 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugLabel: Exploiting Word Representations to Augment Labels for Face Attribute Classification
Paper and Code
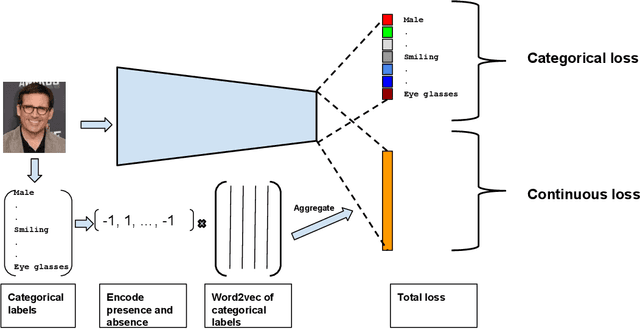
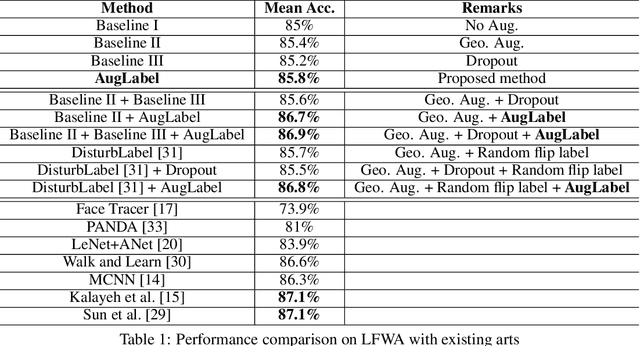
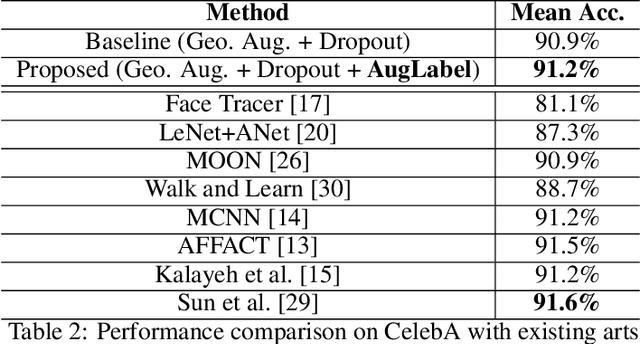
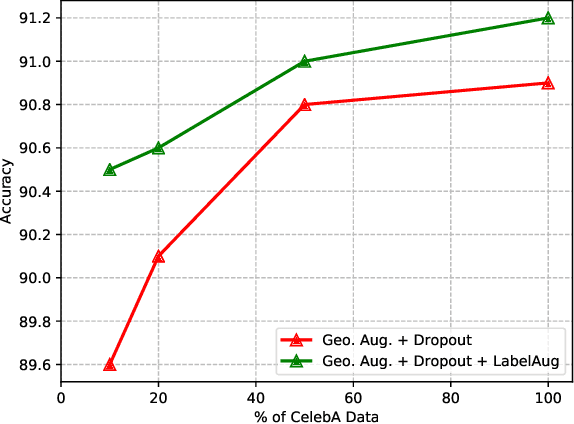
Augmenting data in image space (eg. flipping, cropping etc) and activation space (eg. dropout) are being widely used to regularise deep neural networks and have been successfully applied on several computer vision tasks. Unlike previous works, which are mostly focused on doing augmentation in the aforementioned domains, we propose to do augmentation in label space. In this paper, we present a novel method to generate fixed dimensional labels with continuous values for images by exploiting the word2vec representations of the existing categorical labels. We then append these representations with existing categorical labels and train the model. We validated our idea on two challenging face attribute classification data sets viz. CelebA and LFWA. Our extensive experiments show that the augmented labels improve the performance of the competitive deep learning baseline and reduce the need of annotated real data up to 50%, while attaining a performance similar to the state-of-the-art methods.