 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBody-Hand Modality Expertized Networks with Cross-attention for Fine-grained Skeleton Action Recognition
Paper and Code
Mar 19, 2025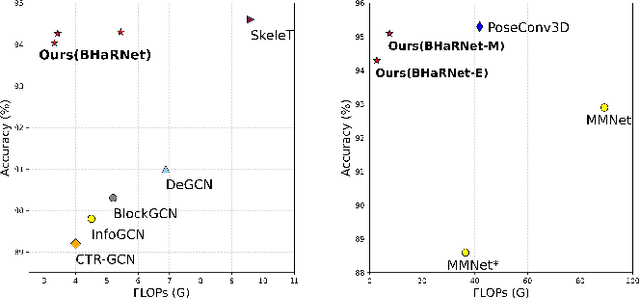
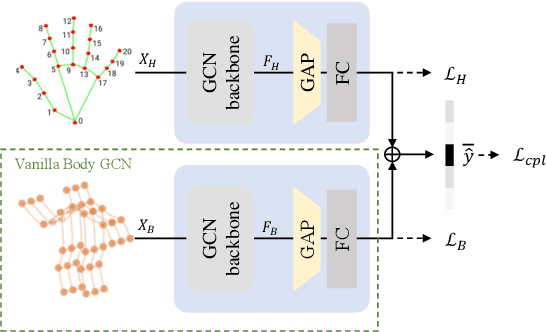
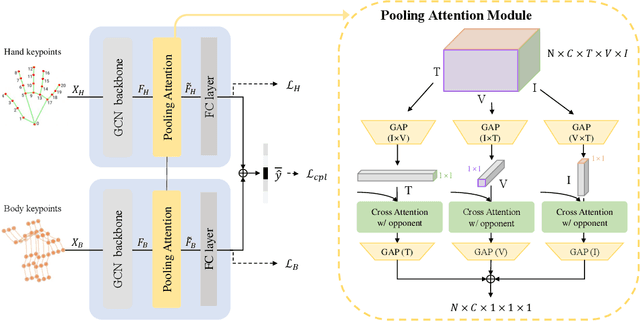
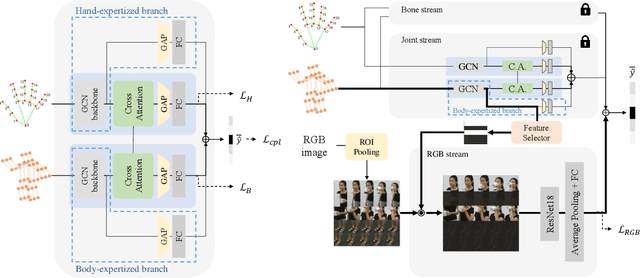
Skeleton-based Human Action Recognition (HAR) is a vital technology in robotics and human-robot interaction. However, most existing methods concentrate primarily on full-body movements and often overlook subtle hand motions that are critical for distinguishing fine-grained actions. Recent work leverages a unified graph representation that combines body, hand, and foot keypoints to capture detailed body dynamics. Yet, these models often blur fine hand details due to the disparity between body and hand action characteristics and the loss of subtle features during the spatial-pooling. In this paper, we propose BHaRNet (Body-Hand action Recognition Network), a novel framework that augments a typical body-expert model with a hand-expert model. Our model jointly trains both streams with an ensemble loss that fosters cooperative specialization, functioning in a manner reminiscent of a Mixture-of-Experts (MoE). Moreover, cross-attention is employed via an expertized branch method and a pooling-attention module to enable feature-level interactions and selectively fuse complementary information. Inspired by MMNet, we also demonstrate the applicability of our approach to multi-modal tasks by leveraging RGB information, where body features guide RGB learning to capture richer contextual cues. Experiments on large-scale benchmarks (NTU RGB+D 60, NTU RGB+D 120, PKU-MMD, and Northwestern-UCLA) demonstrate that BHaRNet achieves SOTA accuracies -- improving from 86.4\% to 93.0\% in hand-intensive actions -- while maintaining fewer GFLOPs and parameters than the relevant unified methods.