 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaminoDiff: Artifact-Free Computed Laminography in Non-Destructive Testing via Diffusion Model
Jan 12, 2026Computed Laminography (CL) is a key non-destructive testing technology for the visualization of internal structures in large planar objects. The inherent scanning geometry of CL inevitably results in inter-layer aliasing artifacts, limiting its practical application, particularly in electronic component inspection. While deep learning (DL) provides a powerful paradigm for artifact removal, its effectiveness is often limited by the domain gap between synthetic data and real-world data. In this work, we present LaminoDiff, a framework to integrate a diffusion model with a high-fidelity prior representation to bridge the domain gap in CL imaging. This prior, generated via a dual-modal CT-CL fusion strategy, is integrated into the proposed network as a conditional constraint. This integration ensures high-precision preservation of circuit structures and geometric fidelity while suppressing artifacts. Extensive experiments on both simulated and real PCB datasets demonstrate that LaminoDiff achieves high-fidelity reconstruction with competitive performance in artifact suppression and detail recovery. More importantly, the results facilitate reliable automated defect recognition.
Physics-informed DeepCT: Sinogram Wavelet Decomposition Meets Masked Diffusion
Jan 17, 2025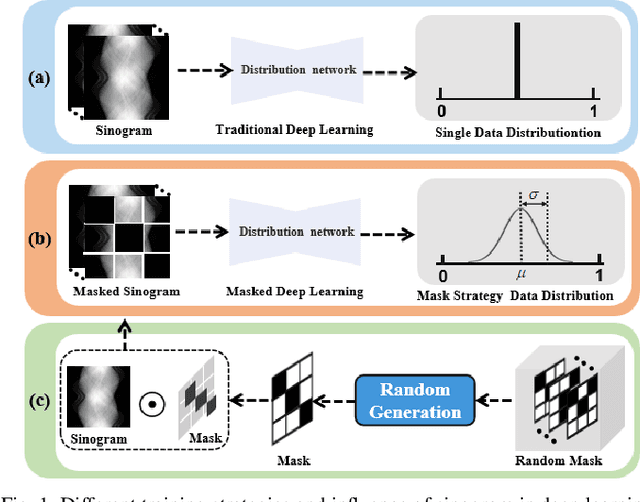
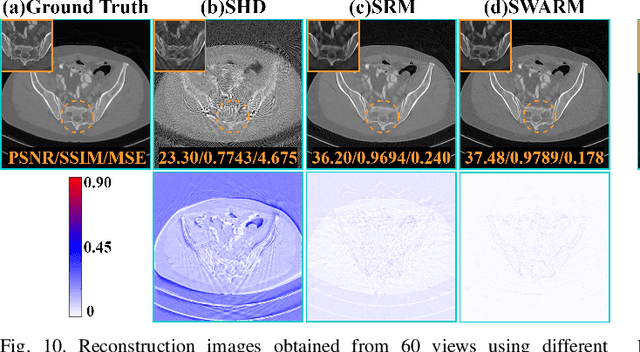
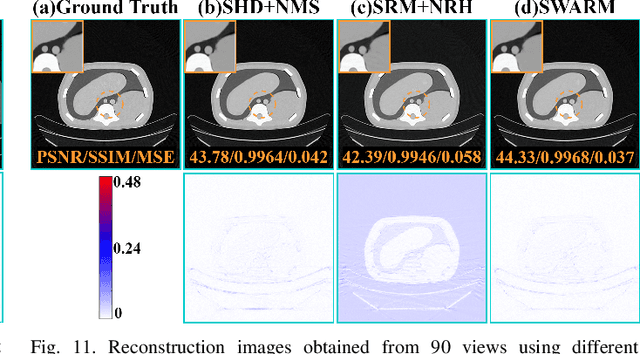
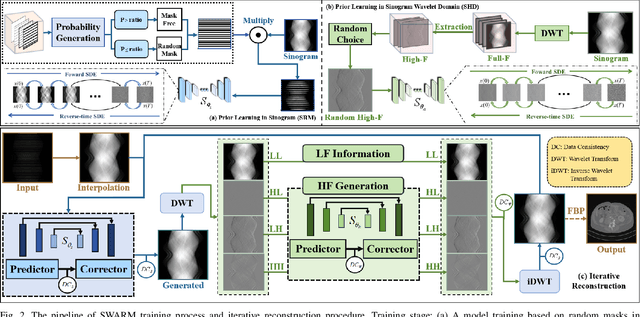
Diffusion model shows remarkable potential on sparse-view computed tomography (SVCT) reconstruction. However, when a network is trained on a limited sample space, its generalization capability may be constrained, which degrades performance on unfamiliar data. For image generation tasks, this can lead to issues such as blurry details and inconsistencies between regions. To alleviate this problem, we propose a Sinogram-based Wavelet random decomposition And Random mask diffusion Model (SWARM) for SVCT reconstruction. Specifically, introducing a random mask strategy in the sinogram effectively expands the limited training sample space. This enables the model to learn a broader range of data distributions, enhancing its understanding and generalization of data uncertainty. In addition, applying a random training strategy to the high-frequency components of the sinogram wavelet enhances feature representation and improves the ability to capture details in different frequency bands, thereby improving performance and robustness. Two-stage iterative reconstruction method is adopted to ensure the global consistency of the reconstructed image while refining its details. Experimental results demonstrate that SWARM outperforms competing approaches in both quantitative and qualitative performance across various datasets.
Progressive Multi-Scale Self-Supervised Learning for Speech Recognition
Dec 07, 2022



Self-supervised learning (SSL) models have achieved considerable improvements in automatic speech recognition (ASR). In addition, ASR performance could be further improved if the model is dedicated to audio content information learning theoretically. To this end, we propose a progressive multi-scale self-supervised learning (PMS-SSL) method, which uses fine-grained target sets to compute SSL loss at top layer while uses coarse-grained target sets at intermediate layers. Furthermore, PMS-SSL introduces multi-scale structure into multi-head self-attention for better speech representation, which restricts the attention area into a large scope at higher layers while restricts the attention area into a small scope at lower layers. Experiments on Librispeech dataset indicate the effectiveness of our proposed method. Compared with HuBERT, PMS-SSL achieves 13.7% / 12.7% relative WER reduction on test other evaluation subsets respectively when fine-tuned on 10hours / 100hours subsets.
Topic Classification on Spoken Documents Using Deep Acoustic and Linguistic Features
Jun 16, 2021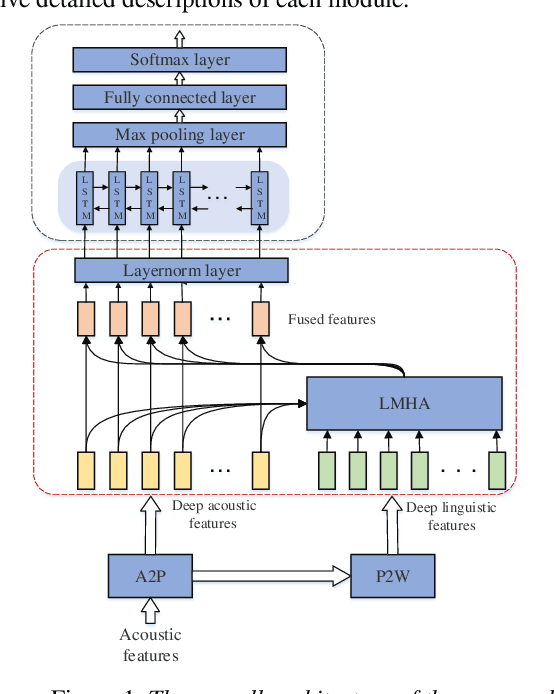

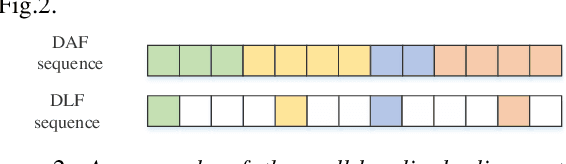

Topic classification systems on spoken documents usually consist of two modules: an automatic speech recognition (ASR) module to convert speech into text and a text topic classification (TTC) module to predict the topic class from the decoded text. In this paper, instead of using the ASR transcripts, the fusion of deep acoustic and linguistic features is used for topic classification on spoken documents. More specifically, a conventional CTC-based acoustic model (AM) using phonemes as output units is first trained, and the outputs of the layer before the linear phoneme classifier in the trained AM are used as the deep acoustic features of spoken documents. Furthermore, these deep acoustic features are fed to a phoneme-to-word (P2W) module to obtain deep linguistic features. Finally, a local multi-head attention module is proposed to fuse these two types of deep features for topic classification. Experiments conducted on a subset selected from Switchboard corpus show that our proposed framework outperforms the conventional ASR+TTC systems and achieves a 3.13% improvement in ACC.