 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJENGA: Object selection and pose estimation for robotic grasping from a stack
Jun 16, 2025Vision-based robotic object grasping is typically investigated in the context of isolated objects or unstructured object sets in bin picking scenarios. However, there are several settings, such as construction or warehouse automation, where a robot needs to interact with a structured object formation such as a stack. In this context, we define the problem of selecting suitable objects for grasping along with estimating an accurate 6DoF pose of these objects. To address this problem, we propose a camera-IMU based approach that prioritizes unobstructed objects on the higher layers of stacks and introduce a dataset for benchmarking and evaluation, along with a suitable evaluation metric that combines object selection with pose accuracy. Experimental results show that although our method can perform quite well, this is a challenging problem if a completely error-free solution is needed. Finally, we show results from the deployment of our method for a brick-picking application in a construction scenario.
Resolving Symmetry Ambiguity in Correspondence-based Methods for Instance-level Object Pose Estimation
May 17, 2024Estimating the 6D pose of an object from a single RGB image is a critical task that becomes additionally challenging when dealing with symmetric objects. Recent approaches typically establish one-to-one correspondences between image pixels and 3D object surface vertices. However, the utilization of one-to-one correspondences introduces ambiguity for symmetric objects. To address this, we propose SymCode, a symmetry-aware surface encoding that encodes the object surface vertices based on one-to-many correspondences, eliminating the problem of one-to-one correspondence ambiguity. We also introduce SymNet, a fast end-to-end network that directly regresses the 6D pose parameters without solving a PnP problem. We demonstrate faster runtime and comparable accuracy achieved by our method on the T-LESS and IC-BIN benchmarks of mostly symmetric objects. Our source code will be released upon acceptance.
HiPose: Hierarchical Binary Surface Encoding and Correspondence Pruning for RGB-D 6DoF Object Pose Estimation
Nov 21, 2023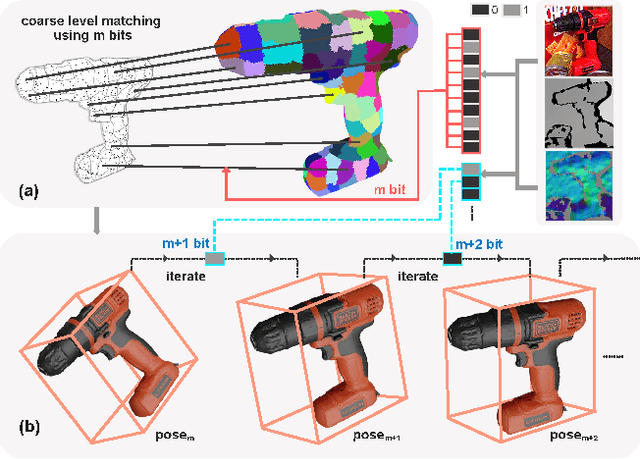

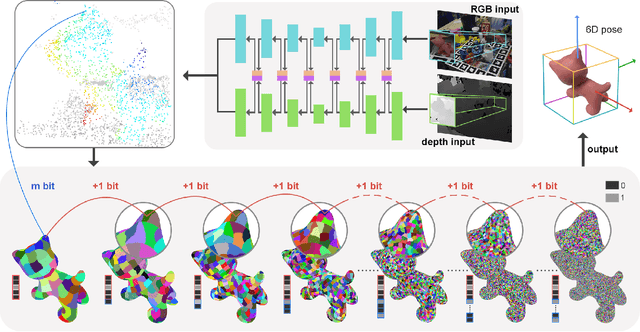
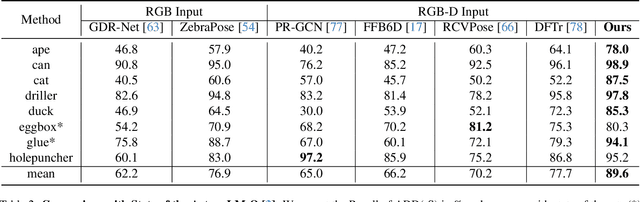
In this work, we present a novel dense-correspondence method for 6DoF object pose estimation from a single RGB-D image. While many existing data-driven methods achieve impressive performance, they tend to be time-consuming due to their reliance on rendering-based refinement approaches. To circumvent this limitation, we present HiPose, which establishes 3D-3D correspondences in a coarse-to-fine manner with a hierarchical binary surface encoding. Unlike previous dense-correspondence methods, we estimate the correspondence surface by employing point-to-surface matching and iteratively constricting the surface until it becomes a correspondence point while gradually removing outliers. Extensive experiments on public benchmarks LM-O, YCB-V, and T-Less demonstrate that our method surpasses all refinement-free methods and is even on par with expensive refinement-based approaches. Crucially, our approach is computationally efficient and enables real-time critical applications with high accuracy requirements. Code and models will be released.
Assisting Scene Graph Generation with Self-Supervision
Aug 08, 2020

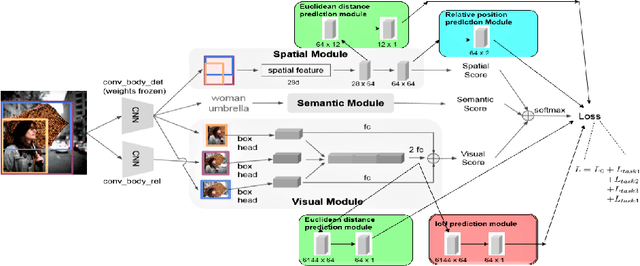

Research in scene graph generation has quickly gained traction in the past few years because of its potential to help in downstream tasks like visual question answering, image captioning, etc. Many interesting approaches have been proposed to tackle this problem. Most of these works have a pre-trained object detection model as a preliminary feature extractor. Therefore, getting object bounding box proposals from the object detection model is relatively cheaper. We take advantage of this ready availability of bounding box annotations produced by the pre-trained detector. We propose a set of three novel yet simple self-supervision tasks and train them as auxiliary multi-tasks to the main model. While comparing, we train the base-model from scratch with these self-supervision tasks, we achieve state-of-the-art results in all the metrics and recall settings. We also resolve some of the confusion between two types of relationships: geometric and possessive, by training the model with the proposed self-supervision losses. We use the benchmark dataset, Visual Genome to conduct our experiments and show our results.