 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiEdit: Localised Text-guided Image Editing with Weak Supervision
May 10, 2023Diffusion models (DMs) can generate realistic images with text guidance using large-scale datasets. However, they demonstrate limited controllability in the output space of the generated images. We propose a novel learning method for text-guided image editing, namely \texttt{iEdit}, that generates images conditioned on a source image and a textual edit prompt. As a fully-annotated dataset with target images does not exist, previous approaches perform subject-specific fine-tuning at test time or adopt contrastive learning without a target image, leading to issues on preserving the fidelity of the source image. We propose to automatically construct a dataset derived from LAION-5B, containing pseudo-target images with their descriptive edit prompts given input image-caption pairs. This dataset gives us the flexibility of introducing a weakly-supervised loss function to generate the pseudo-target image from the latent noise of the source image conditioned on the edit prompt. To encourage localised editing and preserve or modify spatial structures in the image, we propose a loss function that uses segmentation masks to guide the editing during training and optionally at inference. Our model is trained on the constructed dataset with 200K samples and constrained GPU resources. It shows favourable results against its counterparts in terms of image fidelity, CLIP alignment score and qualitatively for editing both generated and real images.
Contrastive Language-Action Pre-training for Temporal Localization
Apr 26, 2022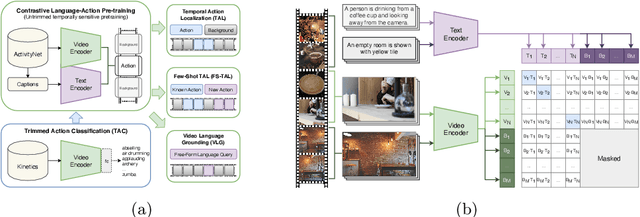
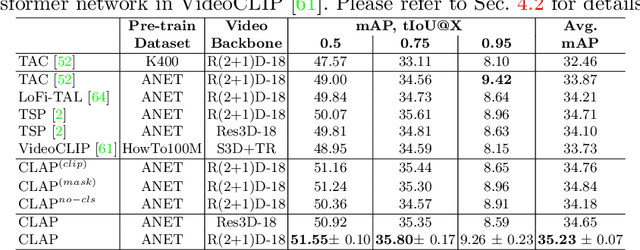
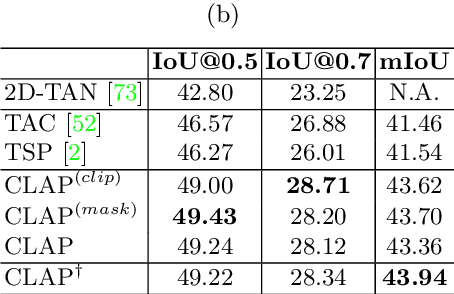
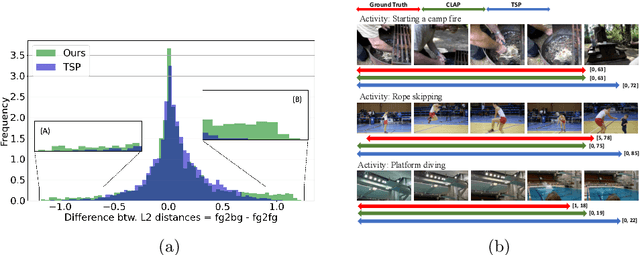
Long-form video understanding requires designing approaches that are able to temporally localize activities or language. End-to-end training for such tasks is limited by the compute device memory constraints and lack of temporal annotations at large-scale. These limitations can be addressed by pre-training on large datasets of temporally trimmed videos supervised by class annotations. Once the video encoder is pre-trained, it is common practice to freeze it during fine-tuning. Therefore, the video encoder does not learn temporal boundaries and unseen classes, causing a domain gap with respect to the downstream tasks. Moreover, using temporally trimmed videos prevents to capture the relations between different action categories and the background context in a video clip which results in limited generalization capacity. To address these limitations, we propose a novel post-pre-training approach without freezing the video encoder which leverages language. We introduce a masked contrastive learning loss to capture visio-linguistic relations between activities, background video clips and language in the form of captions. Our experiments show that the proposed approach improves the state-of-the-art on temporal action localization, few-shot temporal action localization, and video language grounding tasks.
Revamping Cross-Modal Recipe Retrieval with Hierarchical Transformers and Self-supervised Learning
Mar 24, 2021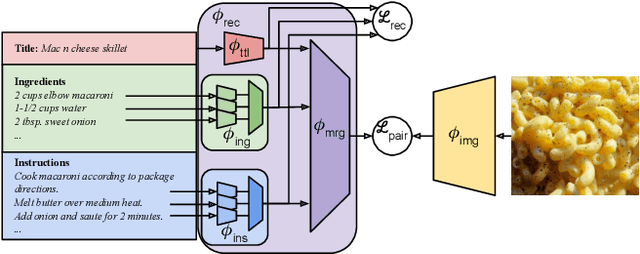
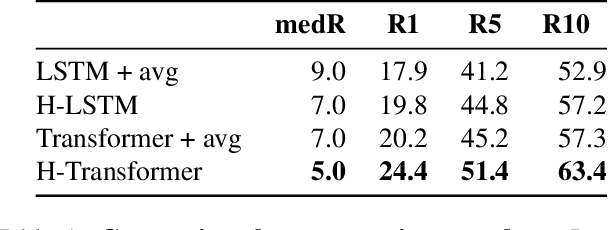

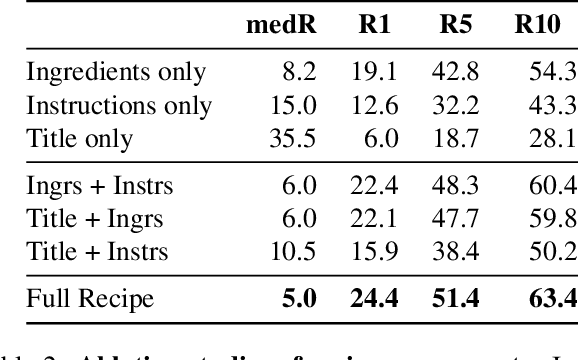
Cross-modal recipe retrieval has recently gained substantial attention due to the importance of food in people's lives, as well as the availability of vast amounts of digital cooking recipes and food images to train machine learning models. In this work, we revisit existing approaches for cross-modal recipe retrieval and propose a simplified end-to-end model based on well established and high performing encoders for text and images. We introduce a hierarchical recipe Transformer which attentively encodes individual recipe components (titles, ingredients and instructions). Further, we propose a self-supervised loss function computed on top of pairs of individual recipe components, which is able to leverage semantic relationships within recipes, and enables training using both image-recipe and recipe-only samples. We conduct a thorough analysis and ablation studies to validate our design choices. As a result, our proposed method achieves state-of-the-art performance in the cross-modal recipe retrieval task on the Recipe1M dataset. We make code and models publicly available.