 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Speech Pre-Training with Supervision-Enhanced Acoustic Unit
Paper and Code
Dec 07, 2022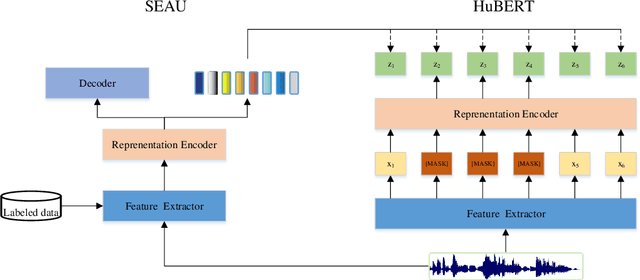
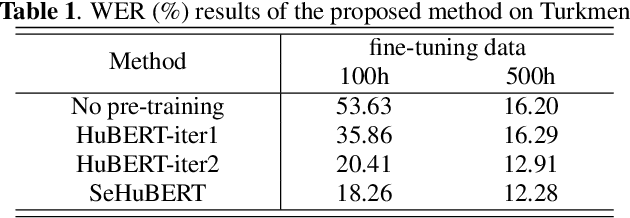


Speech pre-training has shown great success in learning useful and general latent representations from large-scale unlabeled data. Based on a well-designed self-supervised learning pattern, pre-trained models can be used to serve lots of downstream speech tasks such as automatic speech recognition. In order to take full advantage of the labed data in low resource task, we present an improved pre-training method by introducing a supervision-enhanced acoustic unit (SEAU) pattern to intensify the expression of comtext information and ruduce the training cost. Encoder representations extracted from the SEAU pattern are used to generate more representative target units for HuBERT pre-training process. The proposed method, named SeHuBERT, achieves a relative word error rate reductions of 10.5% and 4.9% comared with the standard HuBERT on Turkmen speech recognition task with 500 hours and 100 hours fine-tuning data respectively. Extended to more languages and more data, SeHuBERT can aslo achieve a relative word error rate reductions of approximately 10% at half of the training cost compared with HuBERT.