 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Captioning as Neural Machine Translation Task in SOCKEYE
Paper and Code


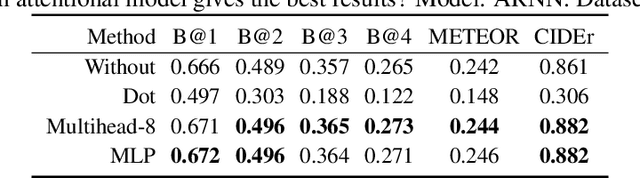

Image captioning is an interdisciplinary research problem that stands between computer vision and natural language processing. The task is to generate a textual description of the content of an image. The typical model used for image captioning is an encoder-decoder deep network, where the encoder captures the essence of an image while the decoder is responsible for generating a sentence describing the image. Attention mechanisms can be used to automatically focus the decoder on parts of the image which are relevant to predict the next word. In this paper, we explore different decoders and attentional models popular in neural machine translation, namely attentional recurrent neural networks, self-attentional transformers, and fully-convolutional networks, which represent the current state of the art of neural machine translation. The image captioning module is available as part of SOCKEYE at https://github.com/awslabs/sockeye which tutorial can be found at https://awslabs.github.io/sockeye/image_captioning.html .