 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Classification on Spoken Documents Using Deep Acoustic and Linguistic Features
Paper and Code
Jun 16, 2021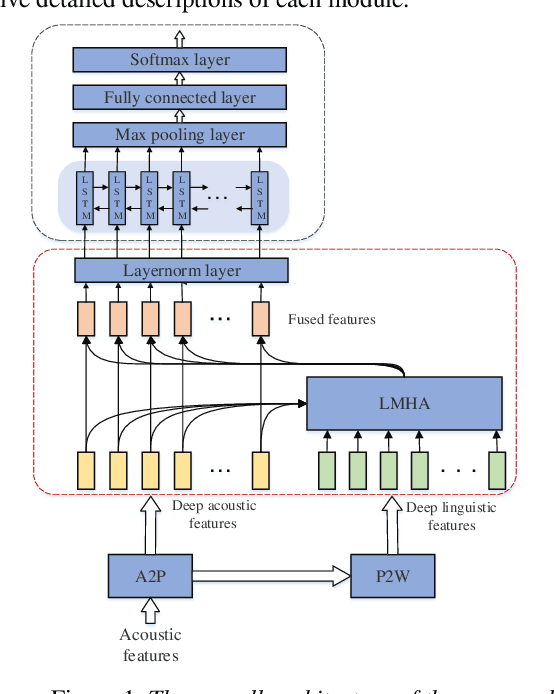

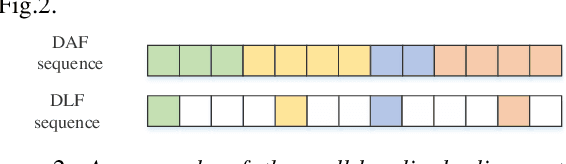

Topic classification systems on spoken documents usually consist of two modules: an automatic speech recognition (ASR) module to convert speech into text and a text topic classification (TTC) module to predict the topic class from the decoded text. In this paper, instead of using the ASR transcripts, the fusion of deep acoustic and linguistic features is used for topic classification on spoken documents. More specifically, a conventional CTC-based acoustic model (AM) using phonemes as output units is first trained, and the outputs of the layer before the linear phoneme classifier in the trained AM are used as the deep acoustic features of spoken documents. Furthermore, these deep acoustic features are fed to a phoneme-to-word (P2W) module to obtain deep linguistic features. Finally, a local multi-head attention module is proposed to fuse these two types of deep features for topic classification. Experiments conducted on a subset selected from Switchboard corpus show that our proposed framework outperforms the conventional ASR+TTC systems and achieves a 3.13% improvement in ACC.