 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssisting Scene Graph Generation with Self-Supervision
Paper and Code
Aug 08, 2020

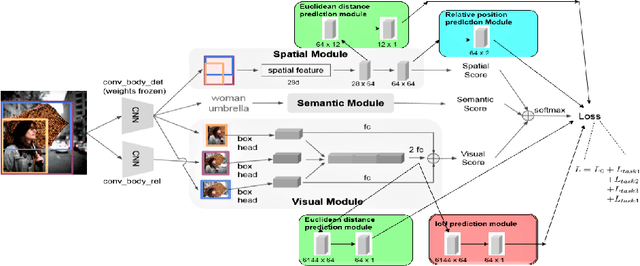

Research in scene graph generation has quickly gained traction in the past few years because of its potential to help in downstream tasks like visual question answering, image captioning, etc. Many interesting approaches have been proposed to tackle this problem. Most of these works have a pre-trained object detection model as a preliminary feature extractor. Therefore, getting object bounding box proposals from the object detection model is relatively cheaper. We take advantage of this ready availability of bounding box annotations produced by the pre-trained detector. We propose a set of three novel yet simple self-supervision tasks and train them as auxiliary multi-tasks to the main model. While comparing, we train the base-model from scratch with these self-supervision tasks, we achieve state-of-the-art results in all the metrics and recall settings. We also resolve some of the confusion between two types of relationships: geometric and possessive, by training the model with the proposed self-supervision losses. We use the benchmark dataset, Visual Genome to conduct our experiments and show our results.