 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Object-in-Gripper Segmentation from Robotic Motions
Paper and Code

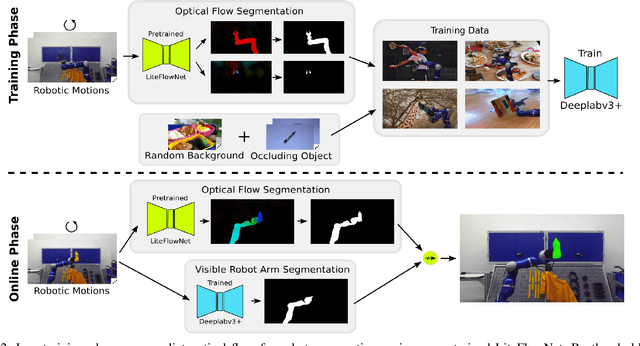

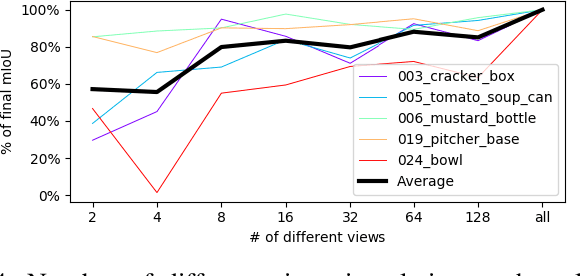
We present a novel technique to automatically generate annotated data for important robotic perception tasks such as object segmentation and 3D object reconstruction using a robot manipulator. Our self-supervised method can segment unknown objects from a robotic gripper in RGB video sequences by exploiting motion and temporal cues. The key aspect of our approach in contrast to existing systems is its independence of any hardware specifics such as extrinsic and intrinsic camera calibration and a robot model. We achieve this using a two-step process: First, we learn to predict segmentation masks for our given manipulator using optical flow estimation. Then, these masks are used in combination with motion cues to automatically distinguish between the manipulator, the background, and the unknown, grasped object. We perform a thorough comparison with alternative baselines and approaches in the literature. The obtained object views and masks are suitable training data for segmentation networks that generalize to novel environments and also allow for watertight 3D object reconstruction.