 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Deep Networks for Supervised Single-View Depth Learning
Paper and Code
Apr 29, 2021
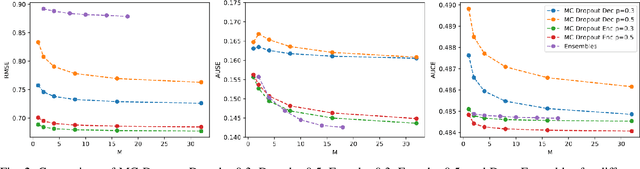
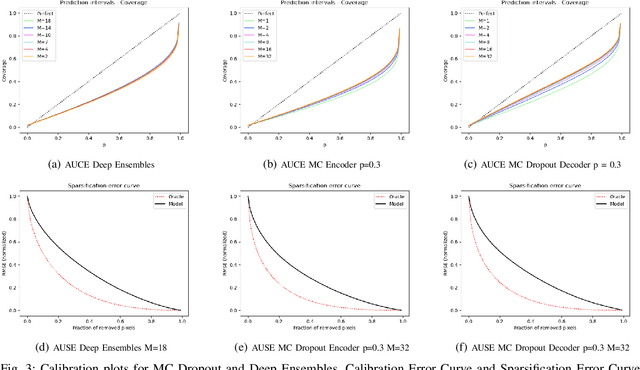
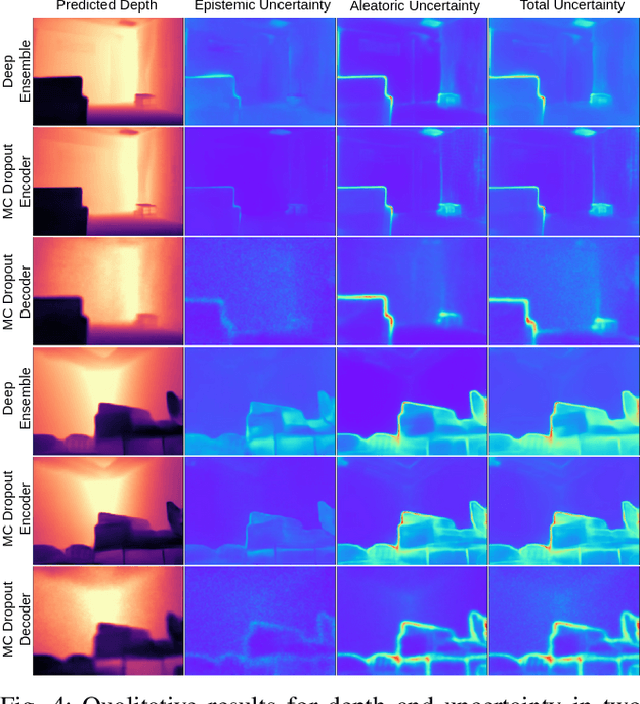
Uncertainty quantification is a key aspect in robotic perception, as overconfident or point estimators can lead to collisions and damages to the environment and the robot. In this paper, we evaluate scalable approaches to uncertainty quantification in single-view supervised depth learning, specifically MC dropout and deep ensembles. For MC dropout, in particular, we explore the effect of the dropout at different levels in the architecture. We demonstrate that adding dropout in the encoder leads to better results than adding it in the decoder, the latest being the usual approach in the literature for similar problems. We also propose the use of depth uncertainty in the application of pseudo-RGBD ICP and demonstrate its potential for improving the accuracy in such a task.