 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSED: A Chinese Semantic Error Diagnosis Corpus
Paper and Code
May 09, 2023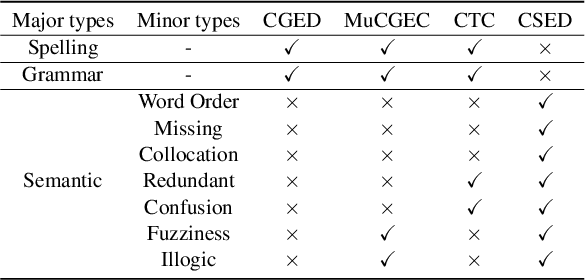
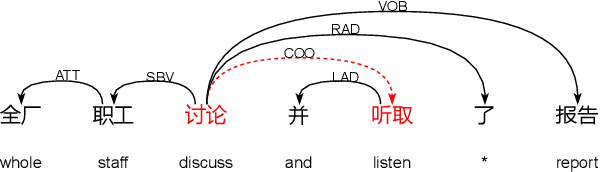
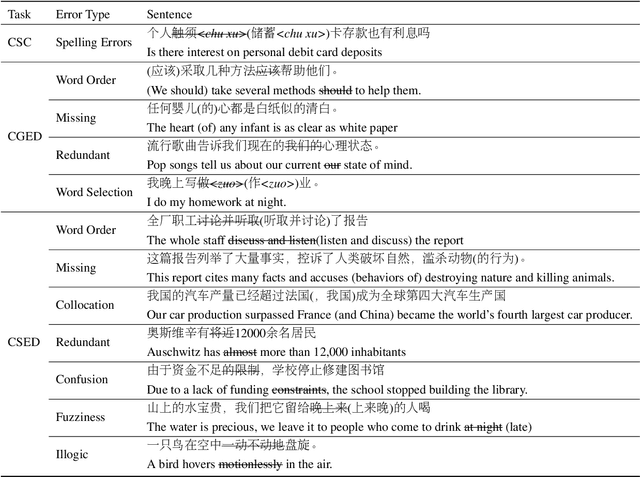
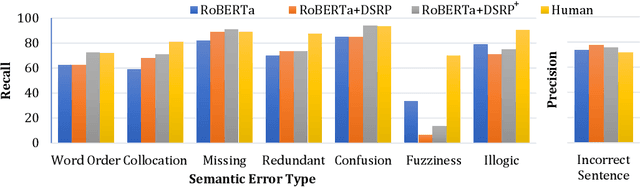
Recently, much Chinese text error correction work has focused on Chinese Spelling Check (CSC) and Chinese Grammatical Error Diagnosis (CGED). In contrast, little attention has been paid to the complicated problem of Chinese Semantic Error Diagnosis (CSED), which lacks relevant datasets. The study of semantic errors is important because they are very common and may lead to syntactic irregularities or even problems of comprehension. To investigate this, we build the CSED corpus, which includes two datasets. The one is for the CSED-Recognition (CSED-R) task. The other is for the CSED-Correction (CSED-C) task. Our annotation guarantees high-quality data through quality assurance mechanisms. Our experiments show that powerful pre-trained models perform poorly on this corpus. We also find that the CSED task is challenging, as evidenced by the fact that even humans receive a low score. This paper proposes syntax-aware models to specifically adapt to the CSED task. The experimental results show that the introduction of the syntax-aware approach is meaningful.