 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStack Transformer Based Spatial-Temporal Attention Model for Dynamic Multi-Culture Sign Language Recognition
Mar 21, 2025Hand gesture-based Sign Language Recognition (SLR) serves as a crucial communication bridge between deaf and non-deaf individuals. Existing SLR systems perform well for their cultural SL but may struggle with multi-cultural sign languages (McSL). To address these challenges, this paper proposes a Stack Spatial-Temporal Transformer Network that leverages multi-head attention mechanisms to capture both spatial and temporal dependencies with hierarchical features using the Stack Transfer concept. In the proceed, firstly, we applied a fully connected layer to make a embedding vector which has high expressive power from the original dataset, then fed them a stack newly proposed transformer to achieve hierarchical features with short-range and long-range dependency. The network architecture is composed of several stages that process spatial and temporal relationships sequentially, ensuring effective feature extraction. After making the fully connected layer, the embedding vector is processed by the Spatial Multi-Head Attention Transformer, which captures spatial dependencies between joints. In the next stage, the Temporal Multi-Head Attention Transformer captures long-range temporal dependencies, and again, the features are concatenated with the output using another skip connection. The processed features are then passed to the Feed-Forward Network (FFN), which refines the feature representations further. After the FFN, additional skip connections are applied to combine the output with earlier layers, followed by a final normalization layer to produce the final output feature tensor. This process is repeated for 10 transformer blocks. The extensive experiment shows that the JSL, KSL and ASL datasets achieved good performance accuracy. Our approach demonstrates improved performance in McSL, and it will be consider as a novel work in this domain.
Computer-Aided Fall Recognition Using a Three-Stream Spatial-Temporal GCN Model with Adaptive Feature Aggregation
Aug 22, 2024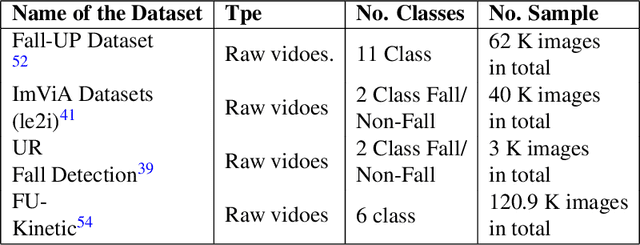
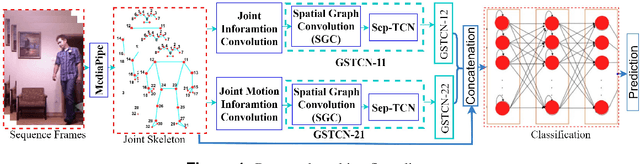
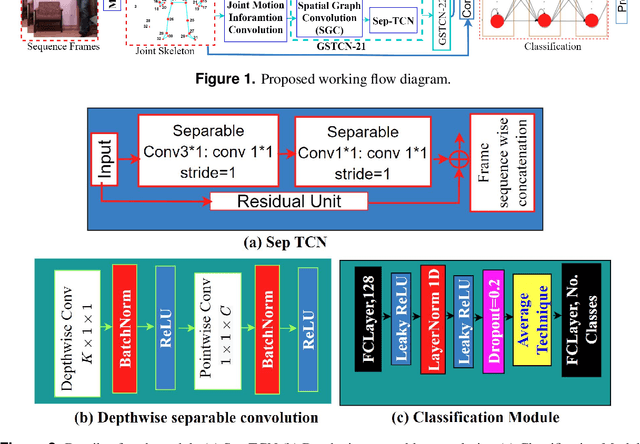
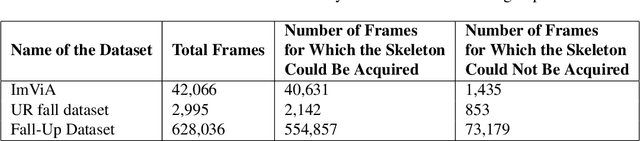
The prevention of falls is paramount in modern healthcare, particularly for the elderly, as falls can lead to severe injuries or even fatalities. Additionally, the growing incidence of falls among the elderly, coupled with the urgent need to prevent suicide attempts resulting from medication overdose, underscores the critical importance of accurate and efficient fall detection methods. In this scenario, a computer-aided fall detection system is inevitable to save elderly people's lives worldwide. Many researchers have been working to develop fall detection systems. However, the existing fall detection systems often struggle with issues such as unsatisfactory performance accuracy, limited robustness, high computational complexity, and sensitivity to environmental factors due to a lack of effective features. In response to these challenges, this paper proposes a novel three-stream spatial-temporal feature-based fall detection system. Our system incorporates joint skeleton-based spatial and temporal Graph Convolutional Network (GCN) features, joint motion-based spatial and temporal GCN features, and residual connections-based features. Each stream employs adaptive graph-based feature aggregation and consecutive separable convolutional neural networks (Sep-TCN), significantly reducing computational complexity and model parameters compared to prior systems. Experimental results across multiple datasets demonstrate the superior effectiveness and efficiency of our proposed system, with accuracies of 99.51\%, 99.15\%, 99.79\% and 99.85 \% achieved on the ImViA, UR-Fall, Fall-UP and FU-Kinect datasets, respectively. The remarkable performance of our system highlights its superiority, efficiency, and generalizability in real-world fall detection scenarios, offering significant advancements in healthcare and societal well-being.