 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToFu: Visual Tokens Reduction via Fusion for Multi-modal, Multi-patch, Multi-image Task
Mar 06, 2025



Large Multimodal Models (LMMs) are powerful tools that are capable of reasoning and understanding multimodal information beyond text and language. Despite their entrenched impact, the development of LMMs is hindered by the higher computational requirements compared to their unimodal counterparts. One of the main causes of this is the large amount of tokens needed to encode the visual input, which is especially evident for multi-image multimodal tasks. Recent approaches to reduce visual tokens depend on the visual encoder architecture, require fine-tuning the LLM to maintain the performance, and only consider single-image scenarios. To address these limitations, we propose ToFu, a visual encoder-agnostic, training-free Token Fusion strategy that combines redundant visual tokens of LMMs for high-resolution, multi-image, tasks. The core intuition behind our method is straightforward yet effective: preserve distinctive tokens while combining similar ones. We achieve this by sequentially examining visual tokens and deciding whether to merge them with others or keep them as separate entities. We validate our approach on the well-established LLaVA-Interleave Bench, which covers challenging multi-image tasks. In addition, we push to the extreme our method by testing it on a newly-created benchmark, ComPairs, focused on multi-image comparisons where a larger amount of images and visual tokens are inputted to the LMMs. Our extensive analysis, considering several LMM architectures, demonstrates the benefits of our approach both in terms of efficiency and performance gain.
UniCoRN: Unified Commented Retrieval Network with LMMs
Feb 12, 2025Multimodal retrieval methods have limitations in handling complex, compositional queries that require reasoning about the visual content of both the query and the retrieved entities. On the other hand, Large Multimodal Models (LMMs) can answer with language to more complex visual questions, but without the inherent ability to retrieve relevant entities to support their answers. We aim to address these limitations with UniCoRN, a Unified Commented Retrieval Network that combines the strengths of composed multimodal retrieval methods and generative language approaches, going beyond Retrieval-Augmented Generation (RAG). We introduce an entity adapter module to inject the retrieved multimodal entities back into the LMM, so it can attend to them while generating answers and comments. By keeping the base LMM frozen, UniCoRN preserves its original capabilities while being able to perform both retrieval and text generation tasks under a single integrated framework. To assess these new abilities, we introduce the Commented Retrieval task (CoR) and a corresponding dataset, with the goal of retrieving an image that accurately answers a given question and generate an additional textual response that provides further clarification and details about the visual information. We demonstrate the effectiveness of UniCoRN on several datasets showing improvements of +4.5% recall over the state of the art for composed multimodal retrieval and of +14.9% METEOR / +18.4% BEM over RAG for commenting in CoR.
Learning Visual Hierarchies with Hyperbolic Embeddings
Nov 26, 2024Structuring latent representations in a hierarchical manner enables models to learn patterns at multiple levels of abstraction. However, most prevalent image understanding models focus on visual similarity, and learning visual hierarchies is relatively unexplored. In this work, for the first time, we introduce a learning paradigm that can encode user-defined multi-level visual hierarchies in hyperbolic space without requiring explicit hierarchical labels. As a concrete example, first, we define a part-based image hierarchy using object-level annotations within and across images. Then, we introduce an approach to enforce the hierarchy using contrastive loss with pairwise entailment metrics. Finally, we discuss new evaluation metrics to effectively measure hierarchical image retrieval. Encoding these complex relationships ensures that the learned representations capture semantic and structural information that transcends mere visual similarity. Experiments in part-based image retrieval show significant improvements in hierarchical retrieval tasks, demonstrating the capability of our model in capturing visual hierarchies.
LatteCLIP: Unsupervised CLIP Fine-Tuning via LMM-Synthetic Texts
Oct 10, 2024
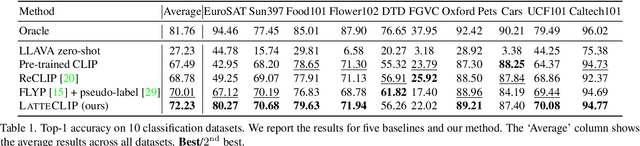

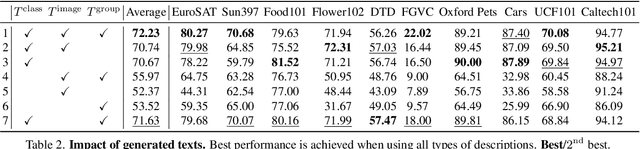
Large-scale vision-language pre-trained (VLP) models (e.g., CLIP) are renowned for their versatility, as they can be applied to diverse applications in a zero-shot setup. However, when these models are used in specific domains, their performance often falls short due to domain gaps or the under-representation of these domains in the training data. While fine-tuning VLP models on custom datasets with human-annotated labels can address this issue, annotating even a small-scale dataset (e.g., 100k samples) can be an expensive endeavor, often requiring expert annotators if the task is complex. To address these challenges, we propose LatteCLIP, an unsupervised method for fine-tuning CLIP models on classification with known class names in custom domains, without relying on human annotations. Our method leverages Large Multimodal Models (LMMs) to generate expressive textual descriptions for both individual images and groups of images. These provide additional contextual information to guide the fine-tuning process in the custom domains. Since LMM-generated descriptions are prone to hallucination or missing details, we introduce a novel strategy to distill only the useful information and stabilize the training. Specifically, we learn rich per-class prototype representations from noisy generated texts and dual pseudo-labels. Our experiments on 10 domain-specific datasets show that LatteCLIP outperforms pre-trained zero-shot methods by an average improvement of +4.74 points in top-1 accuracy and other state-of-the-art unsupervised methods by +3.45 points.
ViewFusion: Towards Multi-View Consistency via Interpolated Denoising
Feb 29, 2024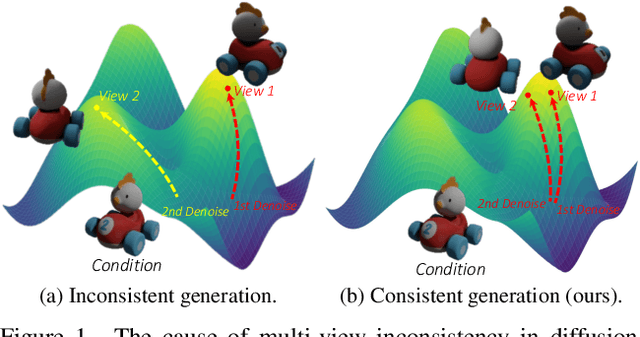
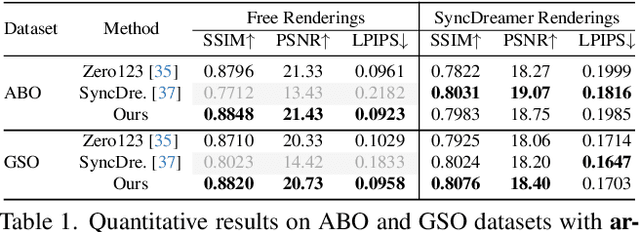
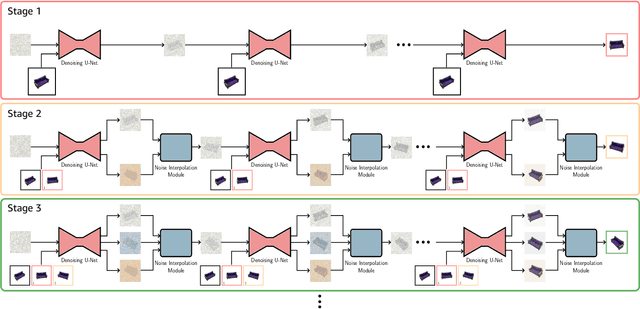
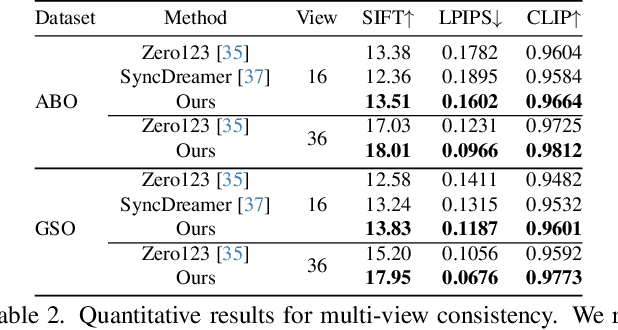
Novel-view synthesis through diffusion models has demonstrated remarkable potential for generating diverse and high-quality images. Yet, the independent process of image generation in these prevailing methods leads to challenges in maintaining multiple-view consistency. To address this, we introduce ViewFusion, a novel, training-free algorithm that can be seamlessly integrated into existing pre-trained diffusion models. Our approach adopts an auto-regressive method that implicitly leverages previously generated views as context for the next view generation, ensuring robust multi-view consistency during the novel-view generation process. Through a diffusion process that fuses known-view information via interpolated denoising, our framework successfully extends single-view conditioned models to work in multiple-view conditional settings without any additional fine-tuning. Extensive experimental results demonstrate the effectiveness of ViewFusion in generating consistent and detailed novel views.
iEdit: Localised Text-guided Image Editing with Weak Supervision
May 10, 2023Diffusion models (DMs) can generate realistic images with text guidance using large-scale datasets. However, they demonstrate limited controllability in the output space of the generated images. We propose a novel learning method for text-guided image editing, namely \texttt{iEdit}, that generates images conditioned on a source image and a textual edit prompt. As a fully-annotated dataset with target images does not exist, previous approaches perform subject-specific fine-tuning at test time or adopt contrastive learning without a target image, leading to issues on preserving the fidelity of the source image. We propose to automatically construct a dataset derived from LAION-5B, containing pseudo-target images with their descriptive edit prompts given input image-caption pairs. This dataset gives us the flexibility of introducing a weakly-supervised loss function to generate the pseudo-target image from the latent noise of the source image conditioned on the edit prompt. To encourage localised editing and preserve or modify spatial structures in the image, we propose a loss function that uses segmentation masks to guide the editing during training and optionally at inference. Our model is trained on the constructed dataset with 200K samples and constrained GPU resources. It shows favourable results against its counterparts in terms of image fidelity, CLIP alignment score and qualitatively for editing both generated and real images.
Contrastive Language-Action Pre-training for Temporal Localization
Apr 26, 2022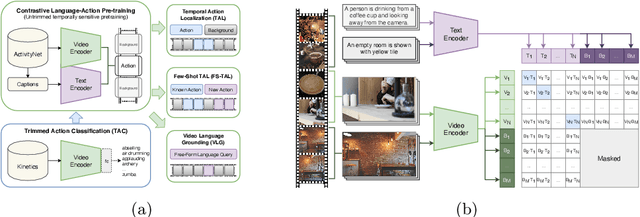
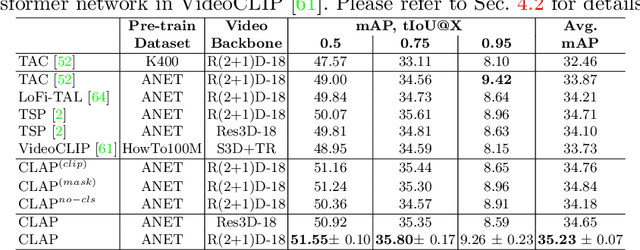
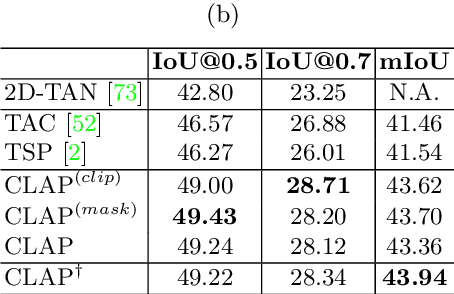
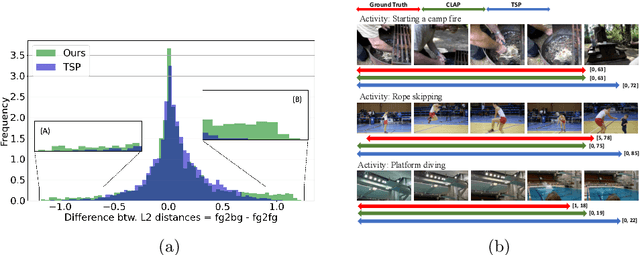
Long-form video understanding requires designing approaches that are able to temporally localize activities or language. End-to-end training for such tasks is limited by the compute device memory constraints and lack of temporal annotations at large-scale. These limitations can be addressed by pre-training on large datasets of temporally trimmed videos supervised by class annotations. Once the video encoder is pre-trained, it is common practice to freeze it during fine-tuning. Therefore, the video encoder does not learn temporal boundaries and unseen classes, causing a domain gap with respect to the downstream tasks. Moreover, using temporally trimmed videos prevents to capture the relations between different action categories and the background context in a video clip which results in limited generalization capacity. To address these limitations, we propose a novel post-pre-training approach without freezing the video encoder which leverages language. We introduce a masked contrastive learning loss to capture visio-linguistic relations between activities, background video clips and language in the form of captions. Our experiments show that the proposed approach improves the state-of-the-art on temporal action localization, few-shot temporal action localization, and video language grounding tasks.
Revamping Cross-Modal Recipe Retrieval with Hierarchical Transformers and Self-supervised Learning
Mar 24, 2021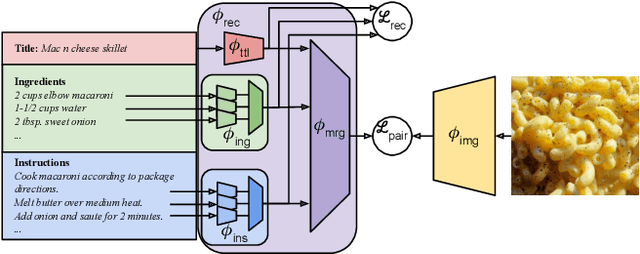
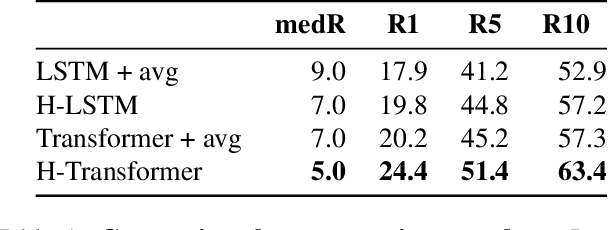

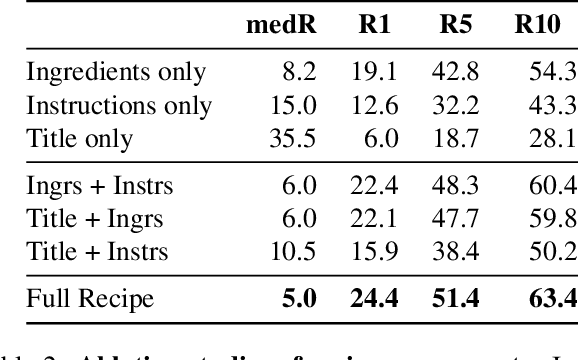
Cross-modal recipe retrieval has recently gained substantial attention due to the importance of food in people's lives, as well as the availability of vast amounts of digital cooking recipes and food images to train machine learning models. In this work, we revisit existing approaches for cross-modal recipe retrieval and propose a simplified end-to-end model based on well established and high performing encoders for text and images. We introduce a hierarchical recipe Transformer which attentively encodes individual recipe components (titles, ingredients and instructions). Further, we propose a self-supervised loss function computed on top of pairs of individual recipe components, which is able to leverage semantic relationships within recipes, and enables training using both image-recipe and recipe-only samples. We conduct a thorough analysis and ablation studies to validate our design choices. As a result, our proposed method achieves state-of-the-art performance in the cross-modal recipe retrieval task on the Recipe1M dataset. We make code and models publicly available.
Image Captioning as Neural Machine Translation Task in SOCKEYE
Oct 15, 2018

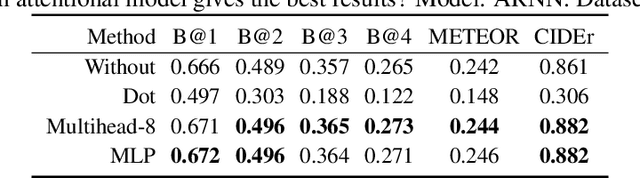

Image captioning is an interdisciplinary research problem that stands between computer vision and natural language processing. The task is to generate a textual description of the content of an image. The typical model used for image captioning is an encoder-decoder deep network, where the encoder captures the essence of an image while the decoder is responsible for generating a sentence describing the image. Attention mechanisms can be used to automatically focus the decoder on parts of the image which are relevant to predict the next word. In this paper, we explore different decoders and attentional models popular in neural machine translation, namely attentional recurrent neural networks, self-attentional transformers, and fully-convolutional networks, which represent the current state of the art of neural machine translation. The image captioning module is available as part of SOCKEYE at https://github.com/awslabs/sockeye which tutorial can be found at https://awslabs.github.io/sockeye/image_captioning.html .
Recurrent Mixture Density Network for Spatiotemporal Visual Attention
Feb 11, 2017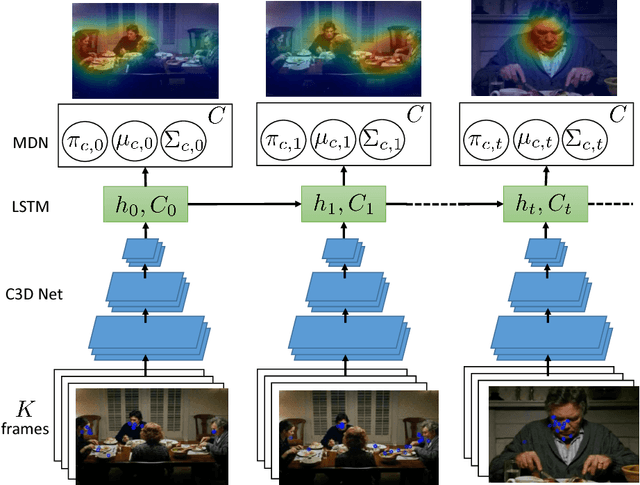



In many computer vision tasks, the relevant information to solve the problem at hand is mixed to irrelevant, distracting information. This has motivated researchers to design attentional models that can dynamically focus on parts of images or videos that are salient, e.g., by down-weighting irrelevant pixels. In this work, we propose a spatiotemporal attentional model that learns where to look in a video directly from human fixation data. We model visual attention with a mixture of Gaussians at each frame. This distribution is used to express the probability of saliency for each pixel. Time consistency in videos is modeled hierarchically by: 1) deep 3D convolutional features to represent spatial and short-term time relations and 2) a long short-term memory network on top that aggregates the clip-level representation of sequential clips and therefore expands the temporal domain from few frames to seconds. The parameters of the proposed model are optimized via maximum likelihood estimation using human fixations as training data, without knowledge of the action in each video. Our experiments on Hollywood2 show state-of-the-art performance on saliency prediction for video. We also show that our attentional model trained on Hollywood2 generalizes well to UCF101 and it can be leveraged to improve action classification accuracy on both datasets.