 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe USTC-NERCSLIP Systems for the CHiME-9 MCoRec Challenge
Mar 02, 2026This report details our submission to the CHiME-9 MCoRec Challenge on recognizing and clustering multiple concurrent natural conversations within indoor social settings. Unlike conventional meetings centered on a single shared topic, this scenario contains multiple parallel dialogues--up to eight speakers across up to four simultaneous conversations--with a speech overlap rate exceeding 90%. To tackle this, we propose a multimodal cascaded system that leverages per-speaker visual streams extracted from synchronized 360 degree video together with single-channel audio. Our system improves three components of the pipeline by leveraging enhanced audio-visual pretrained models: Active Speaker Detection (ASD), Audio-Visual Target Speech Extraction (AVTSE), and Audio-Visual Speech Recognition (AVSR). The AVSR module further incorporates Whisper and LLM techniques to boost transcription accuracy. Our best single cascaded system achieves a Speaker Word Error Rate (WER) of 32.44% on the development set. By further applying ROVER to fuse outputs from diverse front-end and back-end variants, we reduce Speaker WER to 31.40%. Notably, our LLM-based zero-shot conversational clustering achieves a speaker clustering F1 score of 1.0, yielding a final Joint ASR-Clustering Error Rate (JACER) of 15.70%.
Streaming Speech Recognition with Decoder-Only Large Language Models and Latency Optimization
Jan 30, 2026Recent advances have demonstrated the potential of decoderonly large language models (LLMs) for automatic speech recognition (ASR). However, enabling streaming recognition within this framework remains a challenge. In this work, we propose a novel streaming ASR approach that integrates a read/write policy network with monotonic chunkwise attention (MoChA) to dynamically segment speech embeddings. These segments are interleaved with label sequences during training, enabling seamless integration with the LLM. During inference, the audio stream is buffered until the MoChA module triggers a read signal, at which point the buffered segment together with the previous token is fed into the LLM for the next token prediction. We also introduce a minimal-latency training objective to guide the policy network toward accurate segmentation boundaries. Furthermore, we adopt a joint training strategy in which a non-streaming LLM-ASR model and our streaming model share parameters. Experiments on the AISHELL-1 and AISHELL-2 Mandarin benchmarks demonstrate that our method consistently outperforms recent streaming ASR baselines, achieving character error rates of 5.1% and 5.5%, respectively. The latency optimization results in a 62.5% reduction in average token generation delay with negligible impact on recognition accuracy
Adapting Speech Foundation Models with Large Language Models for Unified Speech Recognition
Oct 27, 2025Unified speech recognition aims to perform auditory, visual, and audiovisual speech recognition within a single model framework. While speech foundation models (SFMs) have demonstrated remarkable performance in auditory tasks, their adaptation to multimodal scenarios remains underexplored. This paper presents UASR-LLM, a novel framework that adapts frozen SFMs to unified VSR, ASR, and AVSR tasks by leveraging large language models (LLMs) as text decoders. Our approach introduces visual representations into multiple SFM layers through visual injection modules, enabling multimodal input processing and unified hidden representations. The augmented SFMs connect with decoder-only LLMs via a feed-forward adaptor, where concatenated representations and instruction prompts guide speech transcription. We implement a twostage training strategy: visual injection pretraining followed by speech recognition finetuning. SFM parameters remain frozen throughout training, with only visual injection modules optimized initially, and LLMs finetuned using LoRA parameters subsequently. Experimental results demonstrate superior performance over state-of-the-art baselines across VSR, ASR, and AVSR tasks under both clean and noisy conditions. Ablation studies confirm generalization across various SFMs and LLMs, validating the proposed training strategy.
Audio-Visual Representation Learning via Knowledge Distillation from Speech Foundation Models
Feb 09, 2025



Audio-visual representation learning is crucial for advancing multimodal speech processing tasks, such as lipreading and audio-visual speech recognition. Recently, speech foundation models (SFMs) have shown remarkable generalization capabilities across various speech-related tasks. Building on this progress, we propose an audio-visual representation learning model that leverages cross-modal knowledge distillation from SFMs. In our method, SFMs serve as teachers, from which multi-layer hidden representations are extracted using clean audio inputs. We also introduce a multi-teacher ensemble method to distill the student, which receives audio-visual data as inputs. A novel representational knowledge distillation loss is employed to train the student during pretraining, which is also applied during finetuning to further enhance the performance on downstream tasks. Our experiments utilized both a self-supervised SFM, WavLM, and a supervised SFM, iFLYTEK-speech. The results demonstrated that our proposed method achieved superior or at least comparable performance to previous state-of-the-art baselines across automatic speech recognition, visual speech recognition, and audio-visual speech recognition tasks. Additionally, comprehensive ablation studies and the visualization of learned representations were conducted to evaluate the effectiveness of our proposed method.
Deep CLAS: Deep Contextual Listen, Attend and Spell
Sep 26, 2024



Contextual-LAS (CLAS) has been shown effective in improving Automatic Speech Recognition (ASR) of rare words. It relies on phrase-level contextual modeling and attention-based relevance scoring without explicit contextual constraint which lead to insufficient use of contextual information. In this work, we propose deep CLAS to use contextual information better. We introduce bias loss forcing model to focus on contextual information. The query of bias attention is also enriched to improve the accuracy of the bias attention score. To get fine-grained contextual information, we replace phrase-level encoding with character-level encoding and encode contextual information with conformer rather than LSTM. Moreover, we directly use the bias attention score to correct the output probability distribution of the model. Experiments using the public AISHELL-1 and AISHELL-NER. On AISHELL-1, compared to CLAS baselines, deep CLAS obtains a 65.78% relative recall and a 53.49% relative F1-score increase in the named entity recognition scene.
The USTC-NERCSLIP Systems for the CHiME-8 NOTSOFAR-1 Challenge
Sep 03, 2024
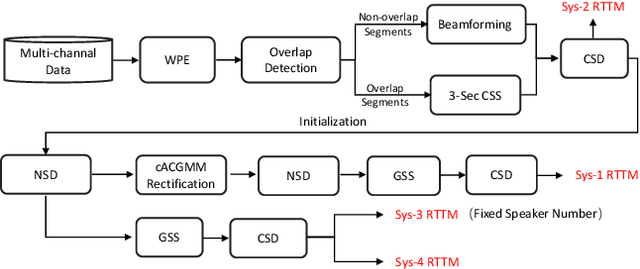
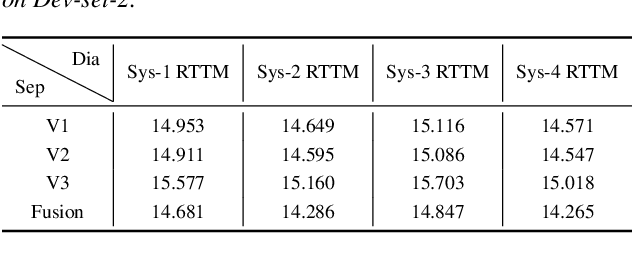
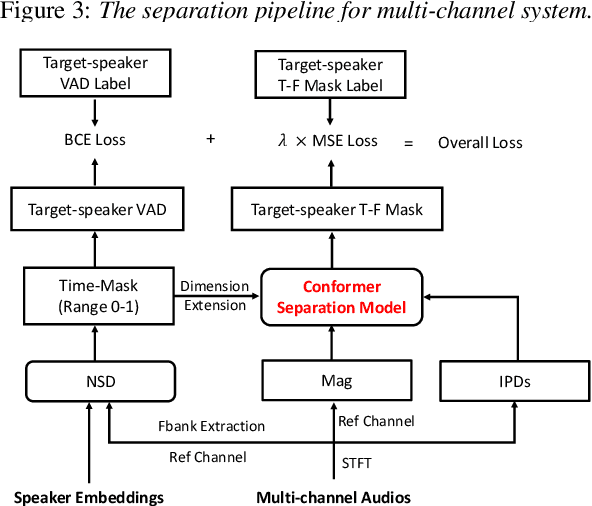
This technical report outlines our submission system for the CHiME-8 NOTSOFAR-1 Challenge. The primary difficulty of this challenge is the dataset recorded across various conference rooms, which captures real-world complexities such as high overlap rates, background noises, a variable number of speakers, and natural conversation styles. To address these issues, we optimized the system in several aspects: For front-end speech signal processing, we introduced a data-driven joint training method for diarization and separation (JDS) to enhance audio quality. Additionally, we also integrated traditional guided source separation (GSS) for multi-channel track to provide complementary information for the JDS. For back-end speech recognition, we enhanced Whisper with WavLM, ConvNeXt, and Transformer innovations, applying multi-task training and Noise KLD augmentation, to significantly advance ASR robustness and accuracy. Our system attained a Time-Constrained minimum Permutation Word Error Rate (tcpWER) of 14.265% and 22.989% on the CHiME-8 NOTSOFAR-1 Dev-set-2 multi-channel and single-channel tracks, respectively.
The USTC-NERCSLIP Systems for the CHiME-7 DASR Challenge
Aug 28, 2023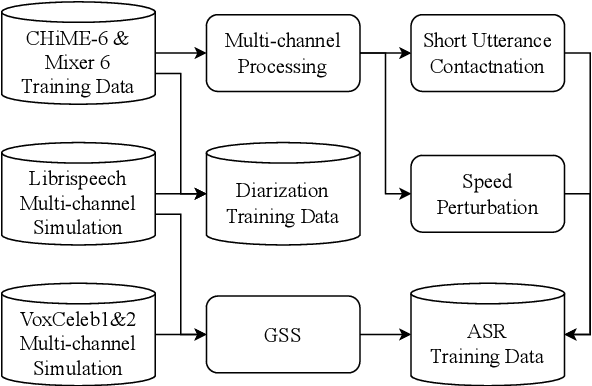
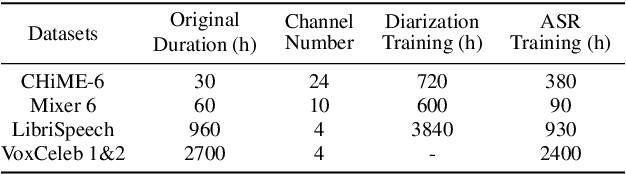
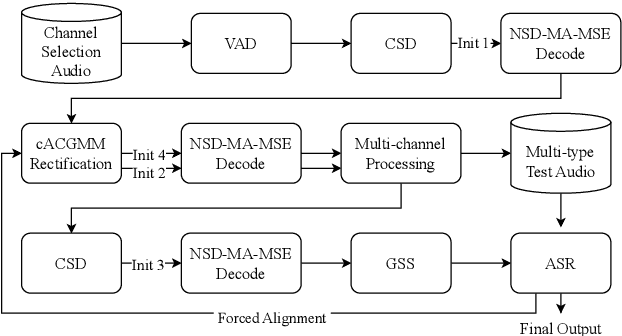
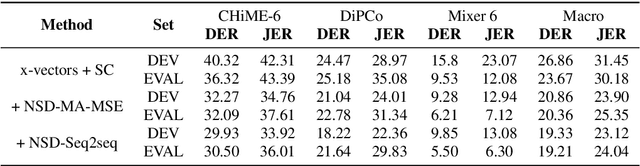
This technical report details our submission system to the CHiME-7 DASR Challenge, which focuses on speaker diarization and speech recognition under complex multi-speaker settings. Additionally, it also evaluates the efficiency of systems in handling diverse array devices. To address these issues, we implemented an end-to-end speaker diarization system and introduced a rectification strategy based on multi-channel spatial information. This approach significantly diminished the word error rates (WER). In terms of recognition, we utilized publicly available pre-trained models as the foundational models to train our end-to-end speech recognition models. Our system attained a macro-averaged diarization-attributed WER (DA-WER) of 22.4\% on the CHiME-7 development set, which signifies a relative improvement of 52.5\% over the official baseline system.
Reducing the gap between streaming and non-streaming Transducer-based ASR by adaptive two-stage knowledge distillation
Jun 27, 2023Transducer is one of the mainstream frameworks for streaming speech recognition. There is a performance gap between the streaming and non-streaming transducer models due to limited context. To reduce this gap, an effective way is to ensure that their hidden and output distributions are consistent, which can be achieved by hierarchical knowledge distillation. However, it is difficult to ensure the distribution consistency simultaneously because the learning of the output distribution depends on the hidden one. In this paper, we propose an adaptive two-stage knowledge distillation method consisting of hidden layer learning and output layer learning. In the former stage, we learn hidden representation with full context by applying mean square error loss function. In the latter stage, we design a power transformation based adaptive smoothness method to learn stable output distribution. It achieved 19\% relative reduction in word error rate, and a faster response for the first token compared with the original streaming model in LibriSpeech corpus.
Progressive Multi-Scale Self-Supervised Learning for Speech Recognition
Dec 07, 2022



Self-supervised learning (SSL) models have achieved considerable improvements in automatic speech recognition (ASR). In addition, ASR performance could be further improved if the model is dedicated to audio content information learning theoretically. To this end, we propose a progressive multi-scale self-supervised learning (PMS-SSL) method, which uses fine-grained target sets to compute SSL loss at top layer while uses coarse-grained target sets at intermediate layers. Furthermore, PMS-SSL introduces multi-scale structure into multi-head self-attention for better speech representation, which restricts the attention area into a large scope at higher layers while restricts the attention area into a small scope at lower layers. Experiments on Librispeech dataset indicate the effectiveness of our proposed method. Compared with HuBERT, PMS-SSL achieves 13.7% / 12.7% relative WER reduction on test other evaluation subsets respectively when fine-tuned on 10hours / 100hours subsets.
Improved Speech Pre-Training with Supervision-Enhanced Acoustic Unit
Dec 07, 2022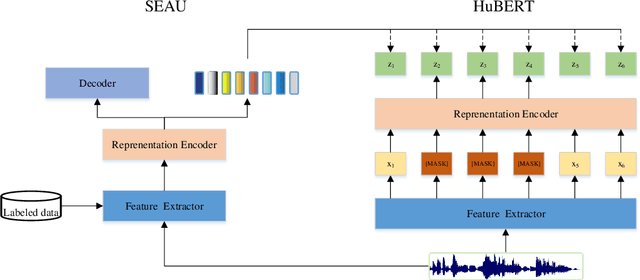
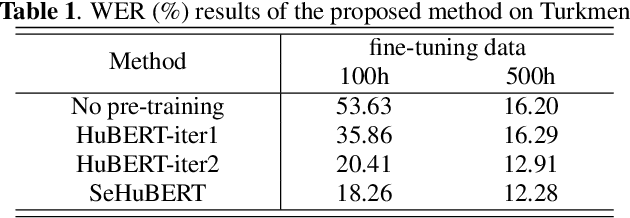


Speech pre-training has shown great success in learning useful and general latent representations from large-scale unlabeled data. Based on a well-designed self-supervised learning pattern, pre-trained models can be used to serve lots of downstream speech tasks such as automatic speech recognition. In order to take full advantage of the labed data in low resource task, we present an improved pre-training method by introducing a supervision-enhanced acoustic unit (SEAU) pattern to intensify the expression of comtext information and ruduce the training cost. Encoder representations extracted from the SEAU pattern are used to generate more representative target units for HuBERT pre-training process. The proposed method, named SeHuBERT, achieves a relative word error rate reductions of 10.5% and 4.9% comared with the standard HuBERT on Turkmen speech recognition task with 500 hours and 100 hours fine-tuning data respectively. Extended to more languages and more data, SeHuBERT can aslo achieve a relative word error rate reductions of approximately 10% at half of the training cost compared with HuBERT.