 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D MRI-Based Alzheimer's Disease Classification Using Multi-Modal 3D CNN with Leakage-Aware Subject-Level Evaluation
Mar 18, 2026Deep learning has become an important tool for Alzheimer's disease (AD) classification from structural MRI. Many existing studies analyze individual 2D slices extracted from MRI volumes, while clinical neuroimaging practice typically relies on the full three dimensional structure of the brain. From this perspective, volumetric analysis may better capture spatial relationships among brain regions that are relevant to disease progression. Motivated by this idea, this work proposes a multimodal 3D convolutional neural network for AD classification using raw OASIS 1 MRI volumes. The model combines structural T1 information with gray matter, white matter, and cerebrospinal fluid probability maps obtained through FSL FAST segmentation in order to capture complementary neuroanatomical information. The proposed approach is evaluated on the clinically labelled OASIS 1 cohort using 5 fold subject level cross validation, achieving a mean accuracy of 72.34% plus or minus 4.66% and a ROC AUC of 0.7781 plus or minus 0.0365. GradCAM visualizations further indicate that the model focuses on anatomically meaningful regions, including the medial temporal lobe and ventricular areas that are known to be associated with Alzheimer's related structural changes. To better understand how data representation and evaluation strategies may influence reported performance, additional diagnostic experiments were conducted on a slice based version of the dataset under both slice level and subject level protocols. These observations help provide context for the volumetric results. Overall, the proposed multimodal 3D framework establishes a reproducible subject level benchmark and highlights the potential benefits of volumetric MRI analysis for Alzheimer's disease classification.
Motor Imagery Classification Using Feature Fusion of Spatially Weighted Electroencephalography
Nov 14, 2025
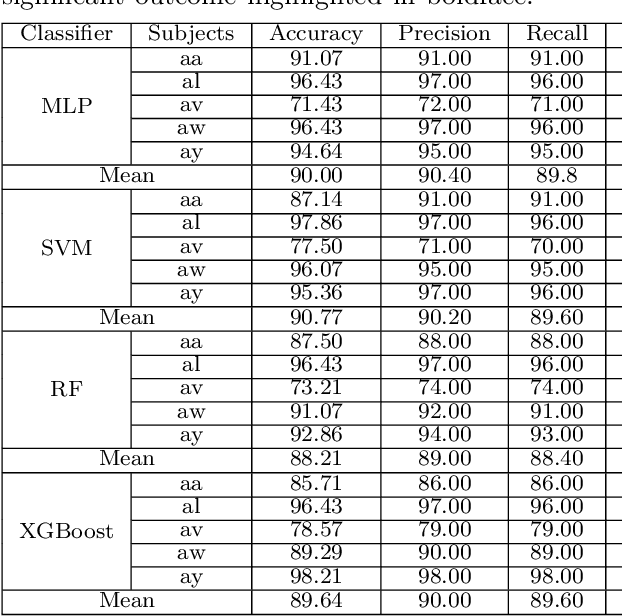
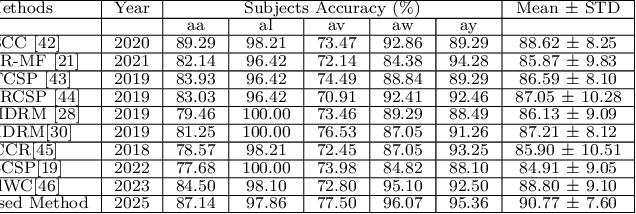
A Brain Computer Interface (BCI) connects the human brain to the outside world, providing a direct communication channel. Electroencephalography (EEG) signals are commonly used in BCIs to reflect cognitive patterns related to motor function activities. However, due to the multichannel nature of EEG signals, explicit information processing is crucial to lessen computational complexity in BCI systems. This study proposes an innovative method based on brain region-specific channel selection and multi-domain feature fusion to improve classification accuracy. The novelty of the proposed approach lies in region-based channel selection, where EEG channels are grouped according to their functional relevance to distinct brain regions. By selecting channels based on specific regions involved in motor imagery (MI) tasks, this technique eliminates irrelevant channels, reducing data dimensionality and improving computational efficiency. This also ensures that the extracted features are more reflective of the brain actual activity related to motor tasks. Three distinct feature extraction methods Common Spatial Pattern (CSP), Fuzzy C-means clustering, and Tangent Space Mapping (TSM), are applied to each group of channels based on their brain region. Each method targets different characteristics of the EEG signal: CSP focuses on spatial patterns, Fuzzy C means identifies clusters within the data, and TSM captures non-linear patterns in the signal. The combined feature vector is used to classify motor imagery tasks (left hand, right hand, and right foot) using Support Vector Machine (SVM). The proposed method was validated on publicly available benchmark EEG datasets (IVA and I) from the BCI competition III and IV. The results show that the approach outperforms existing methods, achieving classification accuracies of 90.77% and 84.50% for datasets IVA and I, respectively.
Hybrid CNN-BYOL Approach for Fault Detection in Induction Motors Using Thermal Images
Oct 09, 2025Induction motors (IMs) are indispensable in industrial and daily life, but they are susceptible to various faults that can lead to overheating, wasted energy consumption, and service failure. Early detection of faults is essential to protect the motor and prolong its lifespan. This paper presents a hybrid method that integrates BYOL with CNNs for classifying thermal images of induction motors for fault detection. The thermal dataset used in this work includes different operating states of the motor, such as normal operation, overload, and faults. We employed multiple deep learning (DL) models for the BYOL technique, ranging from popular architectures such as ResNet-50, DenseNet-121, DenseNet-169, EfficientNetB0, VGG16, and MobileNetV2. Additionally, we introduced a new high-performance yet lightweight CNN model named BYOL-IMNet, which comprises four custom-designed blocks tailored for fault classification in thermal images. Our experimental results demonstrate that the proposed BYOL-IMNet achieves 99.89\% test accuracy and an inference time of 5.7 ms per image, outperforming state-of-the-art models. This study highlights the promising performance of the CNN-BYOL hybrid method in enhancing accuracy for detecting faults in induction motors, offering a robust methodology for online monitoring in industrial settings.
Classification of ADHD and Healthy Children Using EEG Based Multi-Band Spatial Features Enhancement
Apr 07, 2025Attention Deficit Hyperactivity Disorder (ADHD) is a common neurodevelopmental disorder in children, characterized by difficulties in attention, hyperactivity, and impulsivity. Early and accurate diagnosis of ADHD is critical for effective intervention and management. Electroencephalogram (EEG) signals have emerged as a non-invasive and efficient tool for ADHD detection due to their high temporal resolution and ability to capture neural dynamics. In this study, we propose a method for classifying ADHD and healthy children using EEG data from the benchmark dataset. There were 61 children with ADHD and 60 healthy children, both boys and girls, aged 7 to 12. The EEG signals, recorded from 19 channels, were processed to extract Power Spectral Density (PSD) and Spectral Entropy (SE) features across five frequency bands, resulting in a comprehensive 190-dimensional feature set. To evaluate the classification performance, a Support Vector Machine (SVM) with the RBF kernel demonstrated the best performance with a mean cross-validation accuracy of 99.2\% and a standard deviation of 0.0079, indicating high robustness and precision. These results highlight the potential of spatial features in conjunction with machine learning for accurately classifying ADHD using EEG data. This work contributes to developing non-invasive, data-driven tools for early diagnosis and assessment of ADHD in children.
Electromyography-Based Gesture Recognition: Hierarchical Feature Extraction for Enhanced Spatial-Temporal Dynamics
Apr 04, 2025Hand gesture recognition using multichannel surface electromyography (sEMG) is challenging due to unstable predictions and inefficient time-varying feature enhancement. To overcome the lack of signal based time-varying feature problems, we propose a lightweight squeeze-excitation deep learning-based multi stream spatial temporal dynamics time-varying feature extraction approach to build an effective sEMG-based hand gesture recognition system. Each branch of the proposed model was designed to extract hierarchical features, capturing both global and detailed spatial-temporal relationships to ensure feature effectiveness. The first branch, utilizing a Bidirectional-TCN (Bi-TCN), focuses on capturing long-term temporal dependencies by modelling past and future temporal contexts, providing a holistic view of gesture dynamics. The second branch, incorporating a 1D Convolutional layer, separable CNN, and Squeeze-and-Excitation (SE) block, efficiently extracts spatial-temporal features while emphasizing critical feature channels, enhancing feature relevance. The third branch, combining a Temporal Convolutional Network (TCN) and Bidirectional LSTM (BiLSTM), captures bidirectional temporal relationships and time-varying patterns. Outputs from all branches are fused using concatenation to capture subtle variations in the data and then refined with a channel attention module, selectively focusing on the most informative features while improving computational efficiency. The proposed model was tested on the Ninapro DB2, DB4, and DB5 datasets, achieving accuracy rates of 96.41%, 92.40%, and 93.34%, respectively. These results demonstrate the capability of the system to handle complex sEMG dynamics, offering advancements in prosthetic limb control and human-machine interface technologies with significant implications for assistive technologies.
Stack Transformer Based Spatial-Temporal Attention Model for Dynamic Multi-Culture Sign Language Recognition
Mar 21, 2025Hand gesture-based Sign Language Recognition (SLR) serves as a crucial communication bridge between deaf and non-deaf individuals. Existing SLR systems perform well for their cultural SL but may struggle with multi-cultural sign languages (McSL). To address these challenges, this paper proposes a Stack Spatial-Temporal Transformer Network that leverages multi-head attention mechanisms to capture both spatial and temporal dependencies with hierarchical features using the Stack Transfer concept. In the proceed, firstly, we applied a fully connected layer to make a embedding vector which has high expressive power from the original dataset, then fed them a stack newly proposed transformer to achieve hierarchical features with short-range and long-range dependency. The network architecture is composed of several stages that process spatial and temporal relationships sequentially, ensuring effective feature extraction. After making the fully connected layer, the embedding vector is processed by the Spatial Multi-Head Attention Transformer, which captures spatial dependencies between joints. In the next stage, the Temporal Multi-Head Attention Transformer captures long-range temporal dependencies, and again, the features are concatenated with the output using another skip connection. The processed features are then passed to the Feed-Forward Network (FFN), which refines the feature representations further. After the FFN, additional skip connections are applied to combine the output with earlier layers, followed by a final normalization layer to produce the final output feature tensor. This process is repeated for 10 transformer blocks. The extensive experiment shows that the JSL, KSL and ASL datasets achieved good performance accuracy. Our approach demonstrates improved performance in McSL, and it will be consider as a novel work in this domain.
IoT-Based Real-Time Medical-Related Human Activity Recognition Using Skeletons and Multi-Stage Deep Learning for Healthcare
Jan 13, 2025The Internet of Things (IoT) and mobile technology have significantly transformed healthcare by enabling real-time monitoring and diagnosis of patients. Recognizing medical-related human activities (MRHA) is pivotal for healthcare systems, particularly for identifying actions that are critical to patient well-being. However, challenges such as high computational demands, low accuracy, and limited adaptability persist in Human Motion Recognition (HMR). While some studies have integrated HMR with IoT for real-time healthcare applications, limited research has focused on recognizing MRHA as essential for effective patient monitoring. This study proposes a novel HMR method for MRHA detection, leveraging multi-stage deep learning techniques integrated with IoT. The approach employs EfficientNet to extract optimized spatial features from skeleton frame sequences using seven Mobile Inverted Bottleneck Convolutions (MBConv) blocks, followed by ConvLSTM to capture spatio-temporal patterns. A classification module with global average pooling, a fully connected layer, and a dropout layer generates the final predictions. The model is evaluated on the NTU RGB+D 120 and HMDB51 datasets, focusing on MRHA, such as sneezing, falling, walking, sitting, etc. It achieves 94.85% accuracy for cross-subject evaluations and 96.45% for cross-view evaluations on NTU RGB+D 120, along with 89.00% accuracy on HMDB51. Additionally, the system integrates IoT capabilities using a Raspberry Pi and GSM module, delivering real-time alerts via Twilios SMS service to caregivers and patients. This scalable and efficient solution bridges the gap between HMR and IoT, advancing patient monitoring, improving healthcare outcomes, and reducing costs.
Machine Learning-Based Differential Diagnosis of Parkinson's Disease Using Kinematic Feature Extraction and Selection
Jan 02, 2025Parkinson's disease (PD), the second most common neurodegenerative disorder, is characterized by dopaminergic neuron loss and the accumulation of abnormal synuclein. PD presents both motor and non-motor symptoms that progressively impair daily functioning. The severity of these symptoms is typically assessed using the MDS-UPDRS rating scale, which is subjective and dependent on the physician's experience. Additionally, PD shares symptoms with other neurodegenerative diseases, such as progressive supranuclear palsy (PSP) and multiple system atrophy (MSA), complicating accurate diagnosis. To address these diagnostic challenges, we propose a machine learning-based system for differential diagnosis of PD, PSP, MSA, and healthy controls (HC). This system utilizes a kinematic feature-based hierarchical feature extraction and selection approach. Initially, 18 kinematic features are extracted, including two newly proposed features: Thumb-to-index vector velocity and acceleration, which provide insights into motor control patterns. In addition, 41 statistical features were extracted here from each kinematic feature, including some new approaches such as Average Absolute Change, Rhythm, Amplitude, Frequency, Standard Deviation of Frequency, and Slope. Feature selection is performed using One-way ANOVA to rank features, followed by Sequential Forward Floating Selection (SFFS) to identify the most relevant ones, aiming to reduce the computational complexity. The final feature set is used for classification, achieving a classification accuracy of 66.67% for each dataset and 88.89% for each patient, with particularly high performance for the MSA and HC groups using the SVM algorithm. This system shows potential as a rapid and accurate diagnostic tool in clinical practice, though further data collection and refinement are needed to enhance its reliability.
Parkinson Disease Detection Based on In-air Dynamics Feature Extraction and Selection Using Machine Learning
Dec 19, 2024Parkinson's disease (PD) is a progressive neurological disorder that impairs movement control, leading to symptoms such as tremors, stiffness, and bradykinesia. Many researchers analyzing handwriting data for PD detection typically rely on computing statistical features over the entirety of the handwriting task. While this method can capture broad patterns, it has several limitations, including a lack of focus on dynamic change, oversimplified feature representation, lack of directional information, and missing micro-movements or subtle variations. Consequently, these systems face challenges in achieving good performance accuracy, robustness, and sensitivity. To overcome this problem, we proposed an optimized PD detection methodology that incorporates newly developed dynamic kinematic features and machine learning (ML)-based techniques to capture movement dynamics during handwriting tasks. In the procedure, we first extracted 65 newly developed kinematic features from the first and last 10% phases of the handwriting task rather than using the entire task. Alongside this, we also reused 23 existing kinematic features, resulting in a comprehensive new feature set. Next, we enhanced the kinematic features by applying statistical formulas to compute hierarchical features from the handwriting data. This approach allows us to capture subtle movement variations that distinguish PD patients from healthy controls. To further optimize the feature set, we applied the Sequential Forward Floating Selection method to select the most relevant features, reducing dimensionality and computational complexity. Finally, we employed an ML-based approach based on ensemble voting across top-performing tasks, achieving an impressive 96.99\% accuracy on task-wise classification and 99.98% accuracy on task ensembles, surpassing the existing state-of-the-art model by 2% for the PaHaW dataset.
Computer-Aided Osteoporosis Diagnosis Using Transfer Learning with Enhanced Features from Stacked Deep Learning Modules
Dec 12, 2024



Knee osteoporosis weakens the bone tissue in the knee joint, increasing fracture risk. Early detection through X-ray images enables timely intervention and improved patient outcomes. While some researchers have focused on diagnosing knee osteoporosis through manual radiology evaluation and traditional machine learning using hand-crafted features, these methods often struggle with performance and efficiency due to reliance on manual feature extraction and subjective interpretation. In this study, we propose a computer-aided diagnosis (CAD) system for knee osteoporosis, combining transfer learning with stacked feature enhancement deep learning blocks. Initially, knee X-ray images are preprocessed, and features are extracted using a pre-trained Convolutional Neural Network (CNN). These features are then enhanced through five sequential Conv-RELU-MaxPooling blocks. The Conv2D layers detect low-level features, while the ReLU activations introduce non-linearity, allowing the network to learn complex patterns. MaxPooling layers down-sample the features, retaining the most important spatial information. This sequential processing enables the model to capture complex, high-level features related to bone structure, joint deformation, and osteoporotic markers. The enhanced features are passed through a classification module to differentiate between healthy and osteoporotic knee conditions. Extensive experiments on three individual datasets and a combined dataset demonstrate that our model achieves 97.32%, 98.24%, 97.27%, and 98.00% accuracy for OKX Kaggle Binary, KXO-Mendeley Multi-Class, OKX Kaggle Multi-Class, and the combined dataset, respectively, showing an improvement of around 2% over existing methods.