 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCITAT: A Question Answering Benchmark for Scientific Tables and Text Covering Diverse Reasoning Types
Dec 16, 2024



Scientific question answering (SQA) is an important task aimed at answering questions based on papers. However, current SQA datasets have limited reasoning types and neglect the relevance between tables and text, creating a significant gap with real scenarios. To address these challenges, we propose a QA benchmark for scientific tables and text with diverse reasoning types (SciTaT). To cover more reasoning types, we summarize various reasoning types from real-world questions. To involve both tables and text, we require the questions to incorporate tables and text as much as possible. Based on SciTaT, we propose a strong baseline (CaR), which combines various reasoning methods to address different reasoning types and process tables and text at the same time. CaR brings average improvements of 12.9% over other baselines on SciTaT, validating its effectiveness. Error analysis reveals the challenges of SciTaT, such as complex numerical calculations and domain knowledge.
TART: An Open-Source Tool-Augmented Framework for Explainable Table-based Reasoning
Sep 18, 2024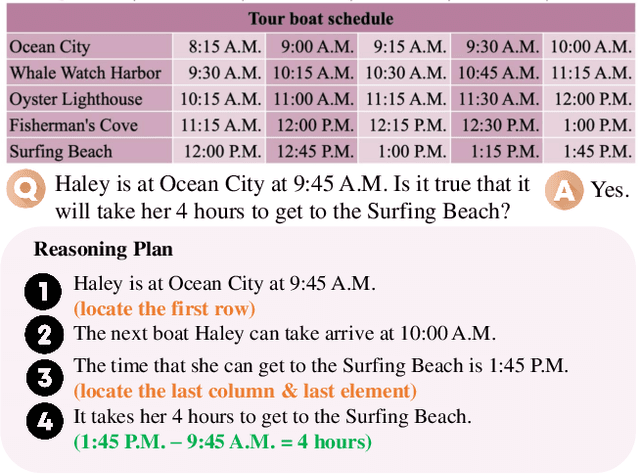
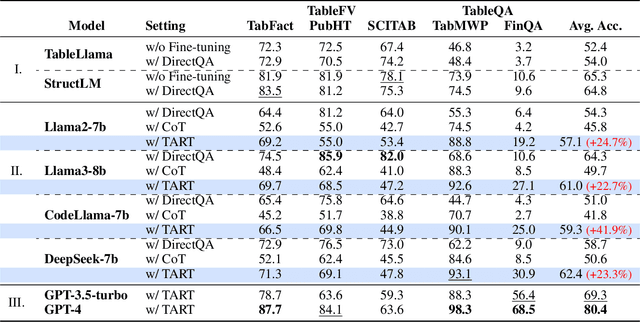
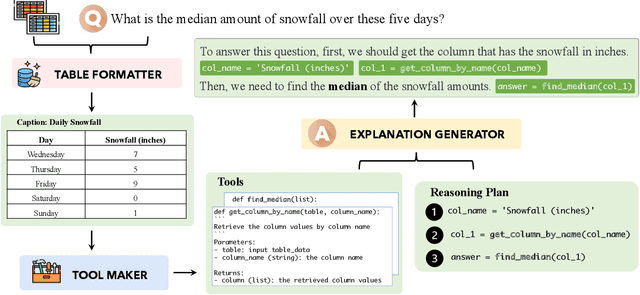
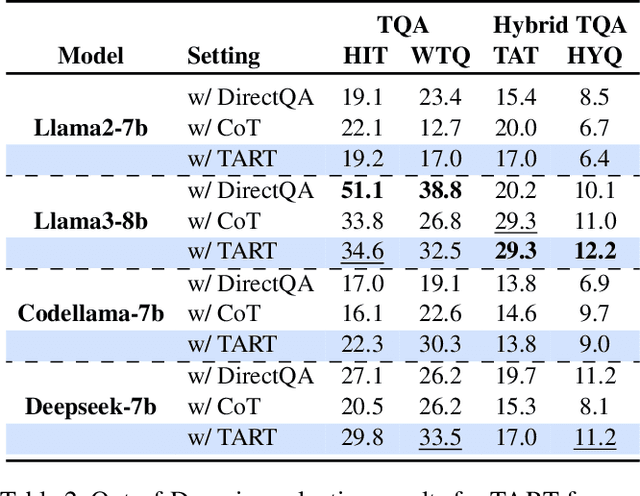
Current Large Language Models (LLMs) exhibit limited ability to understand table structures and to apply precise numerical reasoning, which is crucial for tasks such as table question answering (TQA) and table-based fact verification (TFV). To address these challenges, we introduce our Tool-Augmented Reasoning framework for Tables (TART), which integrates LLMs with specialized tools. TART contains three key components: a table formatter to ensure accurate data representation, a tool maker to develop specific computational tools, and an explanation generator to maintain explainability. We also present the TOOLTAB dataset, a new benchmark designed specifically for training LLMs in table-tool integration. Our experiments indicate that TART achieves substantial improvements over existing methods (e.g., Chain-of-Thought) by improving both the precision of data processing and the clarity of the reasoning process. Notably, TART paired with CodeLlama achieves 90.0% of the accuracy of the closed-sourced LLM GPT-3.5-turbo, highlighting its robustness in diverse real-world scenarios. All the code and data are available at https://github.com/XinyuanLu00/TART.
MMLongBench-Doc: Benchmarking Long-context Document Understanding with Visualizations
Jul 01, 2024Understanding documents with rich layouts and multi-modal components is a long-standing and practical task. Recent Large Vision-Language Models (LVLMs) have made remarkable strides in various tasks, particularly in single-page document understanding (DU). However, their abilities on long-context DU remain an open problem. This work presents MMLongBench-Doc, a long-context, multi-modal benchmark comprising 1,062 expert-annotated questions. Distinct from previous datasets, it is constructed upon 130 lengthy PDF-formatted documents with an average of 49.4 pages and 20,971 textual tokens. Towards comprehensive evaluation, answers to these questions rely on pieces of evidence from (1) different sources (text, image, chart, table, and layout structure) and (2) various locations (i.e. page number). Moreover, 33.2% of the questions are cross-page questions requiring evidence across multiple pages. 22.8% of the questions are designed to be unanswerable for detecting potential hallucinations. Experiments on 14 LVLMs demonstrate that long-context DU greatly challenges current models. Notably, the best-performing model, GPT-4o, achieves an F1 score of only 42.7%, while the second-best, GPT-4V, scores 31.4%. Furthermore, 12 LVLMs (all except GPT-4o and GPT-4V) even present worse performance than their LLM counterparts which are fed with lossy-parsed OCR documents. These results validate the necessity of future research toward more capable long-context LVLMs. Project Page: https://mayubo2333.github.io/MMLongBench-Doc
QACHECK: A Demonstration System for Question-Guided Multi-Hop Fact-Checking
Oct 11, 2023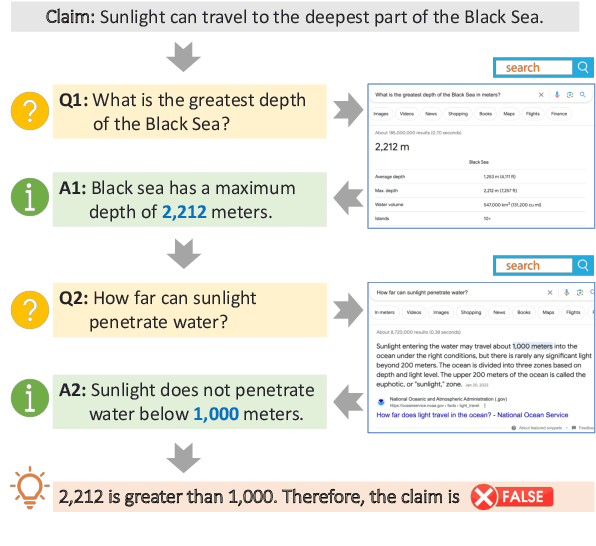
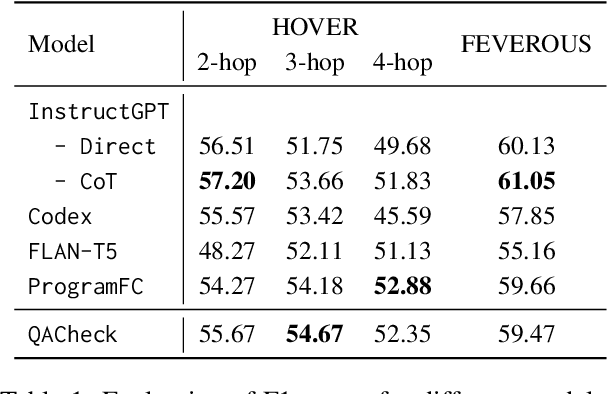
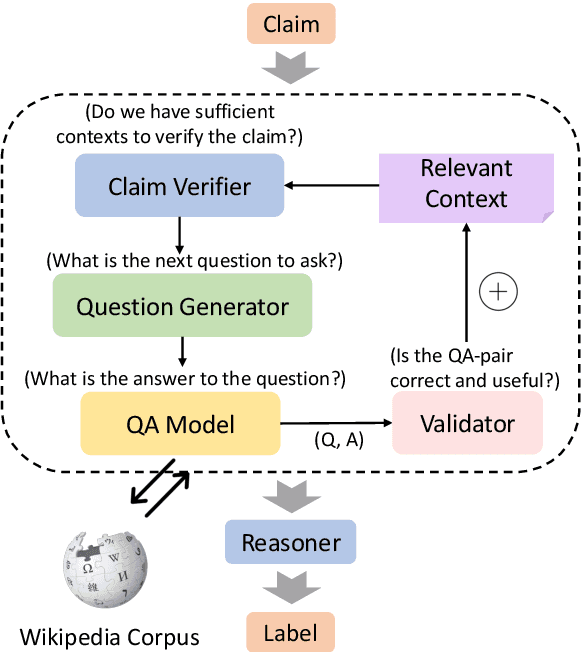
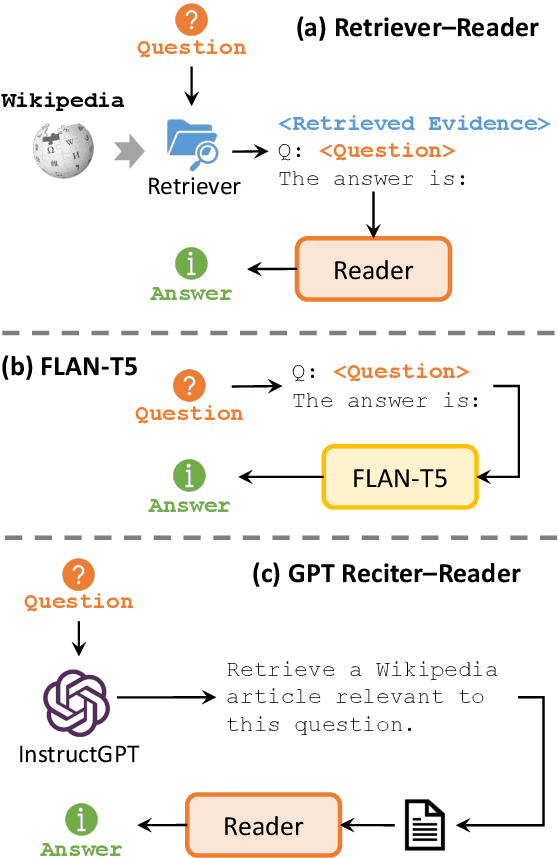
Fact-checking real-world claims often requires complex, multi-step reasoning due to the absence of direct evidence to support or refute them. However, existing fact-checking systems often lack transparency in their decision-making, making it challenging for users to comprehend their reasoning process. To address this, we propose the Question-guided Multi-hop Fact-Checking (QACHECK) system, which guides the model's reasoning process by asking a series of questions critical for verifying a claim. QACHECK has five key modules: a claim verifier, a question generator, a question-answering module, a QA validator, and a reasoner. Users can input a claim into QACHECK, which then predicts its veracity and provides a comprehensive report detailing its reasoning process, guided by a sequence of (question, answer) pairs. QACHECK also provides the source of evidence supporting each question, fostering a transparent, explainable, and user-friendly fact-checking process. A recorded video of QACHECK is at https://www.youtube.com/watch?v=ju8kxSldM64
Fact-Checking Complex Claims with Program-Guided Reasoning
May 22, 2023
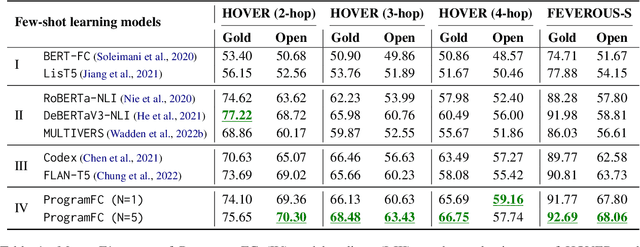
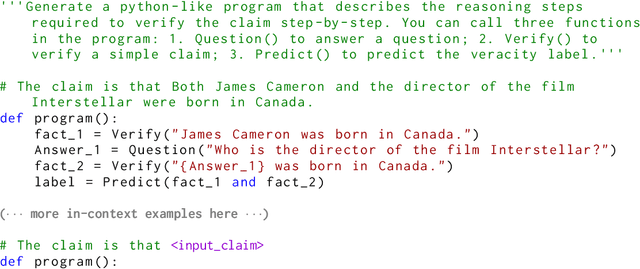
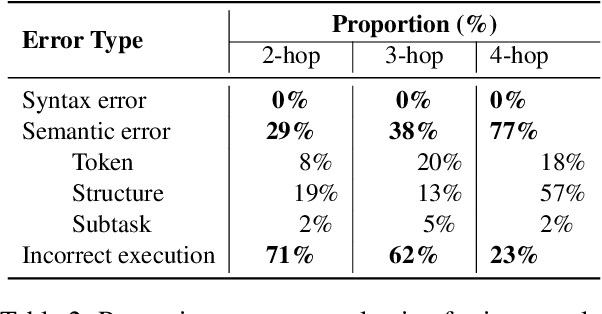
Fact-checking real-world claims often requires collecting multiple pieces of evidence and applying complex multi-step reasoning. In this paper, we present Program-Guided Fact-Checking (ProgramFC), a novel fact-checking model that decomposes complex claims into simpler sub-tasks that can be solved using a shared library of specialized functions. We first leverage the in-context learning ability of large language models to generate reasoning programs to guide the verification process. Afterward, we execute the program by delegating each sub-task to the corresponding sub-task handler. This process makes our model both explanatory and data-efficient, providing clear explanations of its reasoning process and requiring minimal training data. We evaluate ProgramFC on two challenging fact-checking datasets and show that it outperforms seven fact-checking baselines across different settings of evidence availability, with explicit output programs that benefit human debugging. Our codes and data are publicly available at https://github.com/mbzuai-nlp/ProgramFC.
SCITAB: A Challenging Benchmark for Compositional Reasoning and Claim Verification on Scientific Tables
May 22, 2023Scientific fact-checking is crucial for ensuring the accuracy, reliability, and trustworthiness of scientific claims. However, existing benchmarks are limited in terms of their claim diversity, reliance on text-based evidence, and oversimplification of scientific reasoning. To address these gaps, we introduce SCITAB, a novel dataset comprising 1,225 challenging scientific claims requiring compositional reasoning with scientific tables. The claims in SCITAB are derived from the actual scientific statements, and the evidence is presented as tables, closely mirroring real-world fact-checking scenarios. We establish benchmarks on SCITAB using state-of-the-art models, revealing its inherent difficulty and highlighting limitations in existing prompting methods. Our error analysis identifies unique challenges, including ambiguous expressions and irrelevant claims, suggesting future research directions. The code and the data are publicly available at https://github.com/XinyuanLu00/SciTab.
Improving Recommendation Systems with User Personality Inferred from Product Reviews
Mar 21, 2023
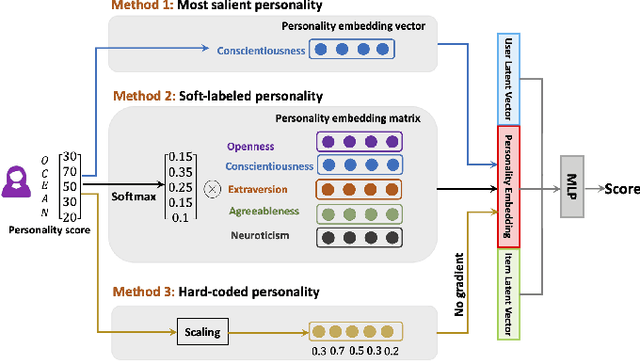
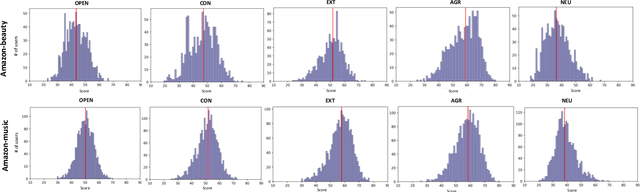
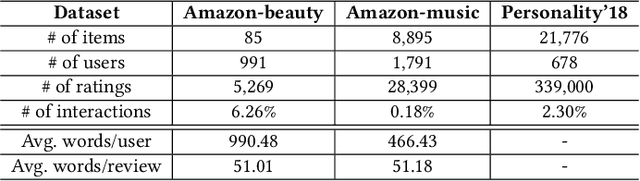
Personality is a psychological factor that reflects people's preferences, which in turn influences their decision-making. We hypothesize that accurate modeling of users' personalities improves recommendation systems' performance. However, acquiring such personality profiles is both sensitive and expensive. We address this problem by introducing a novel method to automatically extract personality profiles from public product review text. We then design and assess three context-aware recommendation architectures that leverage the profiles to test our hypothesis. Experiments on our two newly contributed personality datasets -- Amazon-beauty and Amazon-music -- validate our hypothesis, showing performance boosts of 3--28%.Our analysis uncovers that varying personality types contribute differently to recommendation performance: open and extroverted personalities are most helpful in music recommendation, while a conscientious personality is most helpful in beauty product recommendation.
Deep Video Harmonization with Color Mapping Consistency
May 02, 2022

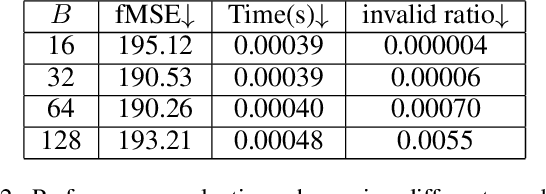
Video harmonization aims to adjust the foreground of a composite video to make it compatible with the background. So far, video harmonization has only received limited attention and there is no public dataset for video harmonization. In this work, we construct a new video harmonization dataset HYouTube by adjusting the foreground of real videos to create synthetic composite videos. Moreover, we consider the temporal consistency in video harmonization task. Unlike previous works which establish the spatial correspondence, we design a novel framework based on the assumption of color mapping consistency, which leverages the color mapping of neighboring frames to refine the current frame. Extensive experiments on our HYouTube dataset prove the effectiveness of our proposed framework. Our dataset and code are available at https://github.com/bcmi/Video-Harmonization-Dataset-HYouTube.
HYouTube: Video Harmonization Dataset
Sep 18, 2021

Video composition aims to generate a composite video by combining the foreground of one video with the background of another video, but the inserted foreground may be incompatible with the background in terms of color and illumination. Video harmonization aims to adjust the foreground of a composite video to make it compatible with the background. So far, video harmonization has only received limited attention and there is no public dataset for video harmonization. In this work, we construct a new video harmonization dataset HYouTube by adjusting the foreground of real videos to create synthetic composite videos. Considering the domain gap between real composite videos and synthetic composite videos, we additionally create 100 real composite videos via copy-and-paste. Datasets are available at https://github.com/bcmi/Video-Harmonization-Dataset-HYouTube.
Learning to Generate Questions with Adaptive Copying Neural Networks
Sep 17, 2019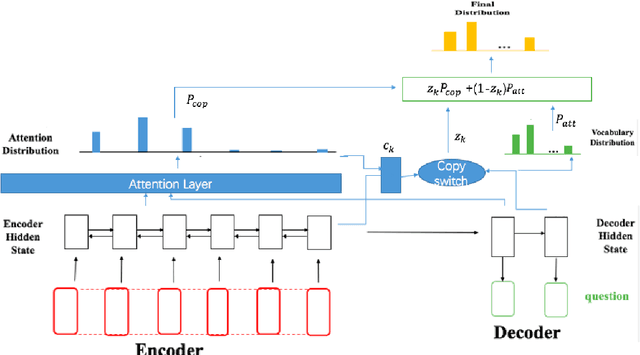
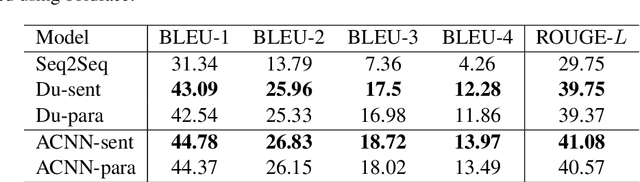

Automatic question generation is an important problem in natural language processing. In this paper we propose a novel adaptive copying recurrent neural network model to tackle the problem of question generation from sentences and paragraphs. The proposed model adds a copying mechanism component onto a bidirectional LSTM architecture to generate more suitable questions adaptively from the input data. Our experimental results show the proposed model can outperform the state-of-the-art question generation methods in terms of BLEU and ROUGE evaluation scores.