 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAS-Mamba: Asymmetric Self-Guided Mamba Decoupled Iterative Network for Metal Artifact Reduction
Feb 06, 2026Metal artifact significantly degrades Computed Tomography (CT) image quality, impeding accurate clinical diagnosis. However, existing deep learning approaches, such as CNN and Transformer, often fail to explicitly capture the directional geometric features of artifacts, leading to compromised structural restoration. To address these limitations, we propose the Asymmetric Self-Guided Mamba (AS-Mamba) for metal artifact reduction. Specifically, the linear propagation of metal-induced streak artifacts aligns well with the sequential modeling capability of State Space Models (SSMs). Consequently, the Mamba architecture is leveraged to explicitly capture and suppress these directional artifacts. Simultaneously, a frequency domain correction mechanism is incorporated to rectify the global amplitude spectrum, thereby mitigating intensity inhomogeneity caused by beam hardening. Furthermore, to bridge the distribution gap across diverse clinical scenarios, we introduce a self-guided contrastive regularization strategy. Extensive experiments on public andclinical dental CBCT datasets demonstrate that AS-Mamba achieves superior performance in suppressing directional streaks and preserving structural details, validating the effectiveness of integrating physical geometric priors into deep network design.
Visible Singularities Guided Correlation Network for Limited-Angle CT Reconstruction
Jan 30, 2026Limited-angle computed tomography (LACT) offers the advantages of reduced radiation dose and shortened scanning time. Traditional reconstruction algorithms exhibit various inherent limitations in LACT. Currently, most deep learning-based LACT reconstruction methods focus on multi-domain fusion or the introduction of generic priors, failing to fully align with the core imaging characteristics of LACT-such as the directionality of artifacts and directional loss of structural information, which are caused by the absence of projection angles in certain directions. Inspired by the theory of visible and invisible singularities, taking into account the aforementioned core imaging characteristics of LACT, we propose a Visible Singularities Guided Correlation network for LACT reconstruction (VSGC). The design philosophy of VSGC consists of two core steps: First, extract VS edge features from LACT images and focus the model's attention on these VS. Second, establish correlations between the VS edge features and other regions of the image. Additionally, a multi-scale loss function with anisotropic constraint is employed to constrain the model to converge in multiple aspects. Finally, qualitative and quantitative validations are conducted on both simulated and real datasets to verify the effectiveness and feasibility of the proposed design. Particularly, in comparison with alternative methods, VSGC delivers more prominent performance in small angular ranges, with the PSNR improvement of 2.45 dB and the SSIM enhancement of 1.5\%. The code is publicly available at https://github.com/yqx7150/VSGC.
From Hypothesis to Publication: A Comprehensive Survey of AI-Driven Research Support Systems
Mar 03, 2025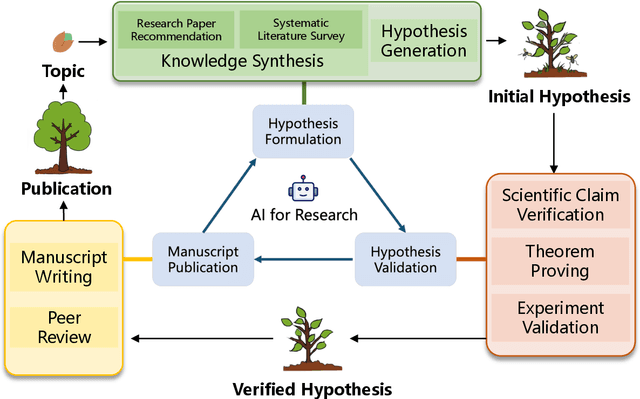
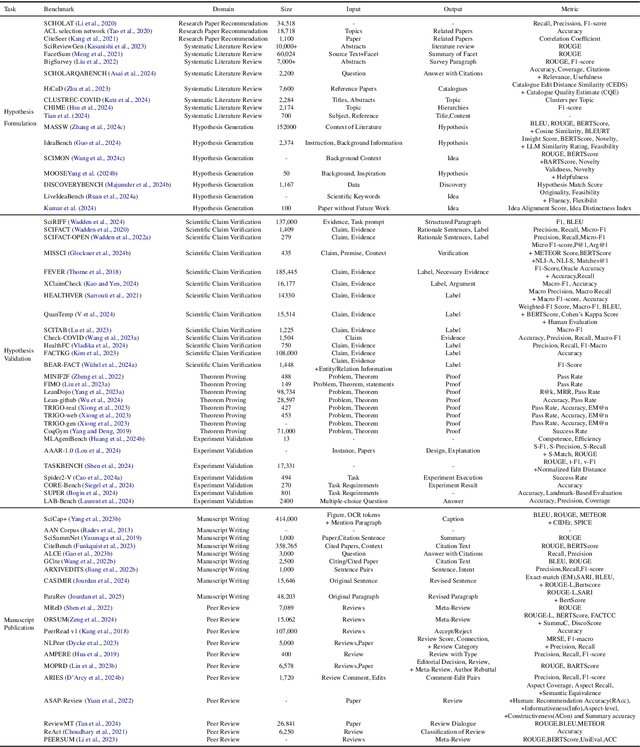

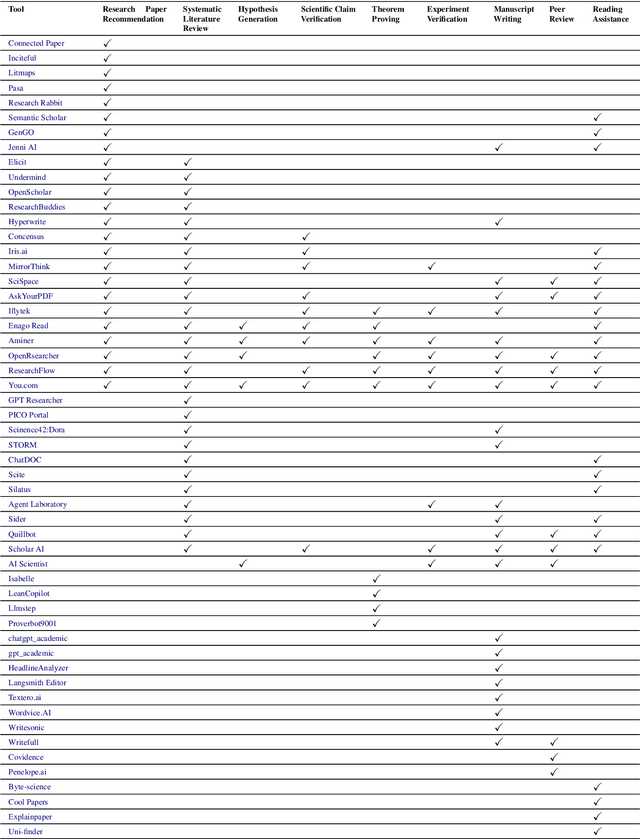
Research is a fundamental process driving the advancement of human civilization, yet it demands substantial time and effort from researchers. In recent years, the rapid development of artificial intelligence (AI) technologies has inspired researchers to explore how AI can accelerate and enhance research. To monitor relevant advancements, this paper presents a systematic review of the progress in this domain. Specifically, we organize the relevant studies into three main categories: hypothesis formulation, hypothesis validation, and manuscript publication. Hypothesis formulation involves knowledge synthesis and hypothesis generation. Hypothesis validation includes the verification of scientific claims, theorem proving, and experiment validation. Manuscript publication encompasses manuscript writing and the peer review process. Furthermore, we identify and discuss the current challenges faced in these areas, as well as potential future directions for research. Finally, we also offer a comprehensive overview of existing benchmarks and tools across various domains that support the integration of AI into the research process. We hope this paper serves as an introduction for beginners and fosters future research. Resources have been made publicly available at https://github.com/zkzhou126/AI-for-Research.
Physics-informed DeepCT: Sinogram Wavelet Decomposition Meets Masked Diffusion
Jan 17, 2025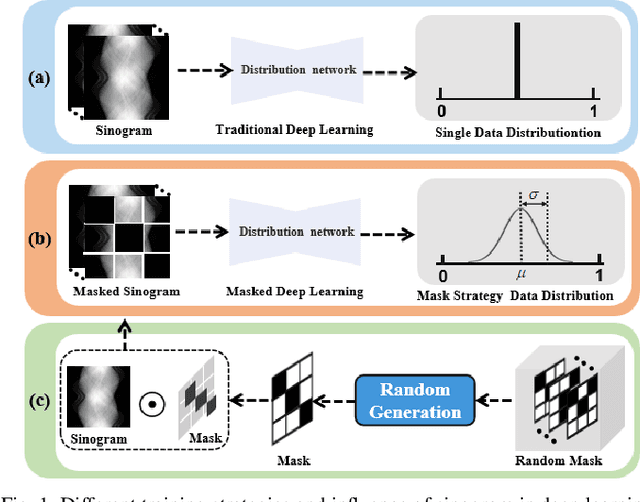
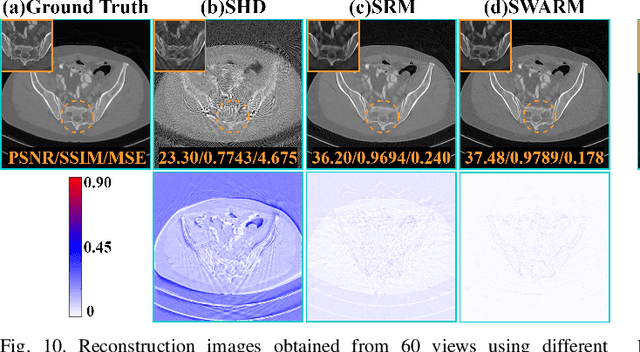
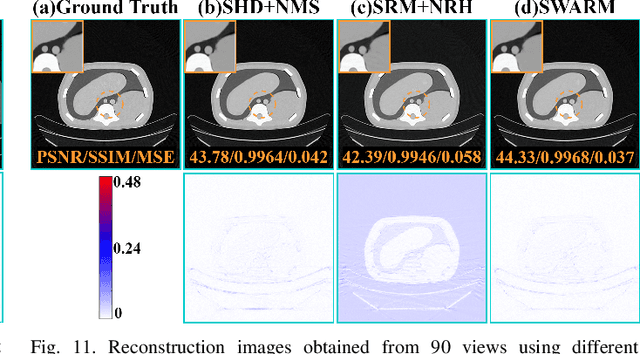
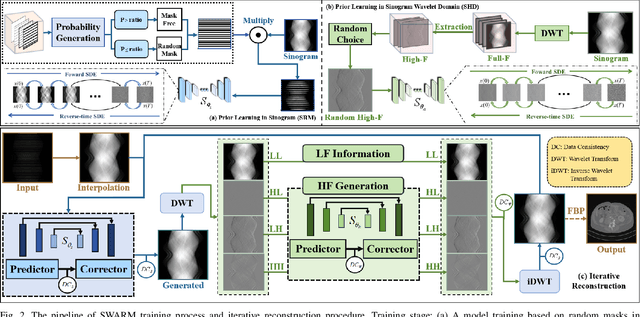
Diffusion model shows remarkable potential on sparse-view computed tomography (SVCT) reconstruction. However, when a network is trained on a limited sample space, its generalization capability may be constrained, which degrades performance on unfamiliar data. For image generation tasks, this can lead to issues such as blurry details and inconsistencies between regions. To alleviate this problem, we propose a Sinogram-based Wavelet random decomposition And Random mask diffusion Model (SWARM) for SVCT reconstruction. Specifically, introducing a random mask strategy in the sinogram effectively expands the limited training sample space. This enables the model to learn a broader range of data distributions, enhancing its understanding and generalization of data uncertainty. In addition, applying a random training strategy to the high-frequency components of the sinogram wavelet enhances feature representation and improves the ability to capture details in different frequency bands, thereby improving performance and robustness. Two-stage iterative reconstruction method is adopted to ensure the global consistency of the reconstructed image while refining its details. Experimental results demonstrate that SWARM outperforms competing approaches in both quantitative and qualitative performance across various datasets.
Discrete Modeling via Boundary Conditional Diffusion Processes
Oct 29, 2024

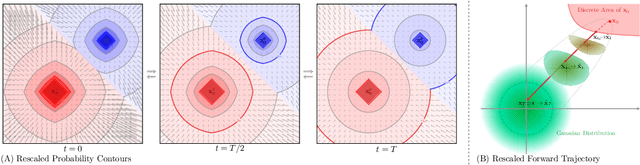

We present an novel framework for efficiently and effectively extending the powerful continuous diffusion processes to discrete modeling. Previous approaches have suffered from the discrepancy between discrete data and continuous modeling. Our study reveals that the absence of guidance from discrete boundaries in learning probability contours is one of the main reasons. To address this issue, we propose a two-step forward process that first estimates the boundary as a prior distribution and then rescales the forward trajectory to construct a boundary conditional diffusion model. The reverse process is proportionally adjusted to guarantee that the learned contours yield more precise discrete data. Experimental results indicate that our approach achieves strong performance in both language modeling and discrete image generation tasks. In language modeling, our approach surpasses previous state-of-the-art continuous diffusion language models in three translation tasks and a summarization task, while also demonstrating competitive performance compared to auto-regressive transformers. Moreover, our method achieves comparable results to continuous diffusion models when using discrete ordinal pixels and establishes a new state-of-the-art for categorical image generation on the Cifar-10 dataset.
ConvNeXt-backbone HoVerNet for nuclei segmentation and classification
Mar 29, 2022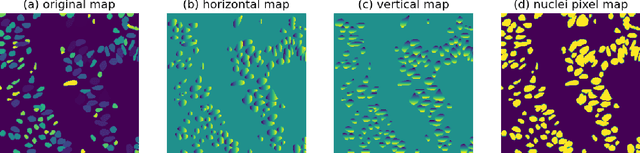
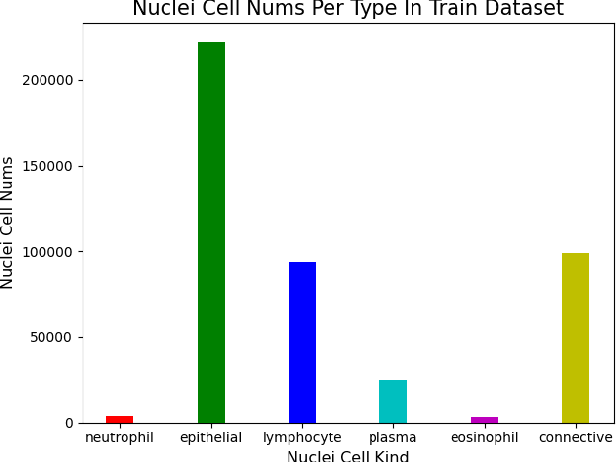
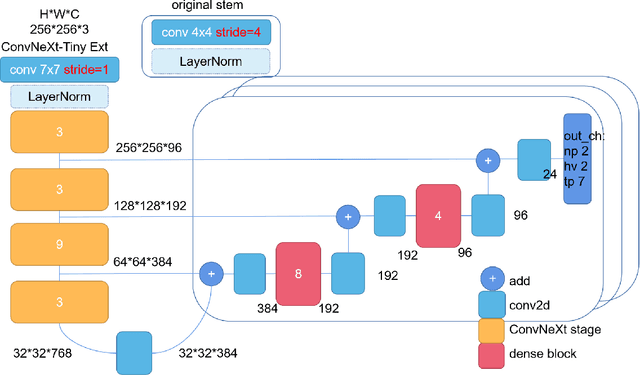

This manuscript gives a brief description of the algorithm used to participate in CoNIC Challenge 2022. After the baseline was made available, we follow the method in it and replace the ResNet baseline with ConvNeXt one. Moreover, we propose to first convert RGB space to Haematoxylin-Eosin-DAB(HED) space, then use Haematoxylin composition of origin image to smooth semantic one hot label. Afterwards, nuclei distribution of train and valid set are explored to select the best fold split for training model for final test phase submission. Results on validation set shows that even with channel of each stage smaller in number, HoVerNet with ConvNeXt-tiny backbone still improves the mPQ+ by 0.04 and multi r2 by 0.0144