 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCE-GOCD: Central Entity-Guided Graph Optimization for Community Detection to Augment LLM Scientific Question Answering
Jan 29, 2026Large Language Models (LLMs) are increasingly used for question answering over scientific research papers. Existing retrieval augmentation methods often rely on isolated text chunks or concepts, but overlook deeper semantic connections between papers. This impairs the LLM's comprehension of scientific literature, hindering the comprehensiveness and specificity of its responses. To address this, we propose Central Entity-Guided Graph Optimization for Community Detection (CE-GOCD), a method that augments LLMs' scientific question answering by explicitly modeling and leveraging semantic substructures within academic knowledge graphs. Our approach operates by: (1) leveraging paper titles as central entities for targeted subgraph retrieval, (2) enhancing implicit semantic discovery via subgraph pruning and completion, and (3) applying community detection to distill coherent paper groups with shared themes. We evaluated the proposed method on three NLP literature-based question-answering datasets, and the results demonstrate its superiority over other retrieval-augmented baseline approaches, confirming the effectiveness of our framework.
Graph Reasoning Paradigm: Structured and Symbolic Reasoning with Topology-Aware Reinforcement Learning for Large Language Models
Jan 19, 2026Long Chain-of-Thought (LCoT), achieved by Reinforcement Learning with Verifiable Rewards (RLVR), has proven effective in enhancing the reasoning capabilities of Large Language Models (LLMs). However, reasoning in current LLMs is primarily generated as plain text, where performing semantic evaluation on such unstructured data creates a computational bottleneck during training. Despite RLVR-based optimization, existing methods still suffer from coarse-grained supervision, reward hacking, high training costs, and poor generalization. To address these issues, we propose the Graph Reasoning Paradigm (GRP), which realizes structured and symbolic reasoning, implemented via graph-structured representations with step-level cognitive labels. Building upon GRP, we further design Process-Aware Stratified Clipping Group Relative Policy Optimization (PASC-GRPO), which leverages structured evaluation to replace semantic evaluation, achieves process-aware verification through graph-structured outcome rewards, and mitigates reward hacking via stratified clipping advantage estimation. Experiments demonstrate significant improvements across mathematical reasoning and code generation tasks. Data, models, and code will be released later.
From Hypothesis to Publication: A Comprehensive Survey of AI-Driven Research Support Systems
Mar 03, 2025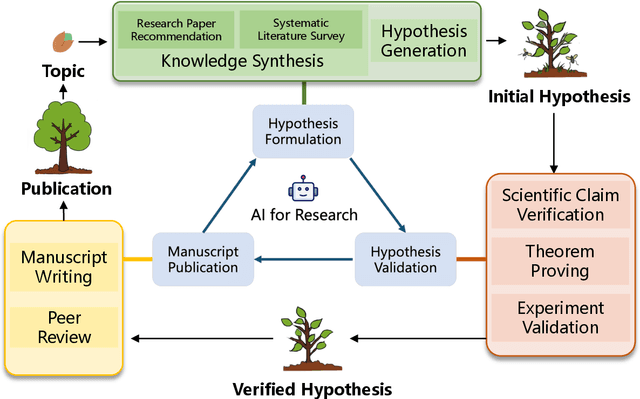
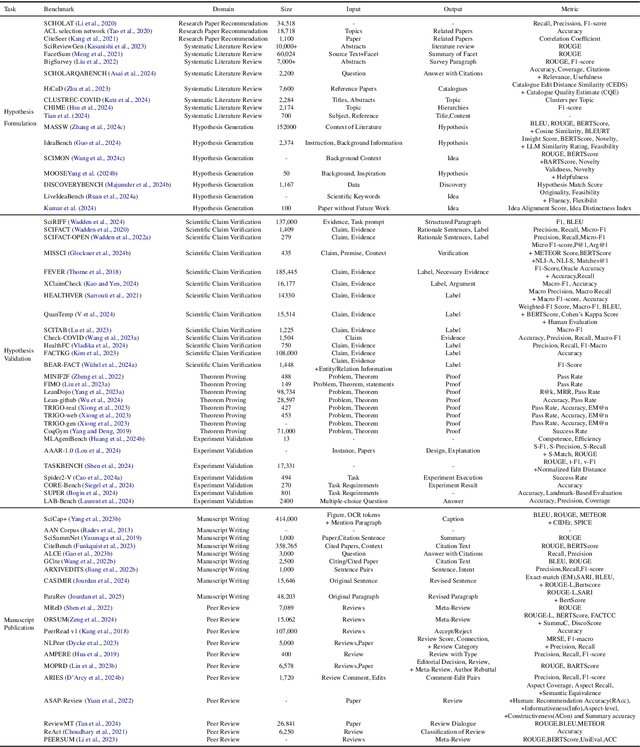

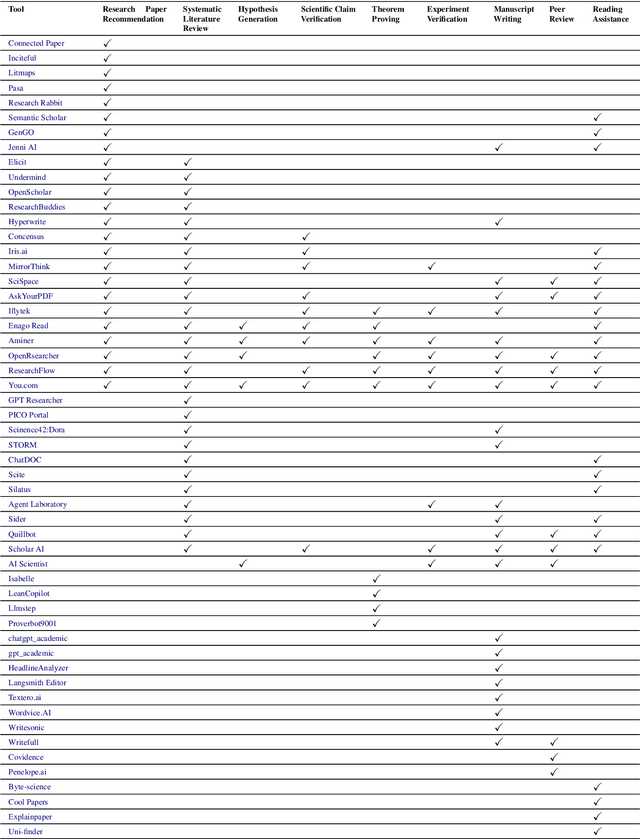
Research is a fundamental process driving the advancement of human civilization, yet it demands substantial time and effort from researchers. In recent years, the rapid development of artificial intelligence (AI) technologies has inspired researchers to explore how AI can accelerate and enhance research. To monitor relevant advancements, this paper presents a systematic review of the progress in this domain. Specifically, we organize the relevant studies into three main categories: hypothesis formulation, hypothesis validation, and manuscript publication. Hypothesis formulation involves knowledge synthesis and hypothesis generation. Hypothesis validation includes the verification of scientific claims, theorem proving, and experiment validation. Manuscript publication encompasses manuscript writing and the peer review process. Furthermore, we identify and discuss the current challenges faced in these areas, as well as potential future directions for research. Finally, we also offer a comprehensive overview of existing benchmarks and tools across various domains that support the integration of AI into the research process. We hope this paper serves as an introduction for beginners and fosters future research. Resources have been made publicly available at https://github.com/zkzhou126/AI-for-Research.
NLP-AKG: Few-Shot Construction of NLP Academic Knowledge Graph Based on LLM
Feb 20, 2025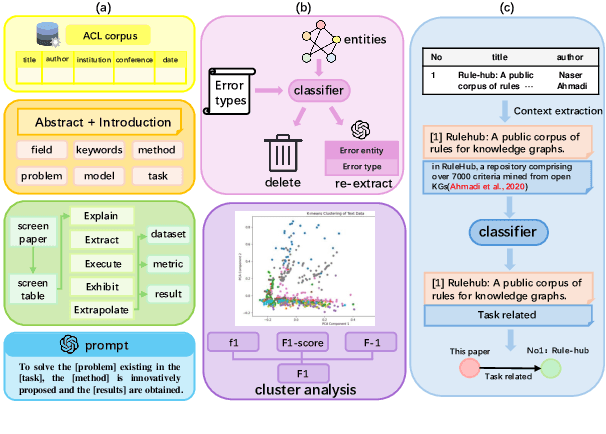
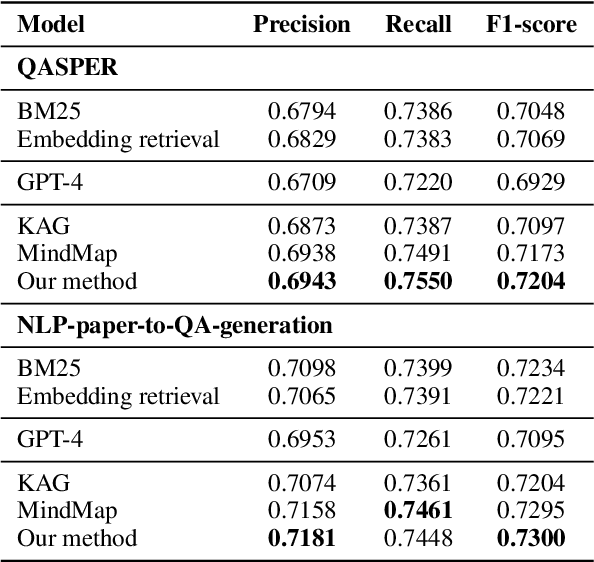
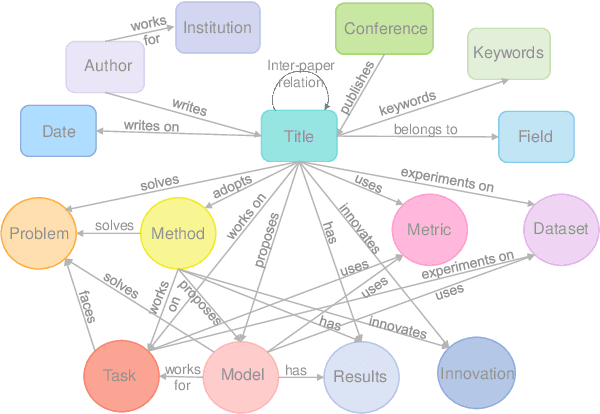
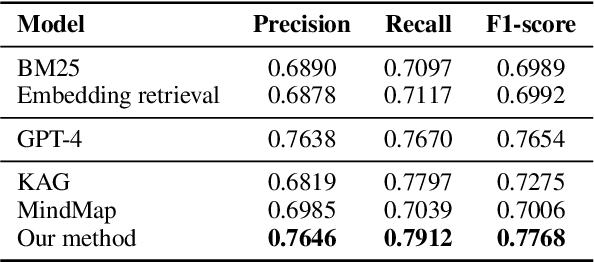
Large language models (LLMs) have been widely applied in question answering over scientific research papers. To enhance the professionalism and accuracy of responses, many studies employ external knowledge augmentation. However, existing structures of external knowledge in scientific literature often focus solely on either paper entities or domain concepts, neglecting the intrinsic connections between papers through shared domain concepts. This results in less comprehensive and specific answers when addressing questions that combine papers and concepts. To address this, we propose a novel knowledge graph framework that captures deep conceptual relations between academic papers, constructing a relational network via intra-paper semantic elements and inter-paper citation relations. Using a few-shot knowledge graph construction method based on LLM, we develop NLP-AKG, an academic knowledge graph for the NLP domain, by extracting 620,353 entities and 2,271,584 relations from 60,826 papers in ACL Anthology. Based on this, we propose a 'sub-graph community summary' method and validate its effectiveness on three NLP scientific literature question answering datasets.
Ontology-Guided Reverse Thinking Makes Large Language Models Stronger on Knowledge Graph Question Answering
Feb 17, 2025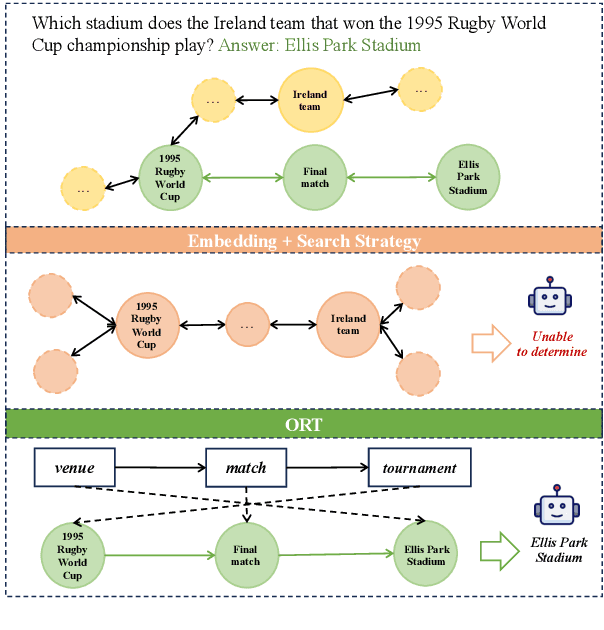

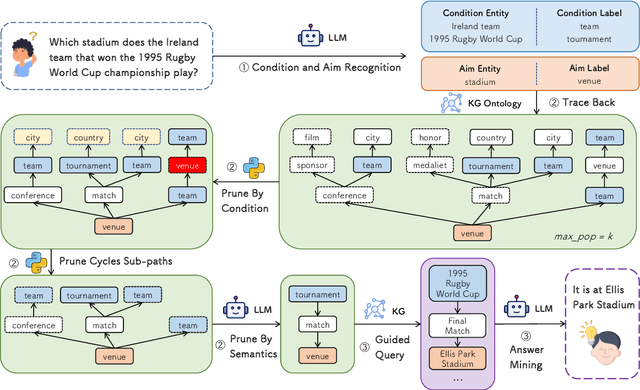

Large language models (LLMs) have shown remarkable capabilities in natural language processing. However, in knowledge graph question answering tasks (KGQA), there remains the issue of answering questions that require multi-hop reasoning. Existing methods rely on entity vector matching, but the purpose of the question is abstract and difficult to match with specific entities. As a result, it is difficult to establish reasoning paths to the purpose, which leads to information loss and redundancy. To address this issue, inspired by human reverse thinking, we propose Ontology-Guided Reverse Thinking (ORT), a novel framework that constructs reasoning paths from purposes back to conditions. ORT operates in three key phases: (1) using LLM to extract purpose labels and condition labels, (2) constructing label reasoning paths based on the KG ontology, and (3) using the label reasoning paths to guide knowledge retrieval. Experiments on the WebQSP and CWQ datasets show that ORT achieves state-of-the-art performance and significantly enhances the capability of LLMs for KGQA.
SCITAT: A Question Answering Benchmark for Scientific Tables and Text Covering Diverse Reasoning Types
Dec 16, 2024



Scientific question answering (SQA) is an important task aimed at answering questions based on papers. However, current SQA datasets have limited reasoning types and neglect the relevance between tables and text, creating a significant gap with real scenarios. To address these challenges, we propose a QA benchmark for scientific tables and text with diverse reasoning types (SciTaT). To cover more reasoning types, we summarize various reasoning types from real-world questions. To involve both tables and text, we require the questions to incorporate tables and text as much as possible. Based on SciTaT, we propose a strong baseline (CaR), which combines various reasoning methods to address different reasoning types and process tables and text at the same time. CaR brings average improvements of 12.9% over other baselines on SciTaT, validating its effectiveness. Error analysis reveals the challenges of SciTaT, such as complex numerical calculations and domain knowledge.
FLEXTAF: Enhancing Table Reasoning with Flexible Tabular Formats
Aug 16, 2024
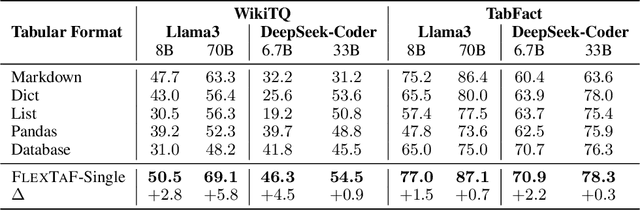
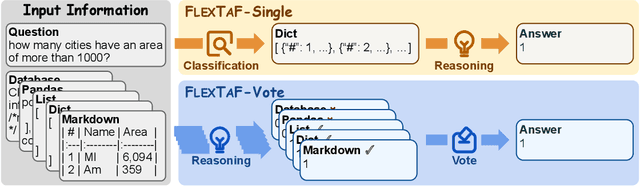
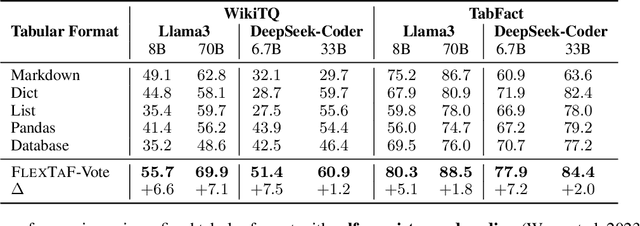
The table reasoning task aims to answer the question according to the given table. Currently, using Large Language Models (LLMs) is the predominant method for table reasoning. Most existing methods employ a fixed tabular format to represent the table, which could limit the performance. Given that each instance requires different capabilities and models possess varying abilities, we assert that different instances and models suit different tabular formats. We prove the aforementioned claim through quantitative analysis of experimental results, where different instances and models achieve different performances using various tabular formats. Building on this discussion, we propose FLEXTAF-Single and FLEXTAF-Vote to enhance table reasoning performance by employing flexible tabular formats. Specifically, (i) FLEXTAF-Single trains a classifier to predict the most suitable tabular format based on the instance and the LLM. (ii) FLEXTAF-Vote integrates the results across different formats. Our experiments on WikiTableQuestions and TabFact reveal significant improvements, with average gains of 2.3% and 4.8% compared to the best performance achieved using a fixed tabular format with greedy decoding and self-consistency decoding, thereby validating the effectiveness of our methods.
SparkRA: A Retrieval-Augmented Knowledge Service System Based on Spark Large Language Model
Aug 13, 2024
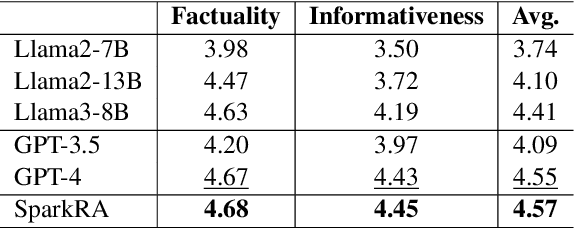

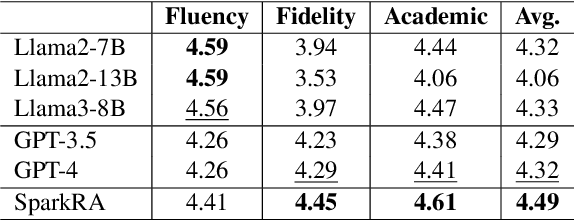
Large language models (LLMs) have shown remarkable achievements across various language tasks.To enhance the performance of LLMs in scientific literature services, we developed the scientific literature LLM (SciLit-LLM) through pre-training and supervised fine-tuning on scientific literature, building upon the iFLYTEK Spark LLM. Furthermore, we present a knowledge service system Spark Research Assistant (SparkRA) based on our SciLit-LLM. SparkRA is accessible online and provides three primary functions: literature investigation, paper reading, and academic writing. As of July 30, 2024, SparkRA has garnered over 50,000 registered users, with a total usage count exceeding 1.3 million.
LM-Combiner: A Contextual Rewriting Model for Chinese Grammatical Error Correction
Mar 26, 2024
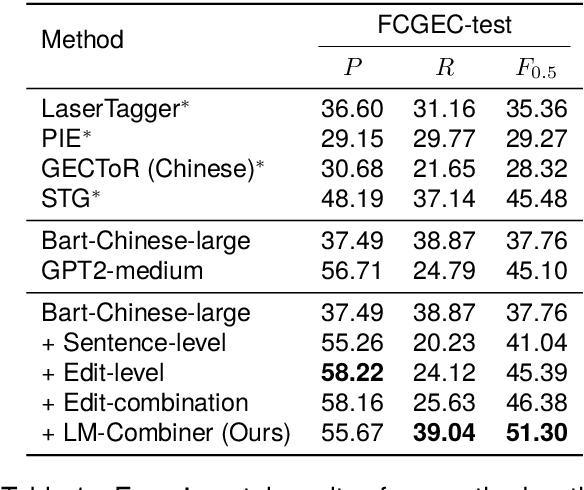
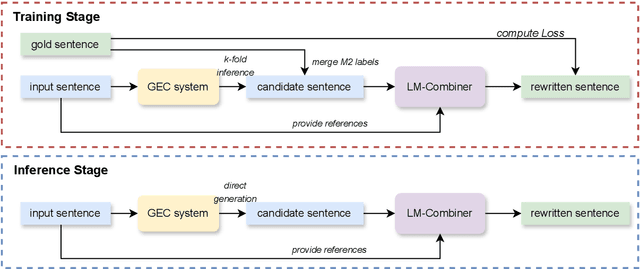
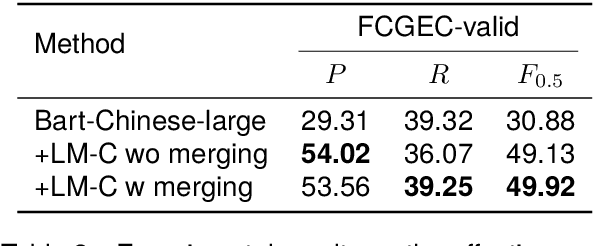
Over-correction is a critical problem in Chinese grammatical error correction (CGEC) task. Recent work using model ensemble methods based on voting can effectively mitigate over-correction and improve the precision of the GEC system. However, these methods still require the output of several GEC systems and inevitably lead to reduced error recall. In this light, we propose the LM-Combiner, a rewriting model that can directly modify the over-correction of GEC system outputs without a model ensemble. Specifically, we train the model on an over-correction dataset constructed through the proposed K-fold cross inference method, which allows it to directly generate filtered sentences by combining the original and the over-corrected text. In the inference stage, we directly take the original sentences and the output results of other systems as input and then obtain the filtered sentences through LM-Combiner. Experiments on the FCGEC dataset show that our proposed method effectively alleviates the over-correction of the original system (+18.2 Precision) while ensuring the error recall remains unchanged. Besides, we find that LM-Combiner still has a good rewriting performance even with small parameters and few training data, and thus can cost-effectively mitigate the over-correction of black-box GEC systems (e.g., ChatGPT).
CSED: A Chinese Semantic Error Diagnosis Corpus
May 09, 2023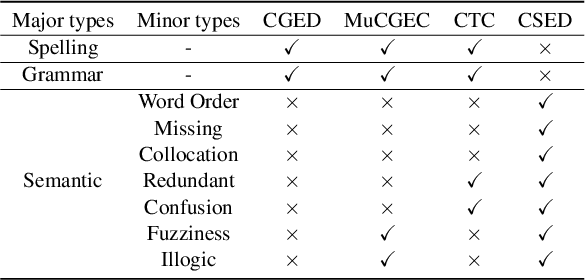
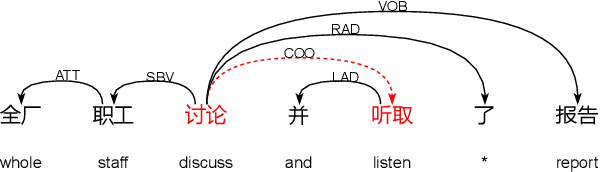
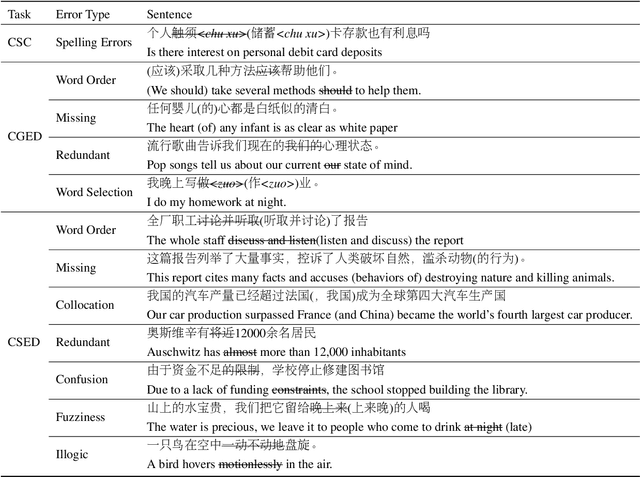
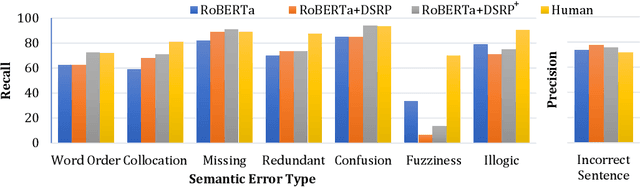
Recently, much Chinese text error correction work has focused on Chinese Spelling Check (CSC) and Chinese Grammatical Error Diagnosis (CGED). In contrast, little attention has been paid to the complicated problem of Chinese Semantic Error Diagnosis (CSED), which lacks relevant datasets. The study of semantic errors is important because they are very common and may lead to syntactic irregularities or even problems of comprehension. To investigate this, we build the CSED corpus, which includes two datasets. The one is for the CSED-Recognition (CSED-R) task. The other is for the CSED-Correction (CSED-C) task. Our annotation guarantees high-quality data through quality assurance mechanisms. Our experiments show that powerful pre-trained models perform poorly on this corpus. We also find that the CSED task is challenging, as evidenced by the fact that even humans receive a low score. This paper proposes syntax-aware models to specifically adapt to the CSED task. The experimental results show that the introduction of the syntax-aware approach is meaningful.