 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Neural Framework for Image Caption Generation Using GRU-Based Attention Mechanism
Paper and Code
Mar 03, 2022

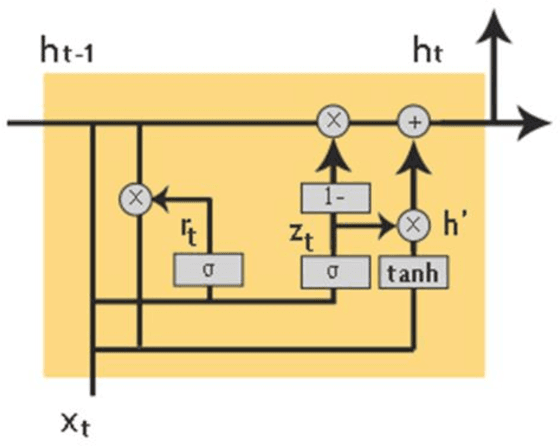
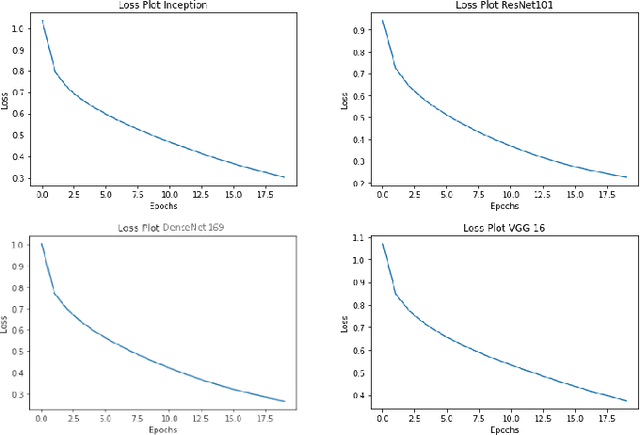
Image captioning is a fast-growing research field of computer vision and natural language processing that involves creating text explanations for images. This study aims to develop a system that uses a pre-trained convolutional neural network (CNN) to extract features from an image, integrates the features with an attention mechanism, and creates captions using a recurrent neural network (RNN). To encode an image into a feature vector as graphical attributes, we employed multiple pre-trained convolutional neural networks. Following that, a language model known as GRU is chosen as the decoder to construct the descriptive sentence. In order to increase performance, we merge the Bahdanau attention model with GRU to allow learning to be focused on a specific portion of the image. On the MSCOCO dataset, the experimental results achieve competitive performance against state-of-the-art approaches.