 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Deep Learning for Small-Scale Classifications: Experiments on Real-World Image Datasets from Bangladesh
Jan 17, 2026Convolutional neural networks (CNNs) have achieved state-of-the-art performance in image recognition tasks but often involve complex architectures that may overfit on small datasets. In this study, we evaluate a compact CNN across five publicly available, real-world image datasets from Bangladesh, including urban encroachment, vehicle detection, road damage, and agricultural crops. The network demonstrates high classification accuracy, efficient convergence, and low computational overhead. Quantitative metrics and saliency analyses indicate that the model effectively captures discriminative features and generalizes robustly across diverse scenarios, highlighting the suitability of streamlined CNN architectures for small-class image classification tasks.
An Advanced Deep Learning Based Three-Stream Hybrid Model for Dynamic Hand Gesture Recognition
Aug 15, 2024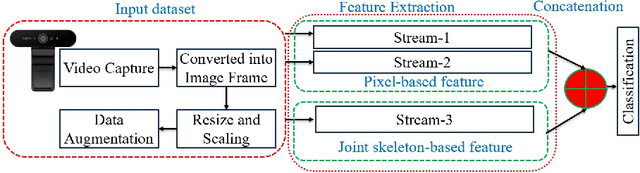



In the modern context, hand gesture recognition has emerged as a focal point. This is due to its wide range of applications, which include comprehending sign language, factories, hands-free devices, and guiding robots. Many researchers have attempted to develop more effective techniques for recognizing these hand gestures. However, there are challenges like dataset limitations, variations in hand forms, external environments, and inconsistent lighting conditions. To address these challenges, we proposed a novel three-stream hybrid model that combines RGB pixel and skeleton-based features to recognize hand gestures. In the procedure, we preprocessed the dataset, including augmentation, to make rotation, translation, and scaling independent systems. We employed a three-stream hybrid model to extract the multi-feature fusion using the power of the deep learning module. In the first stream, we extracted the initial feature using the pre-trained Imagenet module and then enhanced this feature by using a multi-layer of the GRU and LSTM modules. In the second stream, we extracted the initial feature with the pre-trained ReseNet module and enhanced it with the various combinations of the GRU and LSTM modules. In the third stream, we extracted the hand pose key points using the media pipe and then enhanced them using the stacked LSTM to produce the hierarchical feature. After that, we concatenated the three features to produce the final. Finally, we employed a classification module to produce the probabilistic map to generate predicted output. We mainly produced a powerful feature vector by taking advantage of the pixel-based deep learning feature and pos-estimation-based stacked deep learning feature, including a pre-trained model with a scratched deep learning model for unequalled gesture detection capabilities.
A Deep Neural Framework for Image Caption Generation Using GRU-Based Attention Mechanism
Mar 03, 2022

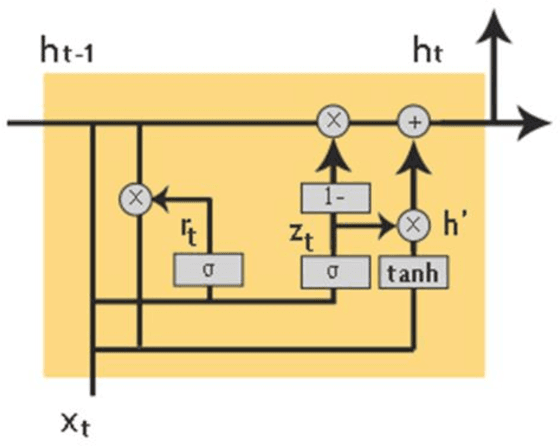
Image captioning is a fast-growing research field of computer vision and natural language processing that involves creating text explanations for images. This study aims to develop a system that uses a pre-trained convolutional neural network (CNN) to extract features from an image, integrates the features with an attention mechanism, and creates captions using a recurrent neural network (RNN). To encode an image into a feature vector as graphical attributes, we employed multiple pre-trained convolutional neural networks. Following that, a language model known as GRU is chosen as the decoder to construct the descriptive sentence. In order to increase performance, we merge the Bahdanau attention model with GRU to allow learning to be focused on a specific portion of the image. On the MSCOCO dataset, the experimental results achieve competitive performance against state-of-the-art approaches.
* 16 PAGES, 8 figures, 1 TABLE
Supervised Learning of Digital image restoration based on Quantization Nearest Neighbor algorithm
Feb 21, 2010
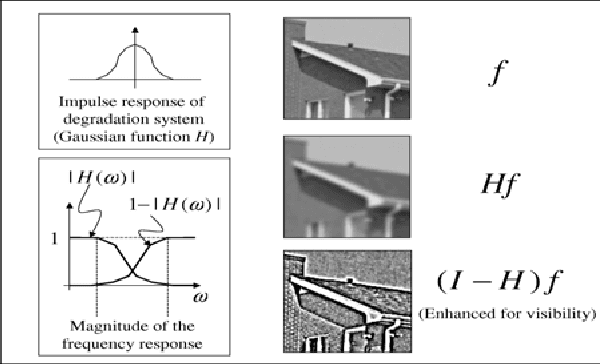


In this paper, an algorithm is proposed for Image Restoration. Such algorithm is different from the traditional approaches in this area, by utilizing priors that are learned from similar images. Original images and their degraded versions by the known degradation operators are utilized for designing the Quantization. The code vectors are designed using the blurred images. For each such vector, the high frequency information obtained from the original images is also available. During restoration, the high frequency information of a given degraded image is estimated from its low frequency information based on the artificial noise. For the restoration problem, a number of techniques are designed corresponding to various versions of the blurring function. Given a noisy and blurred image, one of the techniques is chosen based on a similarity measure, therefore providing the identification of the blur. To make the restoration process computationally efficient, the Quantization Nearest Neighborhood approaches are utilized.