 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning
May 17, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities but often face challenges with tasks requiring sophisticated reasoning. While Chain-of-Thought (CoT) prompting significantly enhances reasoning, it indiscriminately generates lengthy reasoning steps for all queries, leading to substantial computational costs and inefficiency, especially for simpler inputs. To address this critical issue, we introduce AdaCoT (Adaptive Chain-of-Thought), a novel framework enabling LLMs to adaptively decide when to invoke CoT. AdaCoT framed adaptive reasoning as a Pareto optimization problem that seeks to balance model performance with the costs associated with CoT invocation (both frequency and computational overhead). We propose a reinforcement learning (RL) based method, specifically utilizing Proximal Policy Optimization (PPO), to dynamically control the CoT triggering decision boundary by adjusting penalty coefficients, thereby allowing the model to determine CoT necessity based on implicit query complexity. A key technical contribution is Selective Loss Masking (SLM), designed to counteract decision boundary collapse during multi-stage RL training, ensuring robust and stable adaptive triggering. Experimental results demonstrate that AdaCoT successfully navigates the Pareto frontier, achieving substantial reductions in CoT usage for queries not requiring elaborate reasoning. For instance, on our production traffic testset, AdaCoT reduced CoT triggering rates to as low as 3.18\% and decreased average response tokens by 69.06%, while maintaining high performance on complex tasks.
Exploring Data Scaling Trends and Effects in Reinforcement Learning from Human Feedback
Mar 31, 2025Reinforcement Learning from Human Feedback (RLHF) is crucial for aligning large language models with human preferences. While recent research has focused on algorithmic improvements, the importance of prompt-data construction has been overlooked. This paper addresses this gap by exploring data-driven bottlenecks in RLHF performance scaling, particularly reward hacking and decreasing response diversity. We introduce a hybrid reward system combining reasoning task verifiers (RTV) and a generative reward model (GenRM) to mitigate reward hacking. We also propose a novel prompt-selection method, Pre-PPO, to maintain response diversity and enhance learning effectiveness. Additionally, we find that prioritizing mathematical and coding tasks early in RLHF training significantly improves performance. Experiments across two model sizes validate our methods' effectiveness and scalability. Results show that RTV is most resistant to reward hacking, followed by GenRM with ground truth, and then GenRM with SFT Best-of-N responses. Our strategies enable rapid capture of subtle task-specific distinctions, leading to substantial improvements in overall RLHF performance. This work highlights the importance of careful data construction and provides practical methods to overcome performance barriers in RLHF.
UTMath: Math Evaluation with Unit Test via Reasoning-to-Coding Thoughts
Nov 11, 2024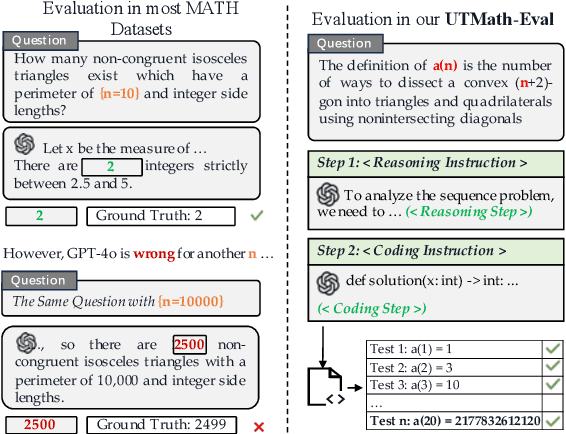
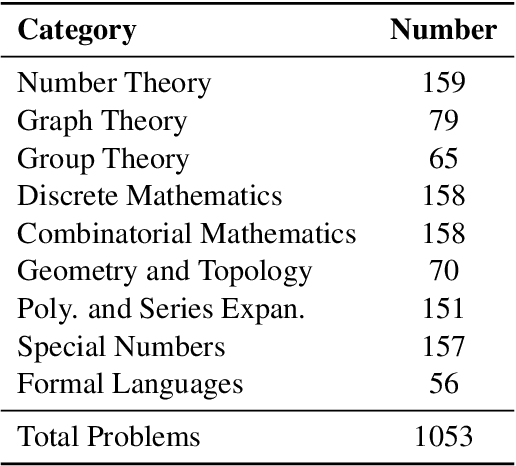
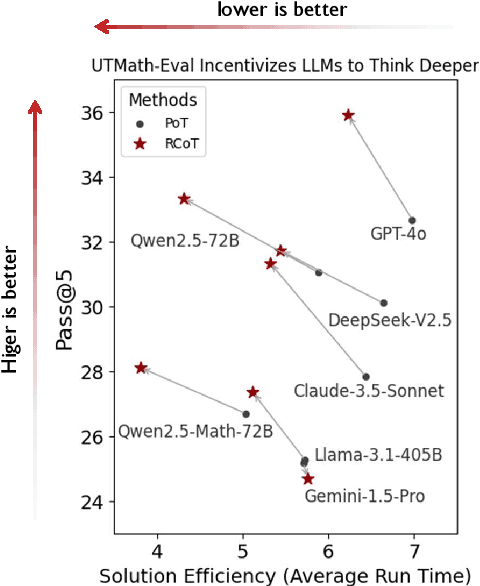
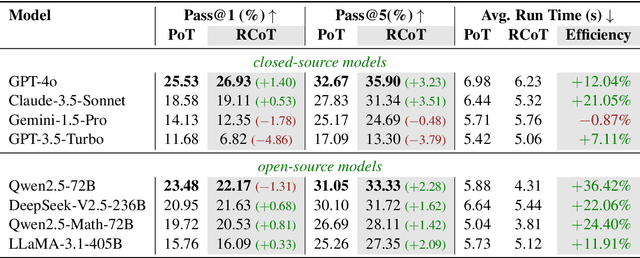
The evaluation of mathematical reasoning capabilities is essential for advancing Artificial General Intelligence (AGI). While Large Language Models (LLMs) have shown impressive performance in solving mathematical problems, existing benchmarks such as GSM8K and MATH present limitations, including narrow problem definitions with specific numbers and reliance on predetermined rules that hinder accurate assessments of reasoning and adaptability. This paper introduces the UTMath Benchmark, which robustly evaluates the models through extensive unit tests. It consists of 1,053 problems across 9 mathematical domains, with over 68 test cases per problem. We propose an innovative evaluation framework inspired by unit testing in software development, focusing on both accuracy and reliability of results. Furthermore, we introduce the Reasoning-to-Coding of Thoughts (RCoT) approach, which encourages LLMs to perform explicit reasoning before generating code, leading to generating more advanced solution and improved performance. Furthermore, we are releasing not only the UTMath benchmark but also the UTMath-Train training dataset (more than 70k samples), to support the community in further exploring mathematical reasoning.
How to Understand Whole Software Repository?
Jun 03, 2024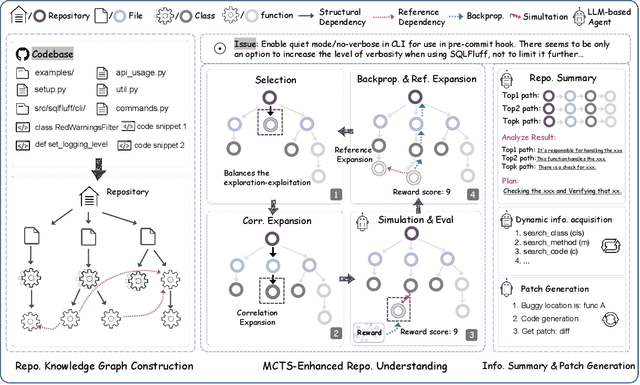
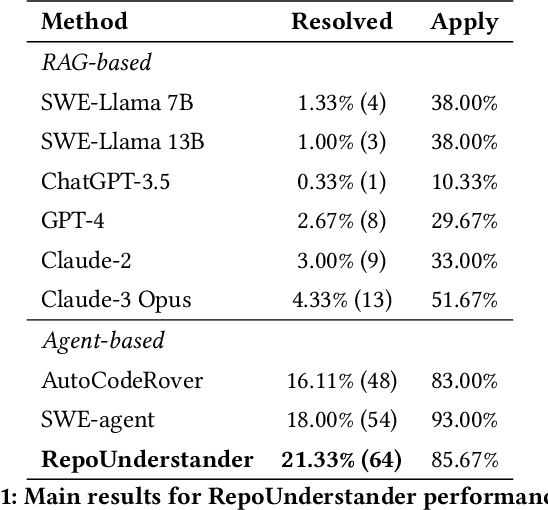

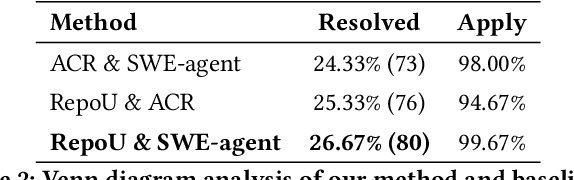
Recently, Large Language Model (LLM) based agents have advanced the significant development of Automatic Software Engineering (ASE). Although verified effectiveness, the designs of the existing methods mainly focus on the local information of codes, e.g., issues, classes, and functions, leading to limitations in capturing the global context and interdependencies within the software system. From the practical experiences of the human SE developers, we argue that an excellent understanding of the whole repository will be the critical path to ASE. However, understanding the whole repository raises various challenges, e.g., the extremely long code input, the noisy code information, the complex dependency relationships, etc. To this end, we develop a novel ASE method named RepoUnderstander by guiding agents to comprehensively understand the whole repositories. Specifically, we first condense the critical information of the whole repository into the repository knowledge graph in a top-to-down mode to decrease the complexity of repository. Subsequently, we empower the agents the ability of understanding whole repository by proposing a Monte Carlo tree search based repository exploration strategy. In addition, to better utilize the repository-level knowledge, we guide the agents to summarize, analyze, and plan. Then, they can manipulate the tools to dynamically acquire information and generate the patches to solve the real-world GitHub issues. Extensive experiments demonstrate the superiority and effectiveness of the proposed RepoUnderstander. It achieved 18.5\% relative improvement on the SWE-bench Lite benchmark compared to SWE-agent.