 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Self-Supervised Multilingual Speech Representation Learning Combined with Auxiliary Language Information
Paper and Code
Dec 07, 2022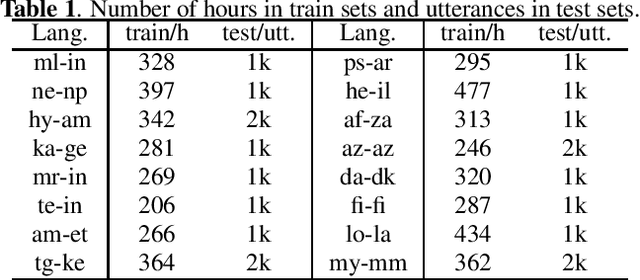

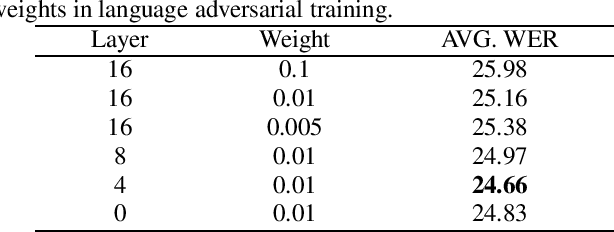

Multilingual end-to-end models have shown great improvement over monolingual systems. With the development of pre-training methods on speech, self-supervised multilingual speech representation learning like XLSR has shown success in improving the performance of multilingual automatic speech recognition (ASR). However, similar to the supervised learning, multilingual pre-training may also suffer from language interference and further affect the application of multilingual system. In this paper, we introduce several techniques for improving self-supervised multilingual pre-training by leveraging auxiliary language information, including the language adversarial training, language embedding and language adaptive training during the pre-training stage. We conduct experiments on a multilingual ASR task consisting of 16 languages. Our experimental results demonstrate 14.3% relative gain over the standard XLSR model, and 19.8% relative gain over the no pre-training multilingual model.