 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-class heart disease Detection, Classification, and Prediction using Machine Learning Models
Dec 06, 2024



Heart disease is a leading cause of premature death worldwide, particularly among middle-aged and older adults, with men experiencing a higher prevalence. According to the World Health Organization (WHO), non-communicable diseases, including heart disease, account for 25\% (17.9 million) of global deaths, with over 43,204 annual fatalities in Bangladesh. However, the development of heart disease detection (HDD) systems tailored to the Bangladeshi population remains underexplored due to the lack of benchmark datasets and reliance on manual or limited-data approaches. This study addresses these challenges by introducing new, ethically sourced HDD dataset, BIG-Dataset and CD dataset which incorporates comprehensive data on symptoms, examination techniques, and risk factors. Using advanced machine learning techniques, including Logistic Regression and Random Forest, we achieved a remarkable testing accuracy of up to 96.6\% with Random Forest. The proposed AI-driven system integrates these models and datasets to provide real-time, accurate diagnostics and personalized healthcare recommendations. By leveraging structured datasets and state-of-the-art machine learning algorithms, this research offers an innovative solution for scalable and effective heart disease detection, with the potential to reduce mortality rates and improve clinical outcomes.
Comparison of Distances for Supervised Segmentation of White Matter Tractography
Aug 04, 2017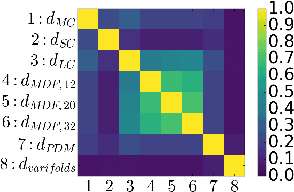

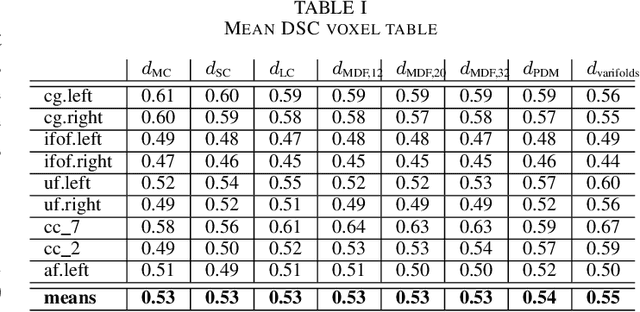
Tractograms are mathematical representations of the main paths of axons within the white matter of the brain, from diffusion MRI data. Such representations are in the form of polylines, called streamlines, and one streamline approximates the common path of tens of thousands of axons. The analysis of tractograms is a task of interest in multiple fields, like neurosurgery and neurology. A basic building block of many pipelines of analysis is the definition of a distance function between streamlines. Multiple distance functions have been proposed in the literature, and different authors use different distances, usually without a specific reason other than invoking the "common practice". To this end, in this work we want to test such common practices, in order to obtain factual reasons for choosing one distance over another. For these reasons, in this work we compare many streamline distance functions available in the literature. We focus on the common task of automatic bundle segmentation and we adopt the recent approach of supervised segmentation from expert-based examples. Using the HCP dataset, we compare several distances obtaining guidelines on the choice of which distance function one should use for supervised bundle segmentation.