 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGHanD: Multi-modal Guidance for authentic Hand Diffusion
Paper and Code
Mar 11, 2025

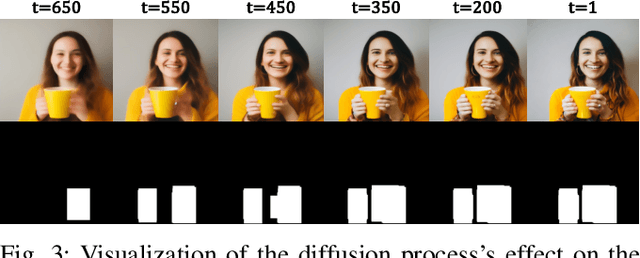

Diffusion-based methods have achieved significant successes in T2I generation, providing realistic images from text prompts. Despite their capabilities, these models face persistent challenges in generating realistic human hands, often producing images with incorrect finger counts and structurally deformed hands. MGHanD addresses this challenge by applying multi-modal guidance during the inference process. For visual guidance, we employ a discriminator trained on a dataset comprising paired real and generated images with captions, derived from various hand-in-the-wild datasets. We also employ textual guidance with LoRA adapter, which learns the direction from `hands' towards more detailed prompts such as `natural hands', and `anatomically correct fingers' at the latent level. A cumulative hand mask which is gradually enlarged in the assigned time step is applied to the added guidance, allowing the hand to be refined while maintaining the rich generative capabilities of the pre-trained model. In the experiments, our method achieves superior hand generation qualities, without any specific conditions or priors. We carry out both quantitative and qualitative evaluations, along with user studies, to showcase the benefits of our approach in producing high-quality hand images.