 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Architecture of Semantic Segmentation and Hierarchical Generative Adversarial Networks for Expression Manipulation
Paper and Code
Dec 08, 2021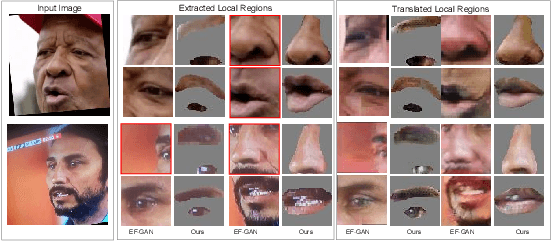
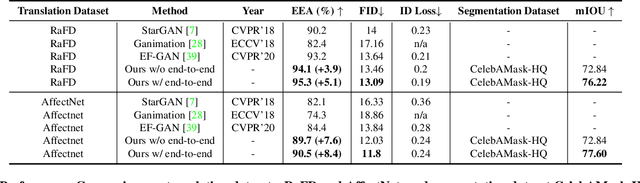
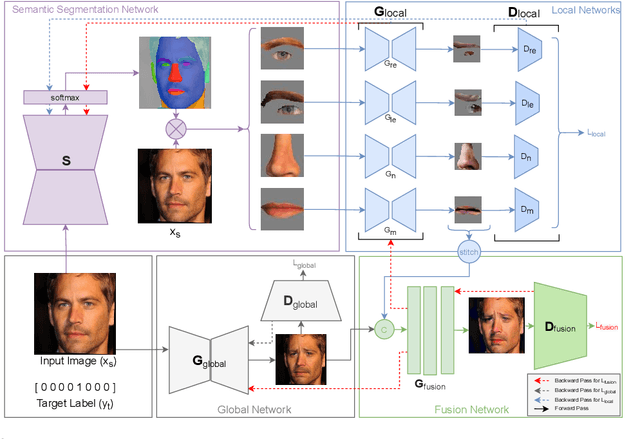
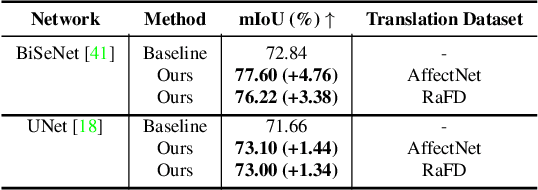
Editing facial expressions by only changing what we want is a long-standing research problem in Generative Adversarial Networks (GANs) for image manipulation. Most of the existing methods that rely only on a global generator usually suffer from changing unwanted attributes along with the target attributes. Recently, hierarchical networks that consist of both a global network dealing with the whole image and multiple local networks focusing on local parts are showing success. However, these methods extract local regions by bounding boxes centred around the sparse facial key points which are non-differentiable, inaccurate and unrealistic. Hence, the solution becomes sub-optimal, introduces unwanted artefacts degrading the overall quality of the synthetic images. Moreover, a recent study has shown strong correlation between facial attributes and local semantic regions. To exploit this relationship, we designed a unified architecture of semantic segmentation and hierarchical GANs. A unique advantage of our framework is that on forward pass the semantic segmentation network conditions the generative model, and on backward pass gradients from hierarchical GANs are propagated to the semantic segmentation network, which makes our framework an end-to-end differentiable architecture. This allows both architectures to benefit from each other. To demonstrate its advantages, we evaluate our method on two challenging facial expression translation benchmarks, AffectNet and RaFD, and a semantic segmentation benchmark, CelebAMask-HQ across two popular architectures, BiSeNet and UNet. Our extensive quantitative and qualitative evaluations on both face semantic segmentation and face expression manipulation tasks validate the effectiveness of our work over existing state-of-the-art methods.