 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Speech Recognition with Decoder-Only Large Language Models and Latency Optimization
Jan 30, 2026Recent advances have demonstrated the potential of decoderonly large language models (LLMs) for automatic speech recognition (ASR). However, enabling streaming recognition within this framework remains a challenge. In this work, we propose a novel streaming ASR approach that integrates a read/write policy network with monotonic chunkwise attention (MoChA) to dynamically segment speech embeddings. These segments are interleaved with label sequences during training, enabling seamless integration with the LLM. During inference, the audio stream is buffered until the MoChA module triggers a read signal, at which point the buffered segment together with the previous token is fed into the LLM for the next token prediction. We also introduce a minimal-latency training objective to guide the policy network toward accurate segmentation boundaries. Furthermore, we adopt a joint training strategy in which a non-streaming LLM-ASR model and our streaming model share parameters. Experiments on the AISHELL-1 and AISHELL-2 Mandarin benchmarks demonstrate that our method consistently outperforms recent streaming ASR baselines, achieving character error rates of 5.1% and 5.5%, respectively. The latency optimization results in a 62.5% reduction in average token generation delay with negligible impact on recognition accuracy
A Comparative Study of Pre-trained CNNs and GRU-Based Attention for Image Caption Generation
Oct 11, 2023



Image captioning is a challenging task involving generating a textual description for an image using computer vision and natural language processing techniques. This paper proposes a deep neural framework for image caption generation using a GRU-based attention mechanism. Our approach employs multiple pre-trained convolutional neural networks as the encoder to extract features from the image and a GRU-based language model as the decoder to generate descriptive sentences. To improve performance, we integrate the Bahdanau attention model with the GRU decoder to enable learning to focus on specific image parts. We evaluate our approach using the MSCOCO and Flickr30k datasets and show that it achieves competitive scores compared to state-of-the-art methods. Our proposed framework can bridge the gap between computer vision and natural language and can be extended to specific domains.
Progressive Multi-Scale Self-Supervised Learning for Speech Recognition
Dec 07, 2022



Self-supervised learning (SSL) models have achieved considerable improvements in automatic speech recognition (ASR). In addition, ASR performance could be further improved if the model is dedicated to audio content information learning theoretically. To this end, we propose a progressive multi-scale self-supervised learning (PMS-SSL) method, which uses fine-grained target sets to compute SSL loss at top layer while uses coarse-grained target sets at intermediate layers. Furthermore, PMS-SSL introduces multi-scale structure into multi-head self-attention for better speech representation, which restricts the attention area into a large scope at higher layers while restricts the attention area into a small scope at lower layers. Experiments on Librispeech dataset indicate the effectiveness of our proposed method. Compared with HuBERT, PMS-SSL achieves 13.7% / 12.7% relative WER reduction on test other evaluation subsets respectively when fine-tuned on 10hours / 100hours subsets.
A Deep Neural Framework for Image Caption Generation Using GRU-Based Attention Mechanism
Mar 03, 2022

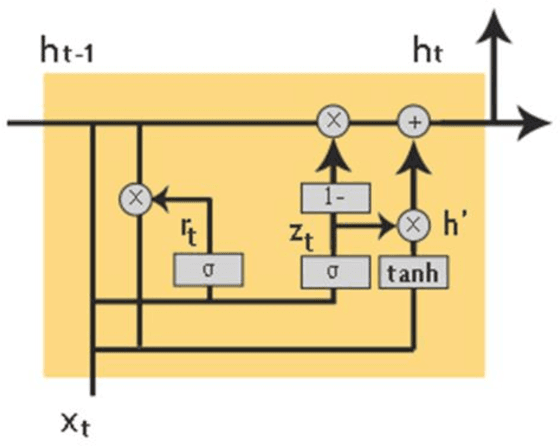
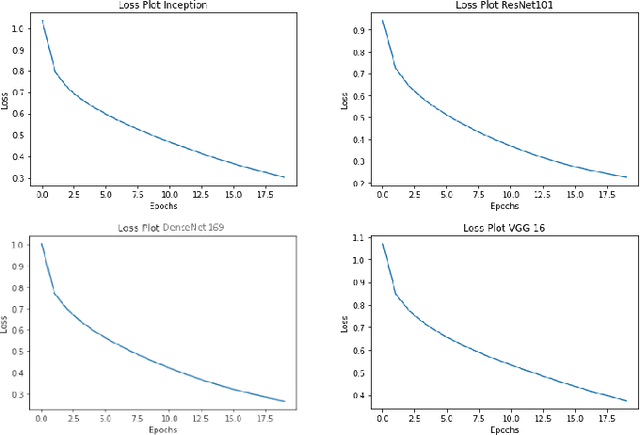
Image captioning is a fast-growing research field of computer vision and natural language processing that involves creating text explanations for images. This study aims to develop a system that uses a pre-trained convolutional neural network (CNN) to extract features from an image, integrates the features with an attention mechanism, and creates captions using a recurrent neural network (RNN). To encode an image into a feature vector as graphical attributes, we employed multiple pre-trained convolutional neural networks. Following that, a language model known as GRU is chosen as the decoder to construct the descriptive sentence. In order to increase performance, we merge the Bahdanau attention model with GRU to allow learning to be focused on a specific portion of the image. On the MSCOCO dataset, the experimental results achieve competitive performance against state-of-the-art approaches.
* 16 PAGES, 8 figures, 1 TABLE