 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstant Visual Odometry Initialization for Mobile AR
Jul 30, 2021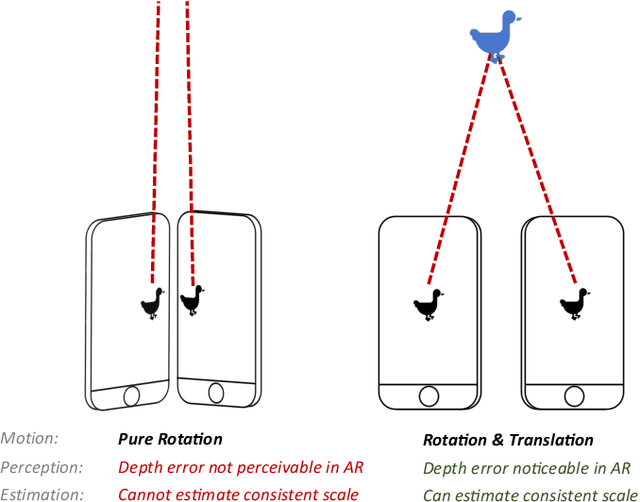
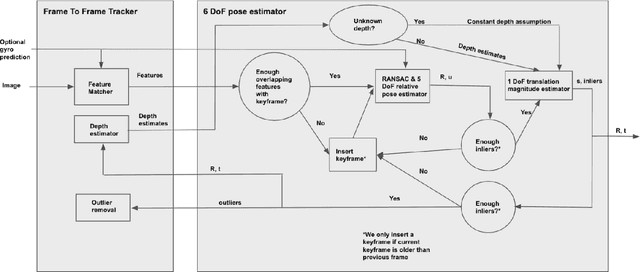
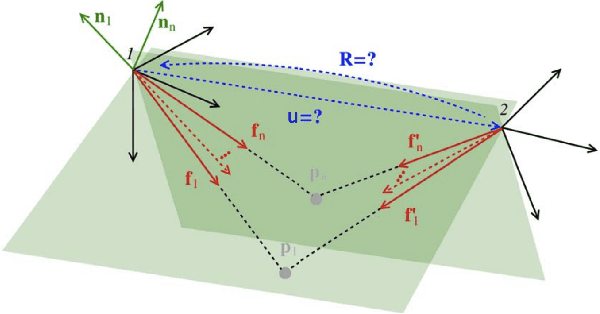
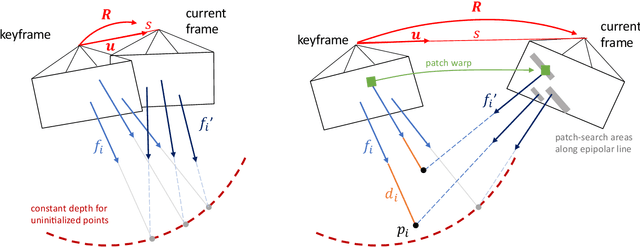
Mobile AR applications benefit from fast initialization to display world-locked effects instantly. However, standard visual odometry or SLAM algorithms require motion parallax to initialize (see Figure 1) and, therefore, suffer from delayed initialization. In this paper, we present a 6-DoF monocular visual odometry that initializes instantly and without motion parallax. Our main contribution is a pose estimator that decouples estimating the 5-DoF relative rotation and translation direction from the 1-DoF translation magnitude. While scale is not observable in a monocular vision-only setting, it is still paramount to estimate a consistent scale over the whole trajectory (even if not physically accurate) to avoid AR effects moving erroneously along depth. In our approach, we leverage the fact that depth errors are not perceivable to the user during rotation-only motion. However, as the user starts translating the device, depth becomes perceivable and so does the capability to estimate consistent scale. Our proposed algorithm naturally transitions between these two modes. We perform extensive validations of our contributions with both a publicly available dataset and synthetic data. We show that the proposed pose estimator outperforms the classical approaches for 6-DoF pose estimation used in the literature in low-parallax configurations. We release a dataset for the relative pose problem using real data to facilitate the comparison with future solutions for the relative pose problem. Our solution is either used as a full odometry or as a preSLAM component of any supported SLAM system (ARKit, ARCore) in world-locked AR effects on platforms such as Instagram and Facebook.
RGBDTAM: A Cost-Effective and Accurate RGB-D Tracking and Mapping System
Aug 09, 2017



Simultaneous Localization and Mapping using RGB-D cameras has been a fertile research topic in the latest decade, due to the suitability of such sensors for indoor robotics. In this paper we propose a direct RGB-D SLAM algorithm with state-of-the-art accuracy and robustness at a los cost. Our experiments in the RGB-D TUM dataset [34] effectively show a better accuracy and robustness in CPU real time than direct RGB-D SLAM systems that make use of the GPU. The key ingredients of our approach are mainly two. Firstly, the combination of a semi-dense photometric and dense geometric error for the pose tracking (see Figure 1), which we demonstrate to be the most accurate alternative. And secondly, a model of the multi-view constraints and their errors in the mapping and tracking threads, which adds extra information over other approaches. We release the open-source implementation of our approach 1 . The reader is referred to a video with our results 2 for a more illustrative visualization of its performance.
Single-View and Multi-View Depth Fusion
Jun 27, 2017



Dense and accurate 3D mapping from a monocular sequence is a key technology for several applications and still an open research area. This paper leverages recent results on single-view CNN-based depth estimation and fuses them with multi-view depth estimation. Both approaches present complementary strengths. Multi-view depth is highly accurate but only in high-texture areas and high-parallax cases. Single-view depth captures the local structure of mid-level regions, including texture-less areas, but the estimated depth lacks global coherence. The single and multi-view fusion we propose is challenging in several aspects. First, both depths are related by a deformation that depends on the image content. Second, the selection of multi-view points of high accuracy might be difficult for low-parallax configurations. We present contributions for both problems. Our results in the public datasets of NYUv2 and TUM shows that our algorithm outperforms the individual single and multi-view approaches. A video showing the key aspects of mapping in our Single and Multi-view depth proposal is available at https://youtu.be/ipc5HukTb4k