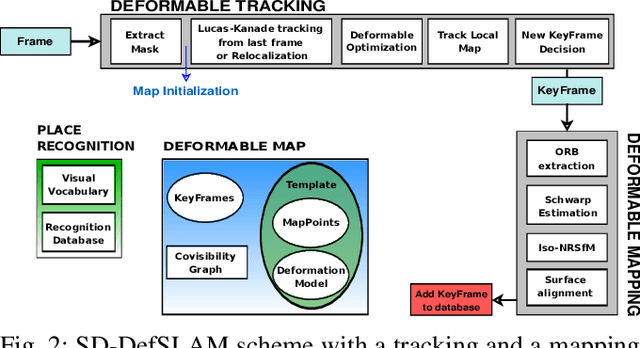
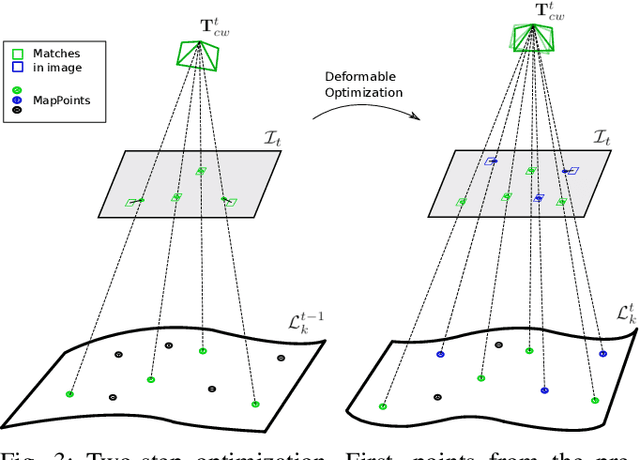
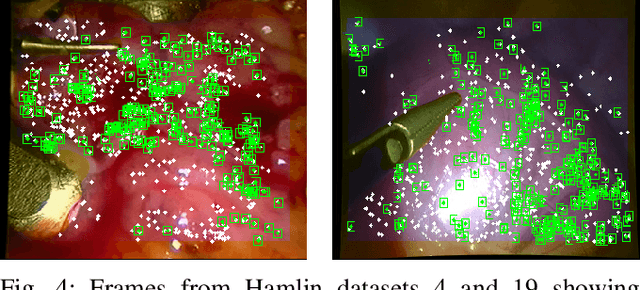
Conventional SLAM techniques strongly rely on scene rigidity to solve data association, ignoring dynamic parts of the scene. In this work we present Semi-Direct DefSLAM (SD-DefSLAM), a novel monocular deformable SLAM method able to map highly deforming environments, built on top of DefSLAM. To robustly solve data association in challenging deforming scenes, SD-DefSLAM combines direct and indirect methods: an enhanced illumination-invariant Lucas-Kanade tracker for data association, geometric Bundle Adjustment for pose and deformable map estimation, and bag-of-words based on feature descriptors for camera relocation. Dynamic objects are detected and segmented-out using a CNN trained for the specific application domain. We thoroughly evaluate our system in two public datasets. The mandala dataset is a SLAM benchmark with increasingly aggressive deformations. The Hamlyn dataset contains intracorporeal sequences that pose serious real-life challenges beyond deformation like weak texture, specular reflections, surgical tools and occlusions. Our results show that SD-DefSLAM outperforms DefSLAM in point tracking, reconstruction accuracy and scale drift thanks to the improvement in all the data association steps, being the first system able to robustly perform SLAM inside the human body.
ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual-Inertial and Multi-Map SLAM
Jul 23, 2020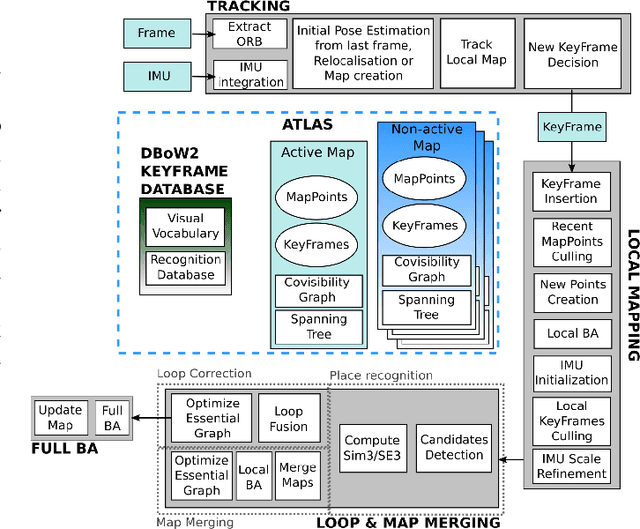
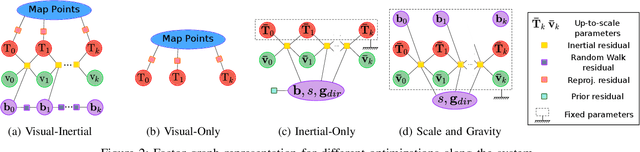
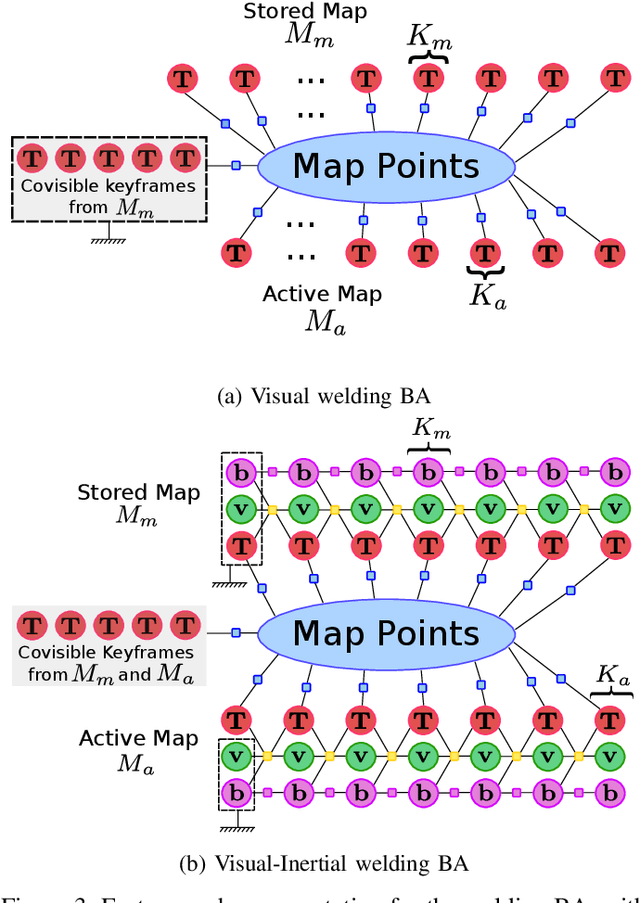
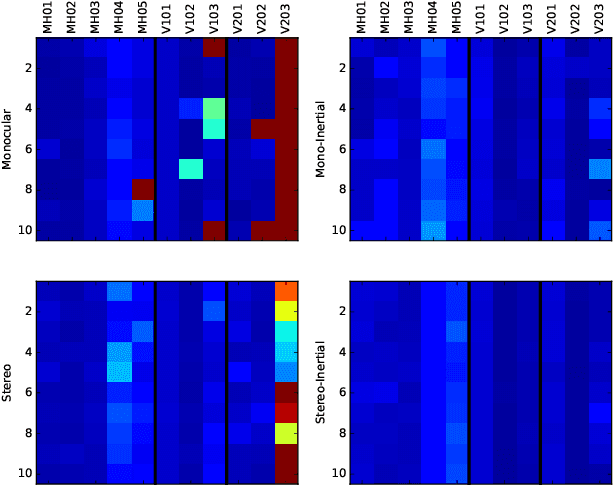
This paper presents ORB-SLAM3, the first system able to perform visual, visual-inertial and multi-map SLAM with monocular, stereo and RGB-D cameras, using pin-hole and fisheye lens models. The first main novelty is a feature-based tightly-integrated visual-inertial SLAM system that fully relies on Maximum-a-Posteriori (MAP) estimation, even during the IMU initialization phase. The result is a system that operates robustly in real-time, in small and large, indoor and outdoor environments, and is 2 to 5 times more accurate than previous approaches. The second main novelty is a multiple map system that relies on a new place recognition method with improved recall. Thanks to it, ORB-SLAM3 is able to survive to long periods of poor visual information: when it gets lost, it starts a new map that will be seamlessly merged with previous maps when revisiting mapped areas. Compared with visual odometry systems that only use information from the last few seconds, ORB-SLAM3 is the first system able to reuse in all the algorithm stages all previous information. This allows to include in bundle adjustment co-visible keyframes, that provide high parallax observations boosting accuracy, even if they are widely separated in time or if they come from a previous mapping session. Our experiments show that, in all sensor configurations, ORB-SLAM3 is as robust as the best systems available in the literature, and significantly more accurate. Notably, our stereo-inertial SLAM achieves an average accuracy of 3.6 cm on the EuRoC drone and 9 mm under quick hand-held motions in the room of TUM-VI dataset, a setting representative of AR/VR scenarios. For the benefit of the community we make public the source code.